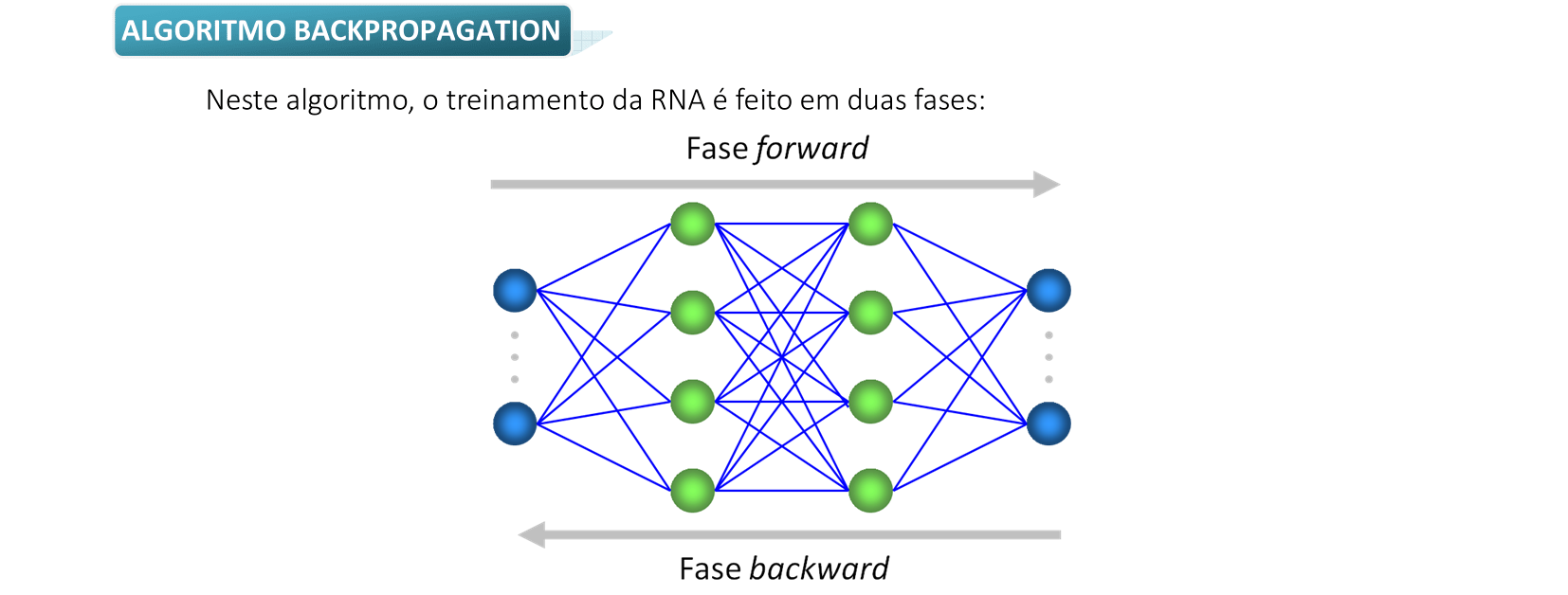
Algoritmos, exemplos e aplicações

Esta página contém os algoritmos e exemplos das técnicas mostradas na disciplina Metaheurísticas e Aplicações. Além disso, são mostradas as aplicações destas técnicas em várias áreas da Pesquisa Operacional.
A apostila está disponível no link:
Redes Neurais Artificiais
1. Perceptron
Material das páginas 1 até 16.







📃 Algoritmo comentado
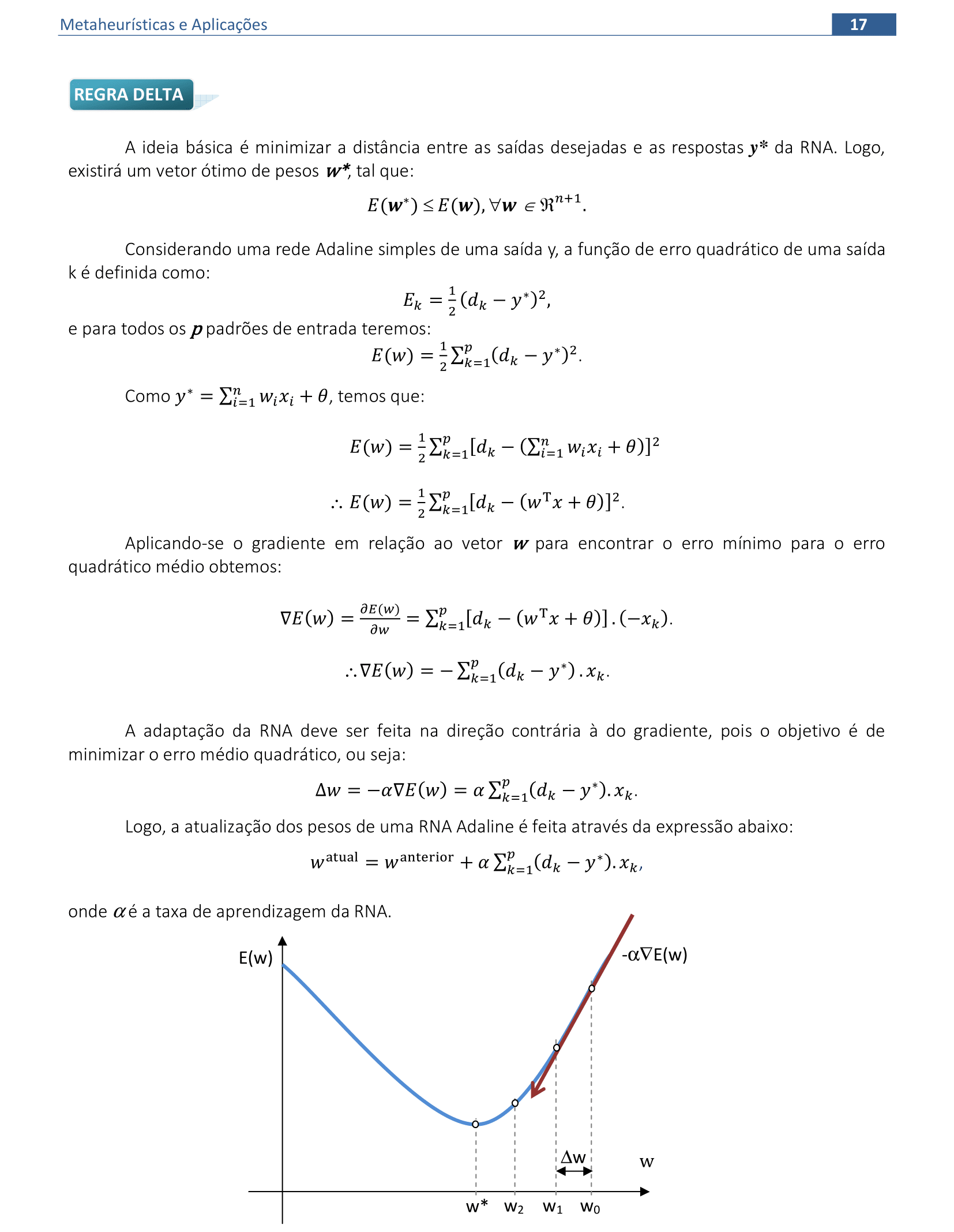
0. Inicializar os pesos, o bias e a taxa de aprendizado: w = 0, θ = 0, α = 1
1. Enquanto o critério de parada não for satisfeito, execute os passos 2-6:
2. Para cada par de dados de treinamento (x,d), execute os passos 3-5:
3. Calcule y* = θ + ∑ixiwi
4. Se y* > δ, então y = 1
Se -δ ≤ y* ≤ δ, então y = 0
Se y* < -δ, então y = -1
5. Atualize os pesos e a tendência:
Se y ≠ d, faça
wiatual = wianterior + αdxi e θatual = θanterior + αd
Caso contrário
wiatual = wianterior e θatual = θanterior
6. Teste a condição de parada.


📃 Resolução: 1ª e 2ª iterações
Vamos acompanhar os cálculos e as interpretações geométricas das 2 primeiras iterações deste exercício da Rede Neural Perceptron.
-
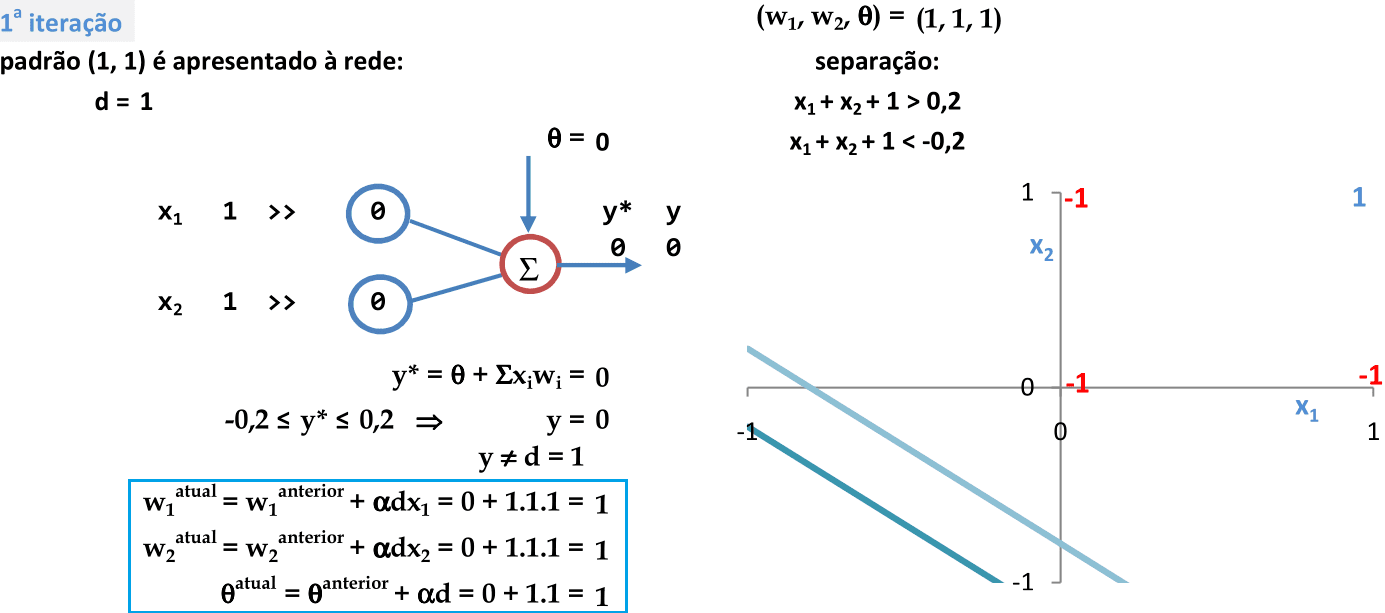
Apresentação do primeiro padrão para a rede (x1, x2) = (1, 1). Como y = θ + x1w1 + x2w2 = 0 + 1.0 + 1.0 = 0 ≠ d = 1, então os pesos são atualizados (passo 5 do algoritmo). -

Os coeficientes w1, w2 e θ definem as equações das retas usadas para a classificação. O parâmetro δ cria uma região de indefinição para a classificação. -
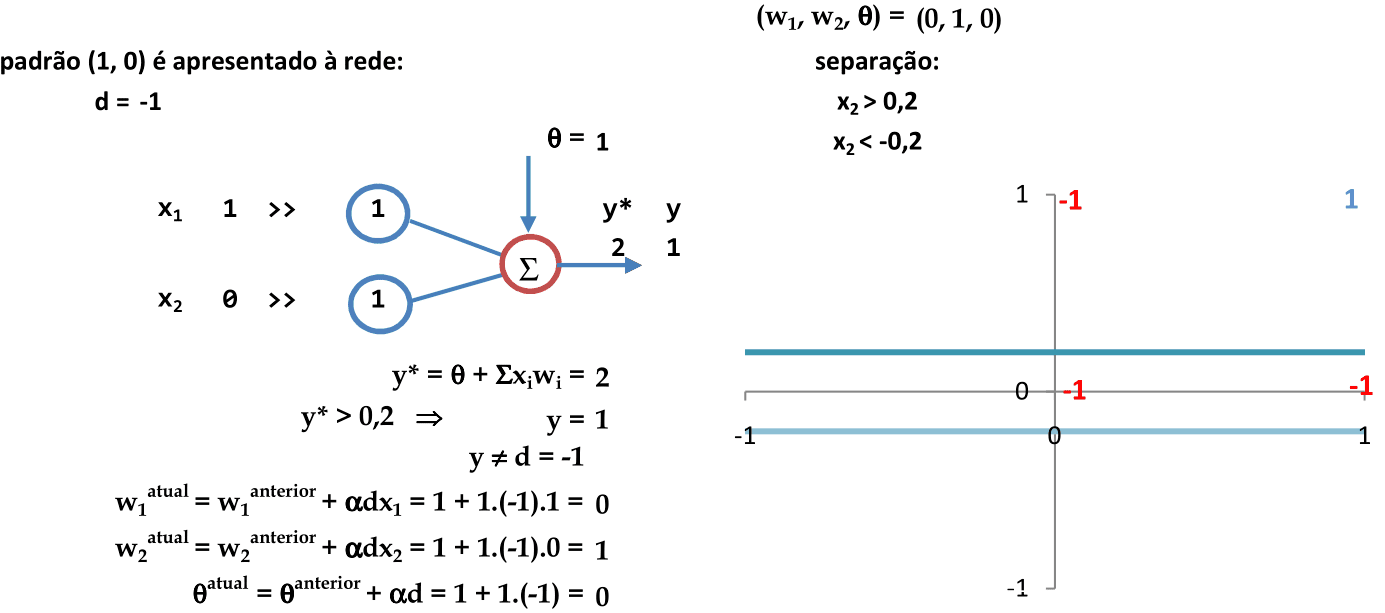
Apresentação do segundo padrão para a rede (1, 0). Como y = θ + x1w1 + x2w2 = 1 + 1.1 + 0.1 = 2 ≠ d = -1, então os pesos são atualizados. Note que as equações definidas com os coeficientes w1, w2 e θ ainda não classificam corretamente todos dos padrões. -
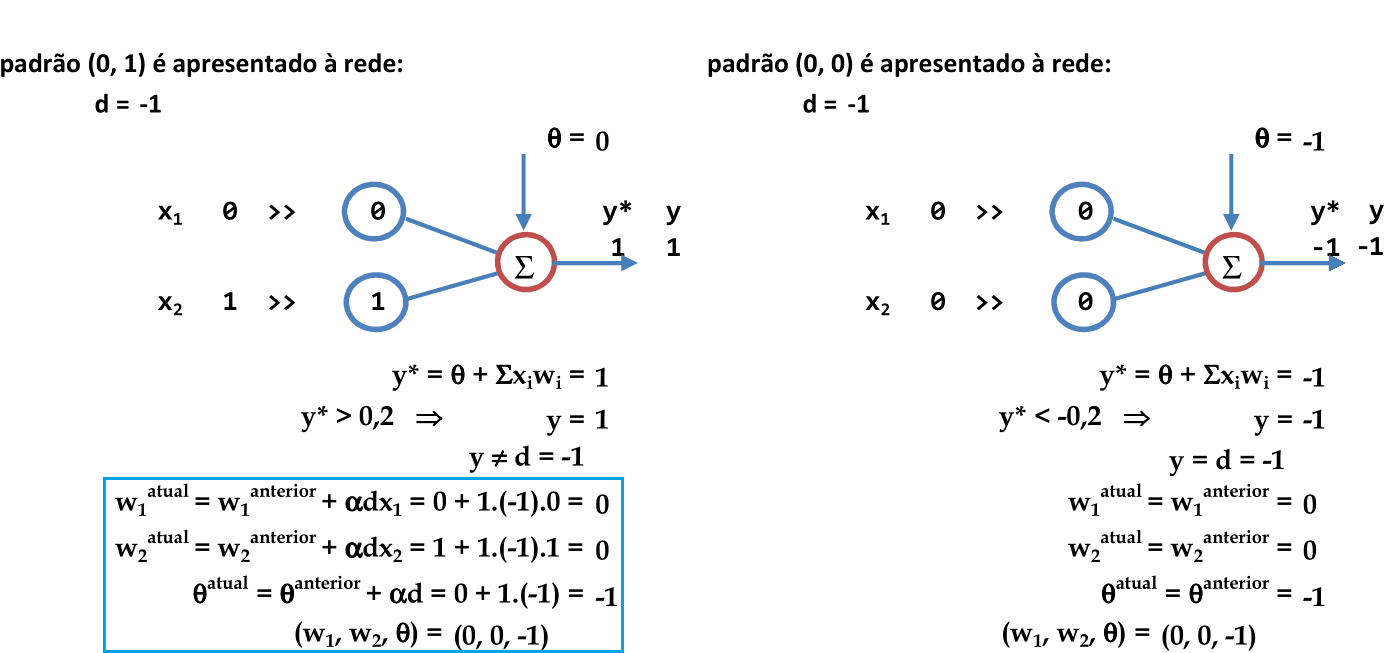
Apresentação do terceiro padrão para a rede (0, 1). Como y ≠ d, então os pesos são atualizados. Como os coeficientes das variáveis x1 e x2 ficaram nulos, não temos a interpretação geométrica nesta apresentação de padrões. -
Apresentação do último padrão para a rede (0, 0). Como y = d, então os pesos são mantidos. Usando esta combinação de pesos, podemos calcular o erro da primeira iteração. -

Usamos a combinação de pesos (w1 = 0, w2 = 0, θ = -1) da última apresentação de padrões para calcular o erro. Apenas o primeiro padrão está classificado incorretamente: logo, o erro quantitativo nesta primeira iteração é de 25%. -

Recomeçamos a apresentação de cada padrão para a rede na próxima iteração. O primeiro padrão (1, 1) é apresentado à rede, com a combinação de parâmetros (0, 0, 1). Como y ≠ d, então os pesos são atualizados. Note que as equações definidas com os coeficientes w1, w2 e θ ainda não classificam corretamente todos dos padrões. -

Apresentação do segundo padrão para a rede (1, 0). Como y ≠ d, então os pesos são atualizados. As equações definidas com os coeficientes w1, w2 e θ ainda não classificam corretamente todos dos padrões. -
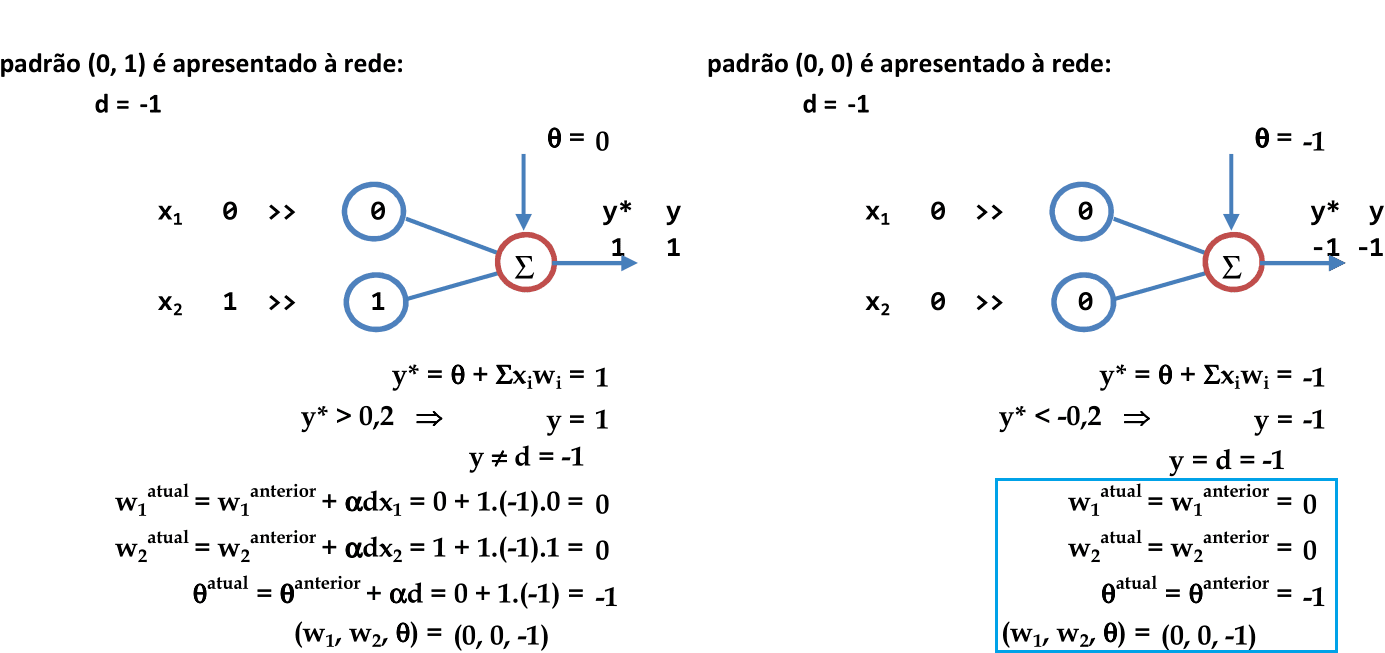
Apresentação do terceiro padrão para a rede (0, 1). Como y ≠ d, então os pesos são atualizados. -
Apresentação do último padrão para a rede (0, 0). Como y = d, então os pesos são mantidos. Usando esta combinação de pesos, podemos calcular o erro da segunda iteração. -

Usamos a combinação de pesos (w1 = 0, w2 = 0, θ = -2) da última apresentação de padrões para calcular o erro. Apenas o primeiro padrão está classificado incorretamente: logo, o erro quantitativo da segunda iteração é de 25%.
📃 Resolução: 3ª ~ 9ª iterações
Vamos acompanhar os resultados e as interpretações geométricas das próximas 7 iterações deste exercício da Rede Neural Perceptron.
-
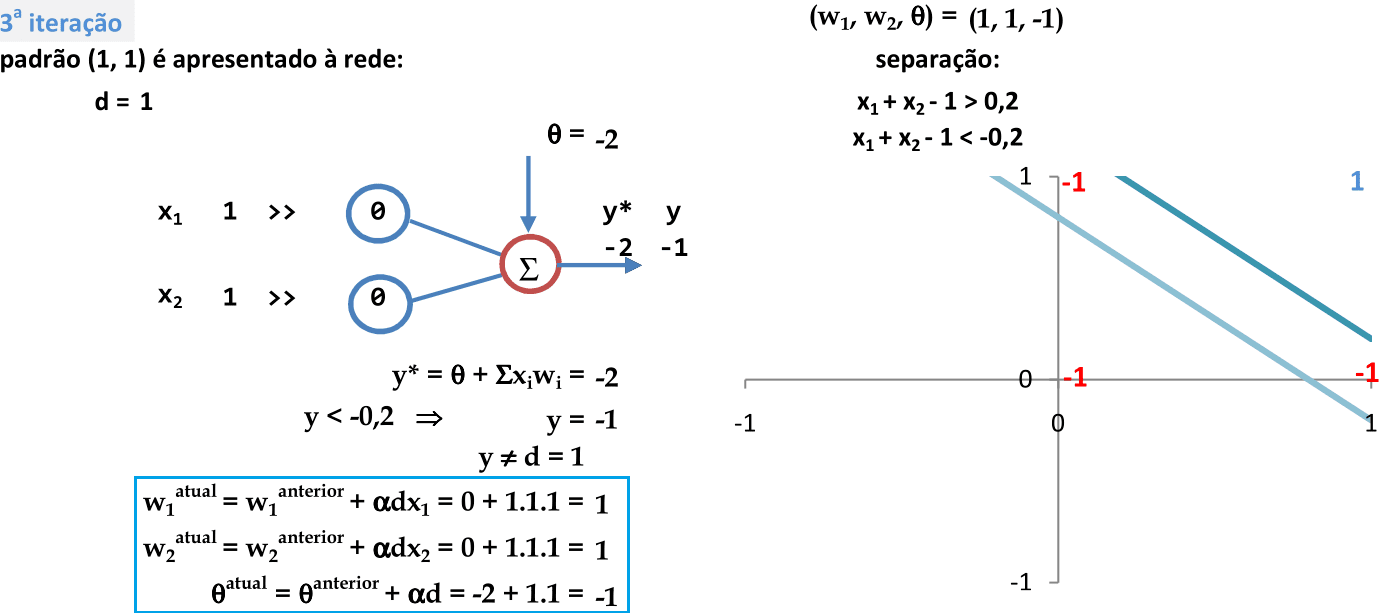
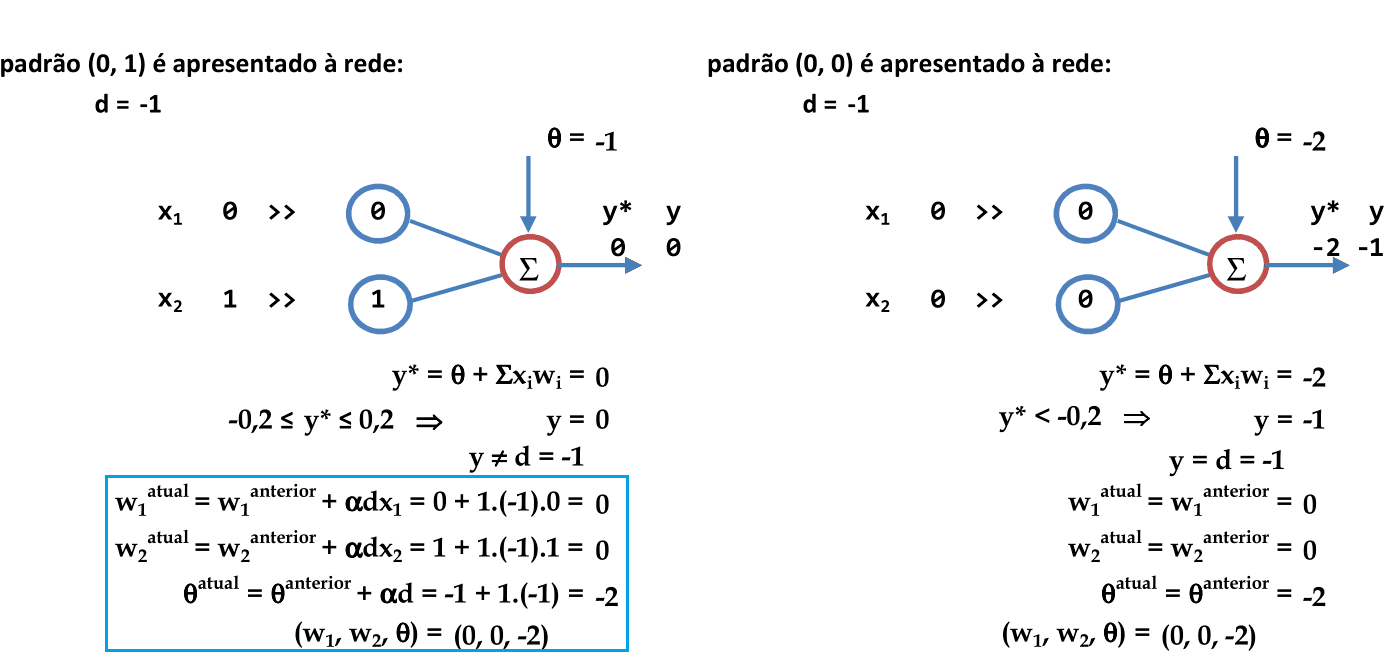
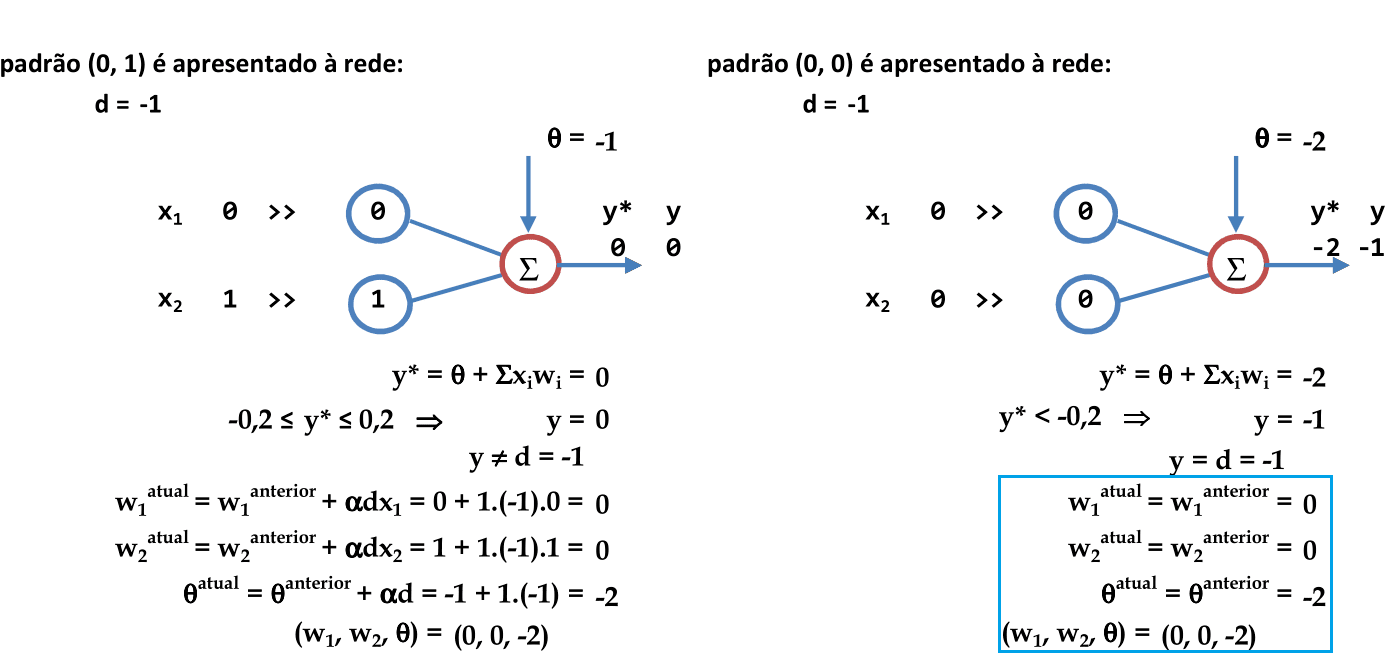
Recomeçamos a apresentação de cada padrão para a rede na próxima iteração. O primeiro padrão (1, 1) é apresentado à rede, com a combinação de parâmetros (0, 0, -2). Como y ≠ d, então os pesos são atualizados. -
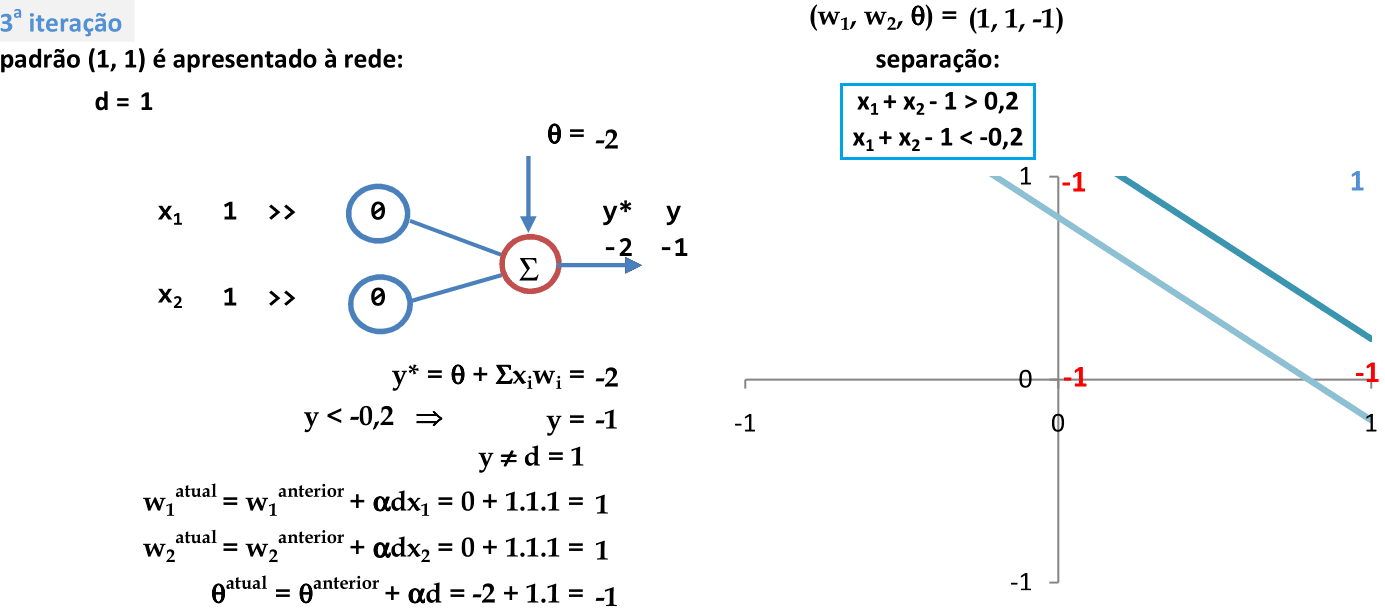
Os coeficientes w1, w2 e θ definem as equações das retas usadas para a classificação. Note que temos 2 padrões classificados corretamente e os outros 2 na região de indefinição. -
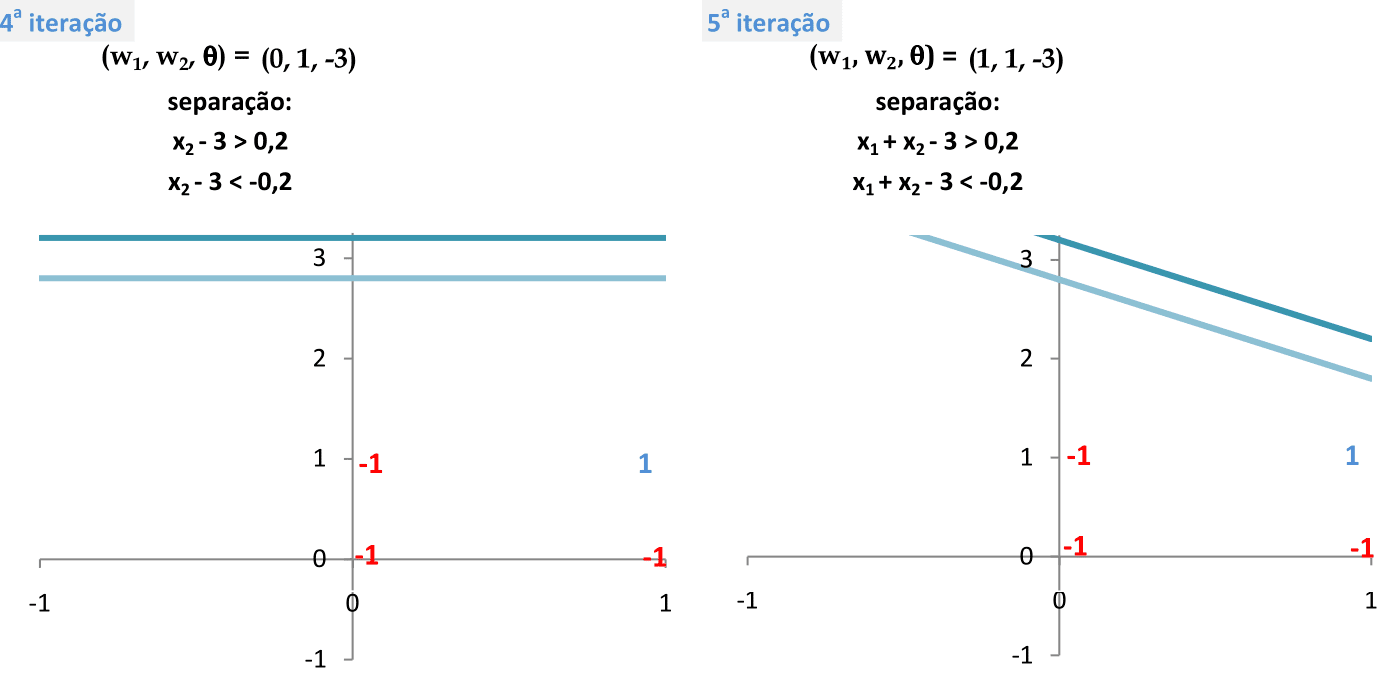
Fazendo os cálculos da mesma forma mostrada nas duas primeiras iterações, temos as classificações da quarta e da quinta iteração. Nestes casos, 3 padrões estão classificados corretamente. -

Fazendo os cálculos da mesma forma mostrada nas duas primeiras iterações, temos as classificações da sexta e da sétima iteração. Nestes casos, 3 padrões estão classificados corretamente. -

Fazendo os cálculos da mesma forma mostrada nas duas primeiras iterações, temos as classificações da oitava e da nona iteração. Os padrões ficam separados corretamente com a combinação de pesos da nona iteração. -

Usamos a combinação de pesos (w1 = 2, w2 = 3, θ = -4) da última apresentação de padrões para calcular o erro. Todos os padrões estão classificados corretamente. Logo, podemos finalizar o processo de aprendizagem desta Rede Neural.
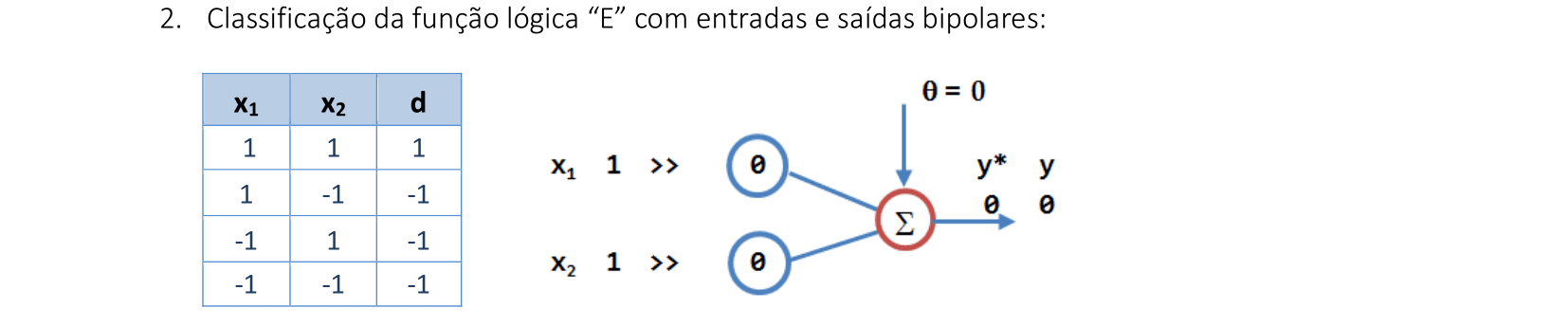
📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício da Rede Neural Perceptron. Vamos usar entradas e saídas bipolares.
-
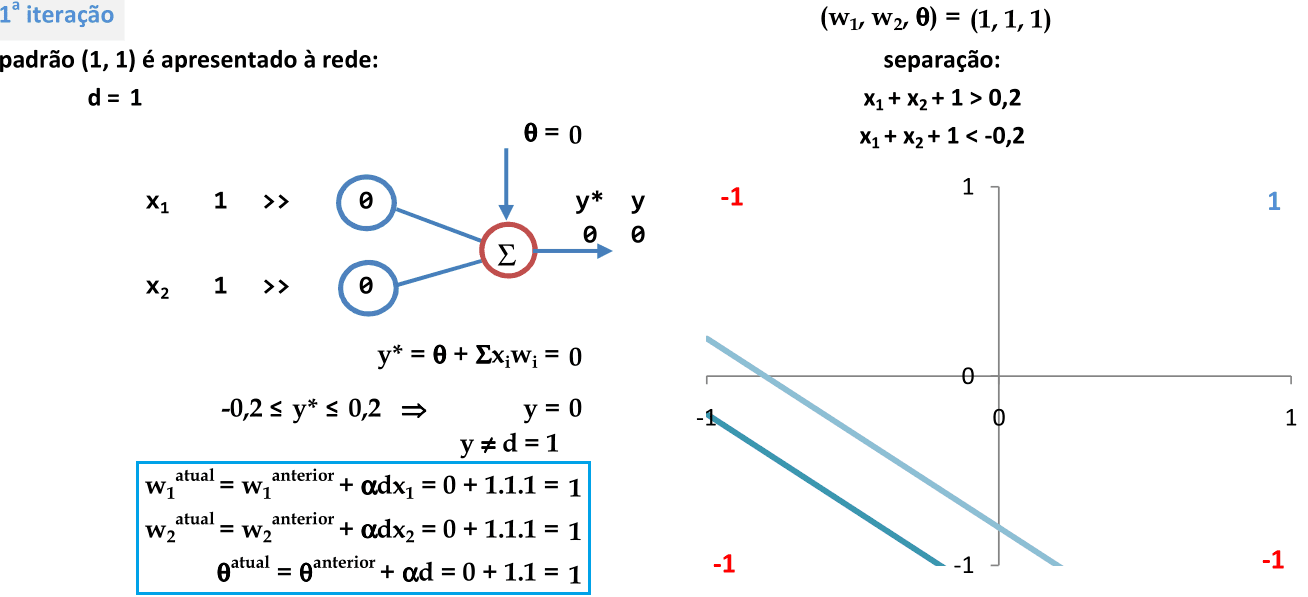
O primeiro padrão (1, 1) é apresentado à rede. Como y ≠ d, então os pesos são atualizados. -

Usando os coeficientes de w1, w2 e θ que definem as equações das retas usadas para a classificação, temos apenas 1 padrão classificado corretamente. -
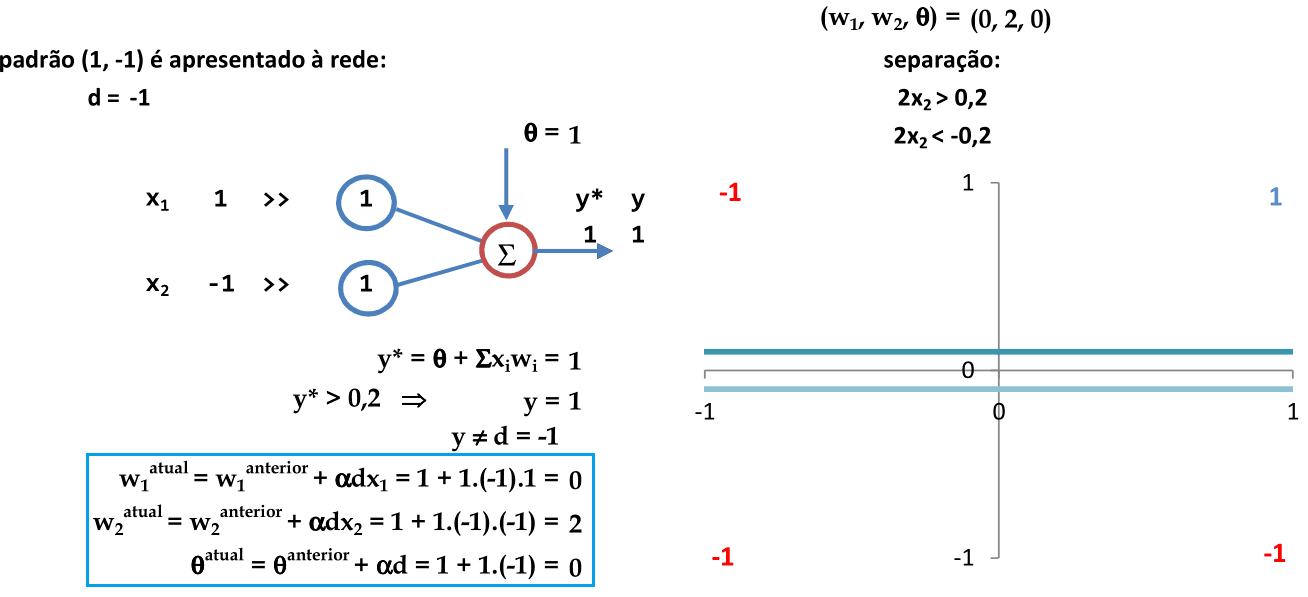
O segundo padrão (1, -1) é apresentado à rede. Como y ≠ d, então os pesos são atualizados. -
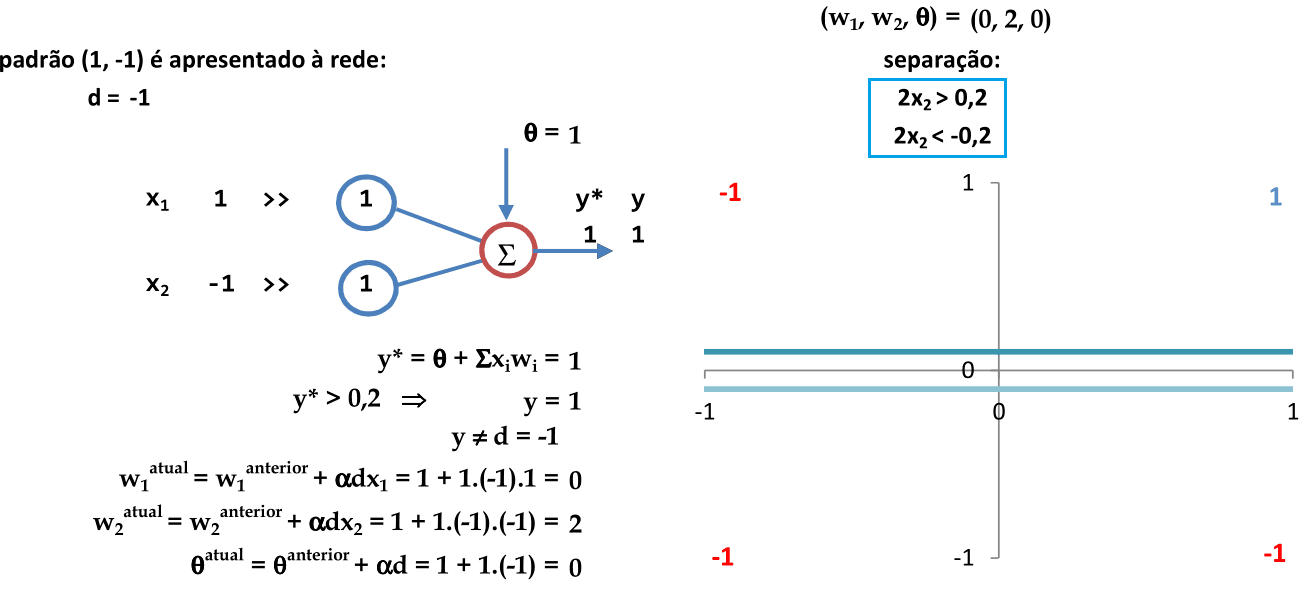
Usando os coeficientes de w1, w2 e θ que definem as equações das retas usadas para a classificação, temos 2 padrões classificados corretamente. -

O terceiro padrão (-1, 1) é apresentado à rede. Como y ≠ d, então os pesos são atualizados. Na apresentação do último padrão, temos que y = d e os valores dos pesos são mantidos. -

Usamos a combinação de pesos (w1 = 1, w2 = 1, θ = -1) da última apresentação de padrões para calcular o erro. Todos os padrões estão classificados corretamente. Logo, podemos finalizar o processo de aprendizagem desta Rede Neural.
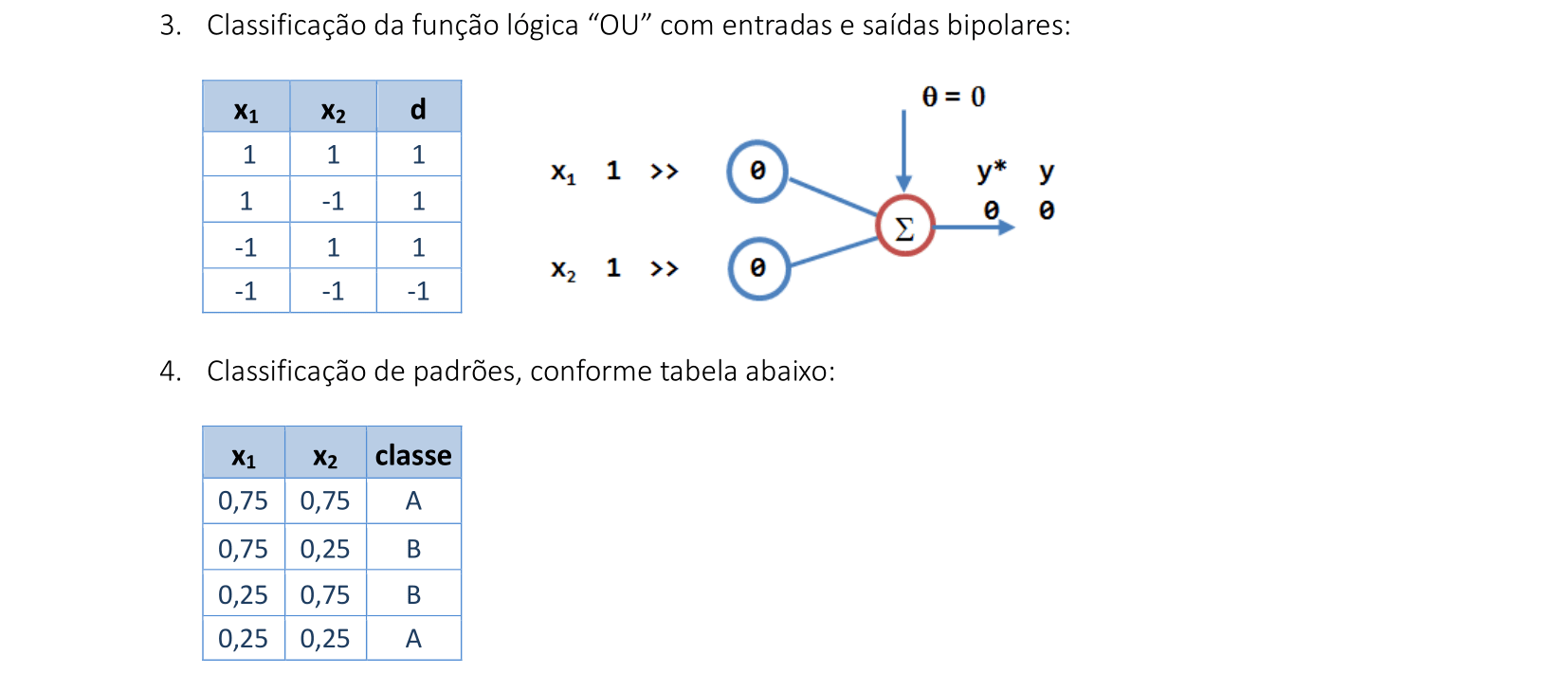



📃 Algoritmo comentado
0. Inicializar os pesos, o bias e a taxa de aprendizado: w = 0, wbolso = 0, θ = 0, α = 1
1. Enquanto o critério de parada não for satisfeito, execute os passos 2-7:
2. Para cada par de dados de treinamento (x,d), execute os passos 3-5:
3. Calcule y* = θ + ∑ixiwi
4. Se y* > δ, então y = 1
Se -δ ≤ y* ≤ δ, então y = 0
Se y* < -δ, então y = -1
5. Atualize os pesos e a tendência:
Se y ≠ d, faça
wiatual = wianterior + αdxi e θatual = θanterior + αd
Caso contrário
wiatual = wianterior e θatual = θanterior
6. Se w classifica corretamente mais exemplos do que wbolso:
wbolso = w; grave o número de exemplos corretos
7. Teste a condição de parada.


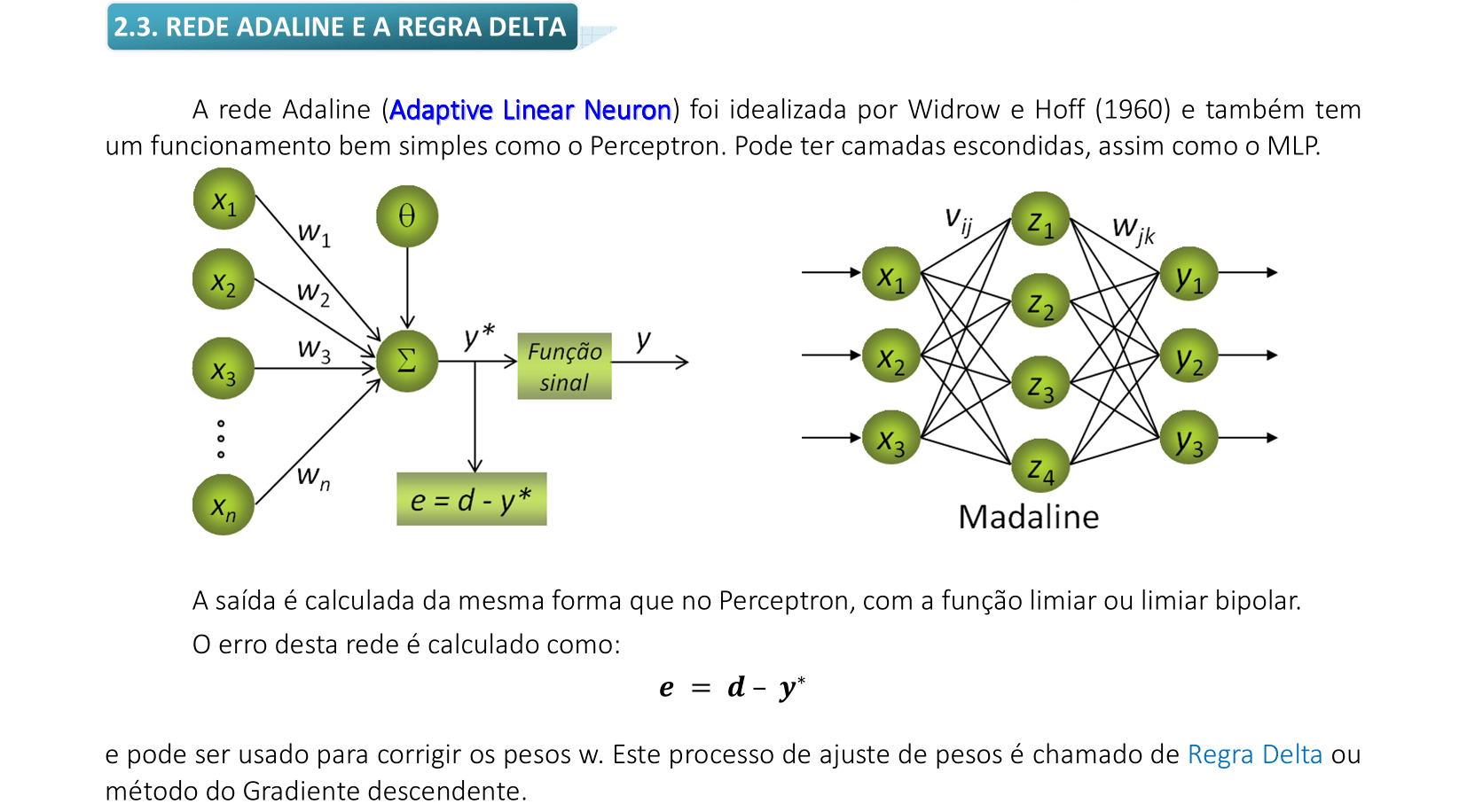
2. Adaline e Multi Layer Perceptron (MLP)
Material das páginas 16 até 28.

📃 Algoritmo comentado
0. Inicializar os pesos (w = rnd), a tendência (θ = 0)
e a taxa de aprendizagem 0 < α < 1 (convergência fica muito lenta quando a taxa é muito
próxima de zero; e a convergência não é garantida para valores muito próximos de 1).
1. Enquanto o critério de parada não for satisfeito, execute os passos 2-5:
2. Para cada par de dados para treinamento (x,d), execute os passos 3-4:
3. Faça y* = θ + ∑ixiwi
4. Atualize os pesos e a tendência:
wiatual = wianterior + α(d – y*)xi
θatual = θanterior + α(d – y*)
se y* ≥ 0, y = 1; caso contrário, y = 0 (ou y = -1 para bipolar)
5. Teste a condição de parada.
6. Se a maior alteração de pesos não ultrapassa um limite mínimo de tolerância, pare;
caso contrário, continue.

📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício de classificação de padrões usando a Rede Neural Adaline. Vamos usar entradas e saídas bipolares.
-
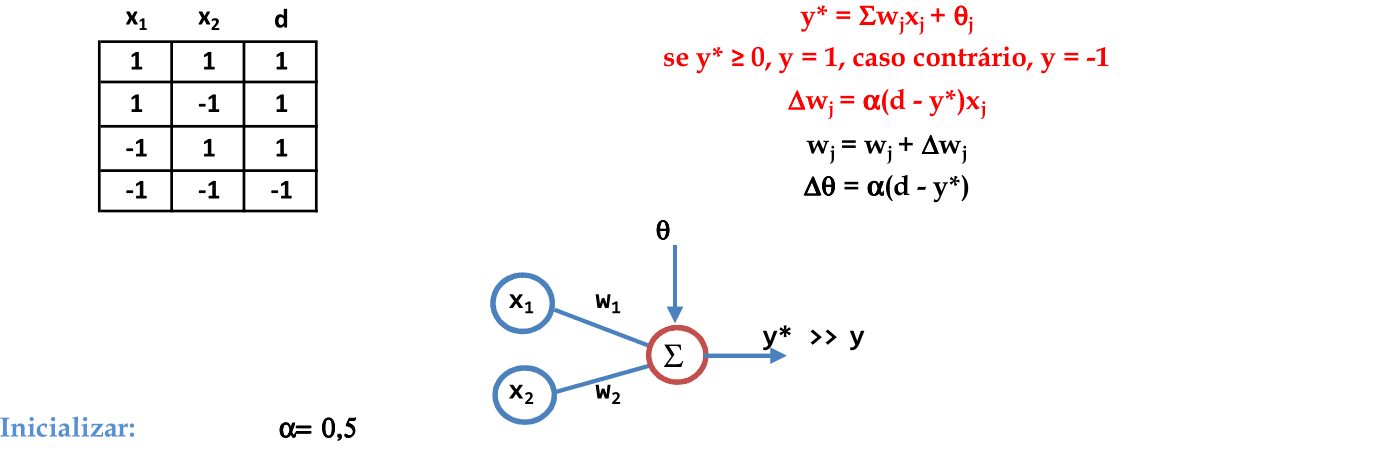
A arquitetura da Rede Neural Adaline fica análoga à arquitetura que usamos no caso do Perceptron. O resumo dos cálculos está mostrado nesta imagem. Vamos iniciar com os pesos indicados de w e θ e a taxa de aprendizagem α. -

O primeiro padrão (1, 1) é apresentado à rede, com a atualização automática dos pesos. Note que o termo Δθ é comum na atualização dos pesos w1 e w2; logo, podemos aplicar uma simplificação para estes cálculos. -

O padrão (1, -1) é apresentado à rede, com a atualização automática dos pesos. Note que a simplificação na atualização dos pesos foi aplicada neste passo para w1 e w2. -

O padrão (-1, 1) é apresentado à rede, com a atualização automática dos pesos. -

O padrão (-1, -1) é apresentado à rede, com a atualização automática dos pesos. Note que a reta com os coeficientes dos pesos classifica todos os padrões corretamente. -

Usando a função do cálculo do erro, similar à usada para deduzir a Regra Delta, temos que: E = ∑k((dk - y)2)/2 = ((1 - 1)2 + (1 - 1)2 + (1 - 1)2 + (-1 - (-1))2)/2 = 0. O erro quantitativo também fica nulo, logo, podemos finalizar a aprendizagem desta Rede Neural.


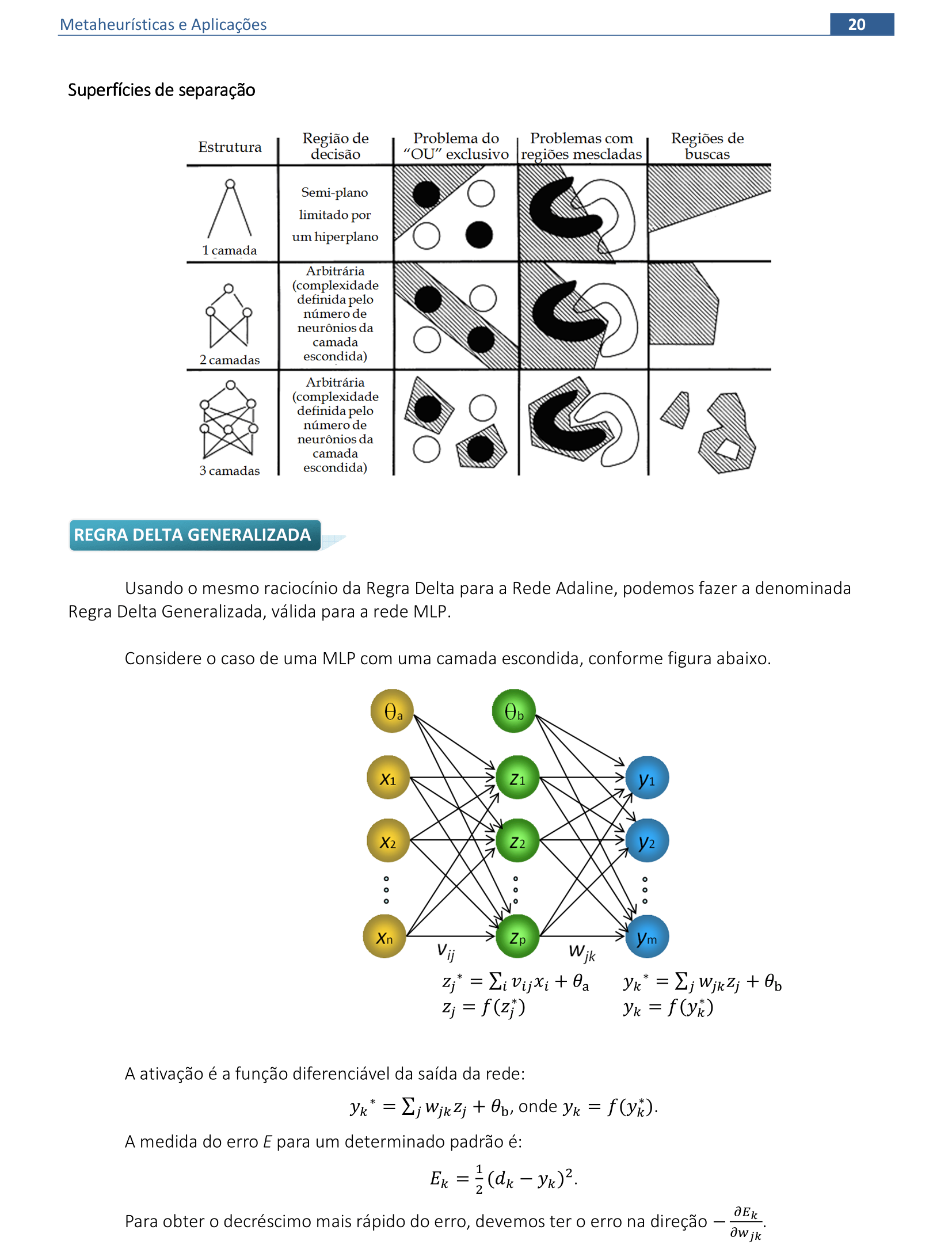

📃 Resolução
Neste caso, o parâmetro β da função sigmoidal é igual a 1.
A derivada da função yk = tanh(yk*) com parâmetro β = 1 é y'k = (1 - yk2).
Logo, a atualização de pesos w será Δwjk = α(1 - yk2)(dk - yk)zj.


📃 Resolução
As derivadas das funções yk = tanh(yk*) e zj = tanh(zj*) com parâmetro β = 1 são:
y'k = (1 - yk2) e z'j = (1 - zj2).
Logo, a atualização de pesos v será Δvij = α∑k[(dk - yk)(1 - yk2)wjk](1 - zj2)xi.

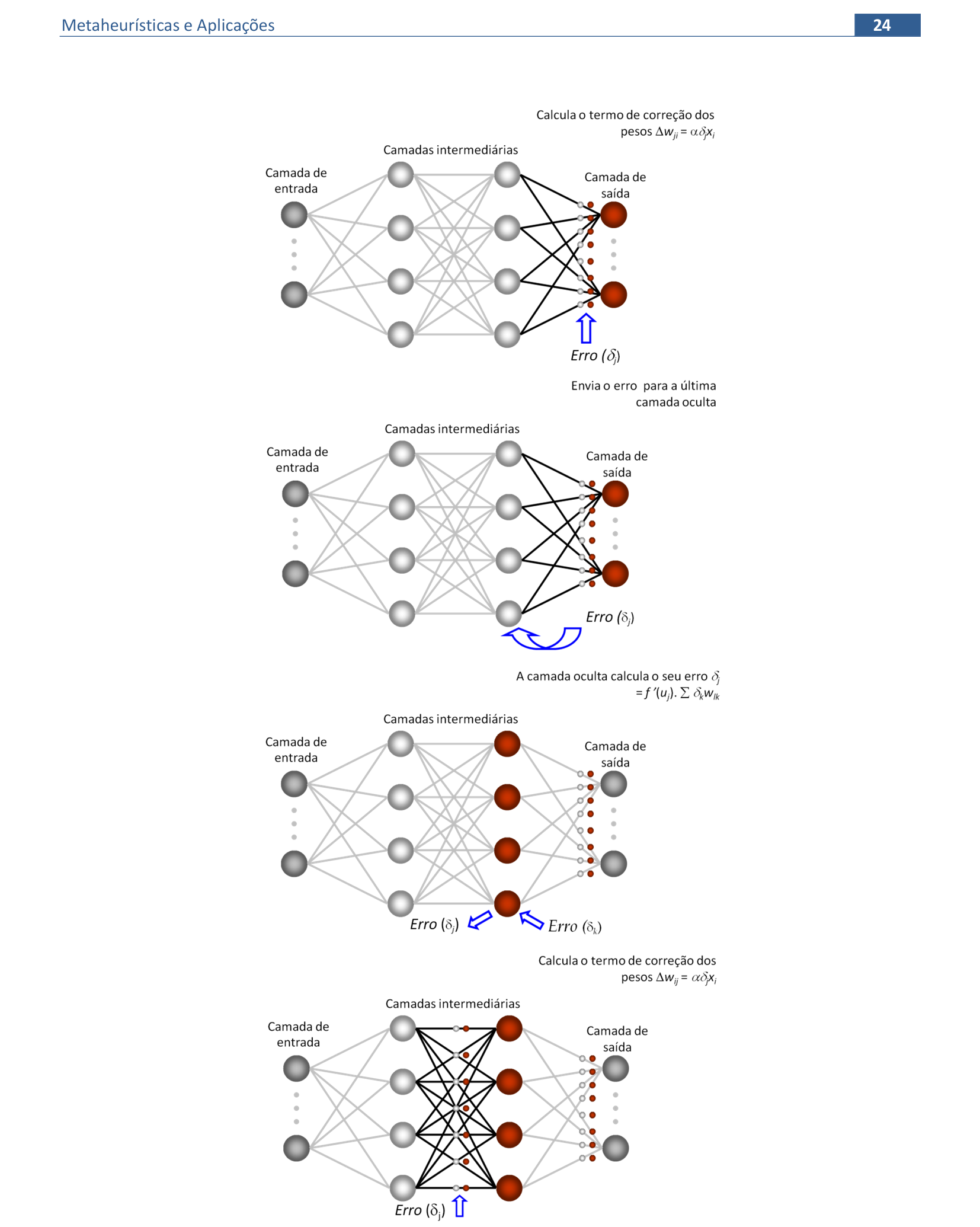
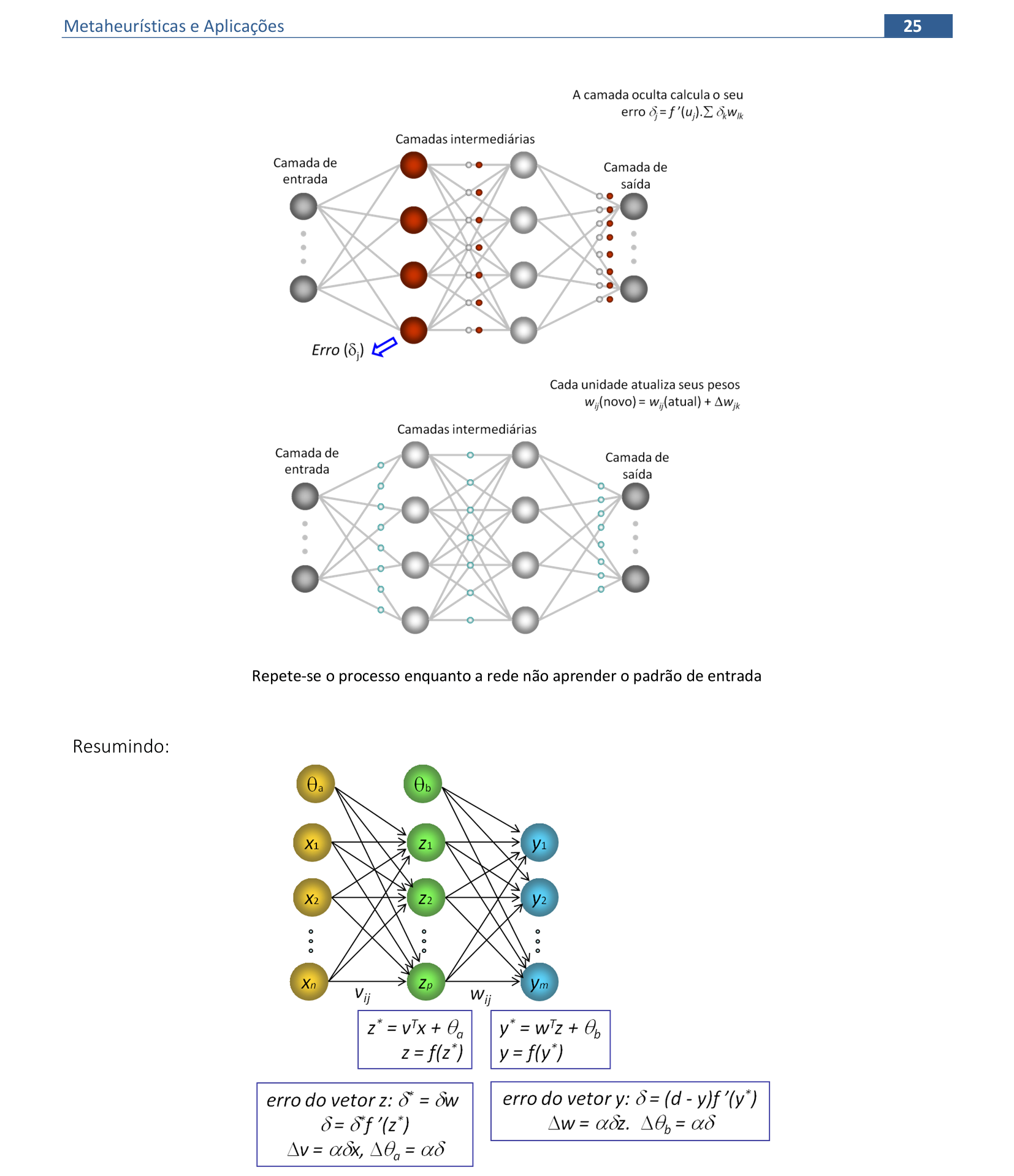
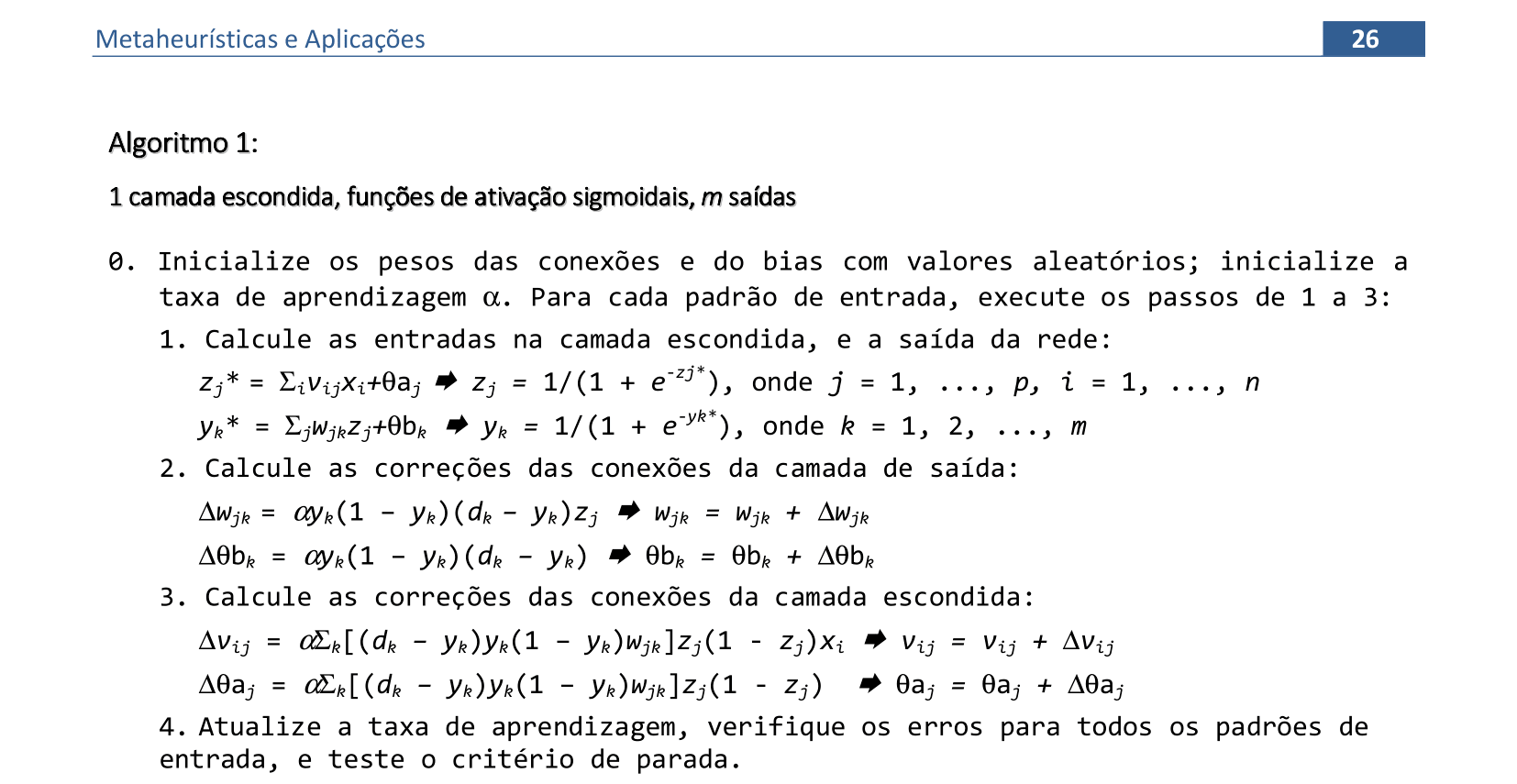
📃 Algoritmo comentado
0. Inicialize os pesos das conexões e do bias com valores aleatórios;
inicialize a taxa de aprendizagem α. Para cada padrão de entrada, execute os passos de 1 a 3:
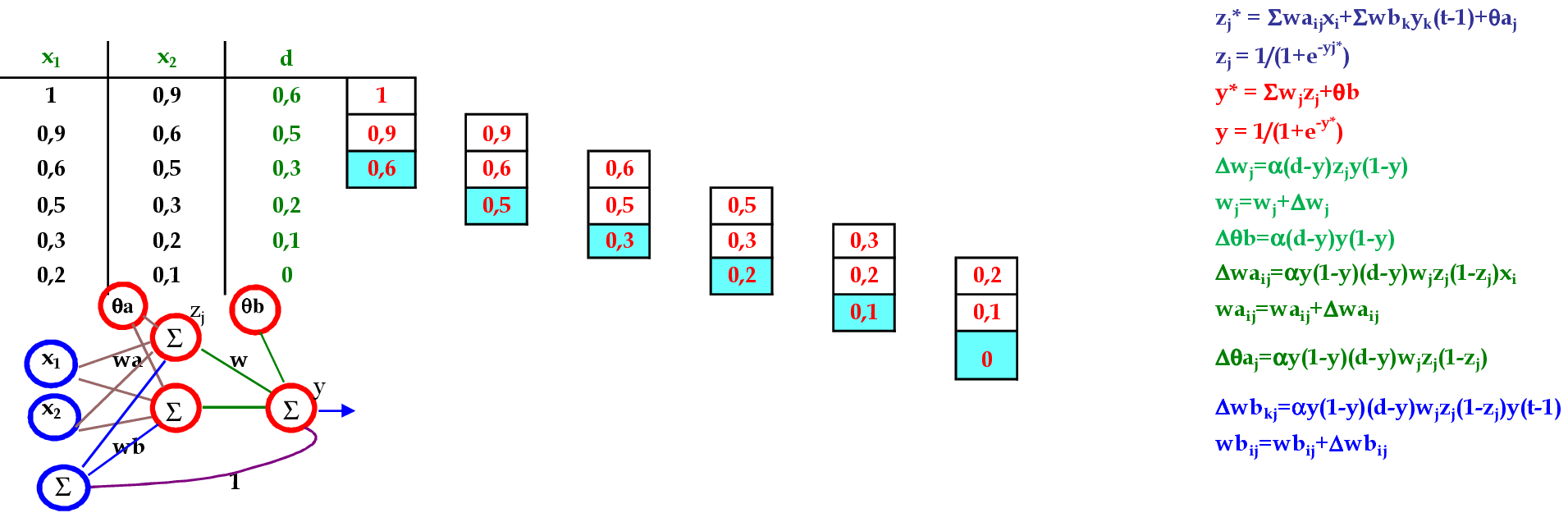
1. Calcule as entradas na camada escondida, e a saída da rede:
zj* = ∑ivijxi + θaj ⇒ zj = 1/(1 + e-zj*), onde j = 1, ..., p, i = 1, ..., n
yk* = ∑jwjkzj + θbk ⇒ yk = 1/(1 + e-yk*), onde k = 1, 2, ..., m
2. Calcule as correções das conexões da camada de saída:
△wjk = αyk(1 – yk)(dk – yk)zj ⇒ wjk = wjk + △wjk
△θbk = αyk(1 – yk)(dk – yk) ⇒ θbk = θbk + △θbk
3. Calcule as correções das conexões da camada escondida:
△vij = α∑k[(dk – yk)yk(1 – yk)wjk]zj(1 - zj)xi ⇒ vij = vij + △vij
△θaj = α∑k[(dk – yk)yk(1 – yk)wjk]zj(1 - zj) ⇒ θaj = θaj + △θaj
4. Atualize a taxa de aprendizagem, verifique os erros para todos os padrões de entrada,
e teste o critério de parada.

📃 Algoritmo comentado
0. Inicialize os pesos das conexões e do bias com valores aleatórios;
inicialize a taxa de aprendizagem α. Para cada padrão de entrada, execute os passos de 1 a 3:
1. Calcule as entradas na camada escondida, e a saída da rede:
zj* = ∑ivijxi + θaj ⇒ zj = 1/(1 + e-zj*), onde j = 1, ..., p, i = 1, ..., n
y* = ∑jwjzj + θb ⇒ y = 1/(1 + e-y*), onde k = 1, 2, ..., m
2. Calcule as correções das conexões da camada de saída:
△wj = αy(1 – y)(d – y)zj ⇒ wj = wj + △wj
△θb = αy(1 – y)(d – y) ⇒ θb = θb + △θb
3. Calcule as correções das conexões da camada escondida:
△vij = α(d – y)y(1 – y)wjzj(1 - zj)xi ⇒ vij = vij + △vij
△θaj = α(d – y)y(1 – y)wjzj(1 - zj) ⇒ θaj = θaj + △θaj
4. Atualize a taxa de aprendizagem, verifique os erros para todos os padrões de entrada,
e teste o critério de parada.


📃 Algoritmo comentado
0. Inicialize os pesos das conexões e do bias com valores aleatórios;
inicialize a taxa de aprendizagem α. Para cada padrão de entrada, execute os passos de 1 a 3:
1. Calcule as entradas na camada escondida, e a saída da rede:
zj* = ∑ivijxi + θaj ⇒ zj = tanh(zj*), onde j = 1, ..., p, i = 1, ..., n
yk* = ∑jwjkzj + θbk ⇒ yk = tanh(yk*), onde k = 1, 2, ..., m
2. Calcule as correções das conexões da camada de saída:
△wjk = α(1 – yk2)(dk – yk)zj ⇒ wjk = wjk + △wjk
△θbk = α(1 – yk2)(dk – yk) ⇒ θbk = θbk + △θbk
3. Calcule as correções das conexões da camada escondida:
△vij = α∑k[(dk – yk)(1 – yk2)wjk](1 - zj2)xi ⇒ vij = vij + △vij
△θaj = α∑k[(dk – yk)(1 – yk2)wjk](1 - zj2) ⇒ θaj = θaj + △θaj
4. Atualize a taxa de aprendizagem, verifique os erros para todos os padrões de entrada,
e teste o critério de parada.

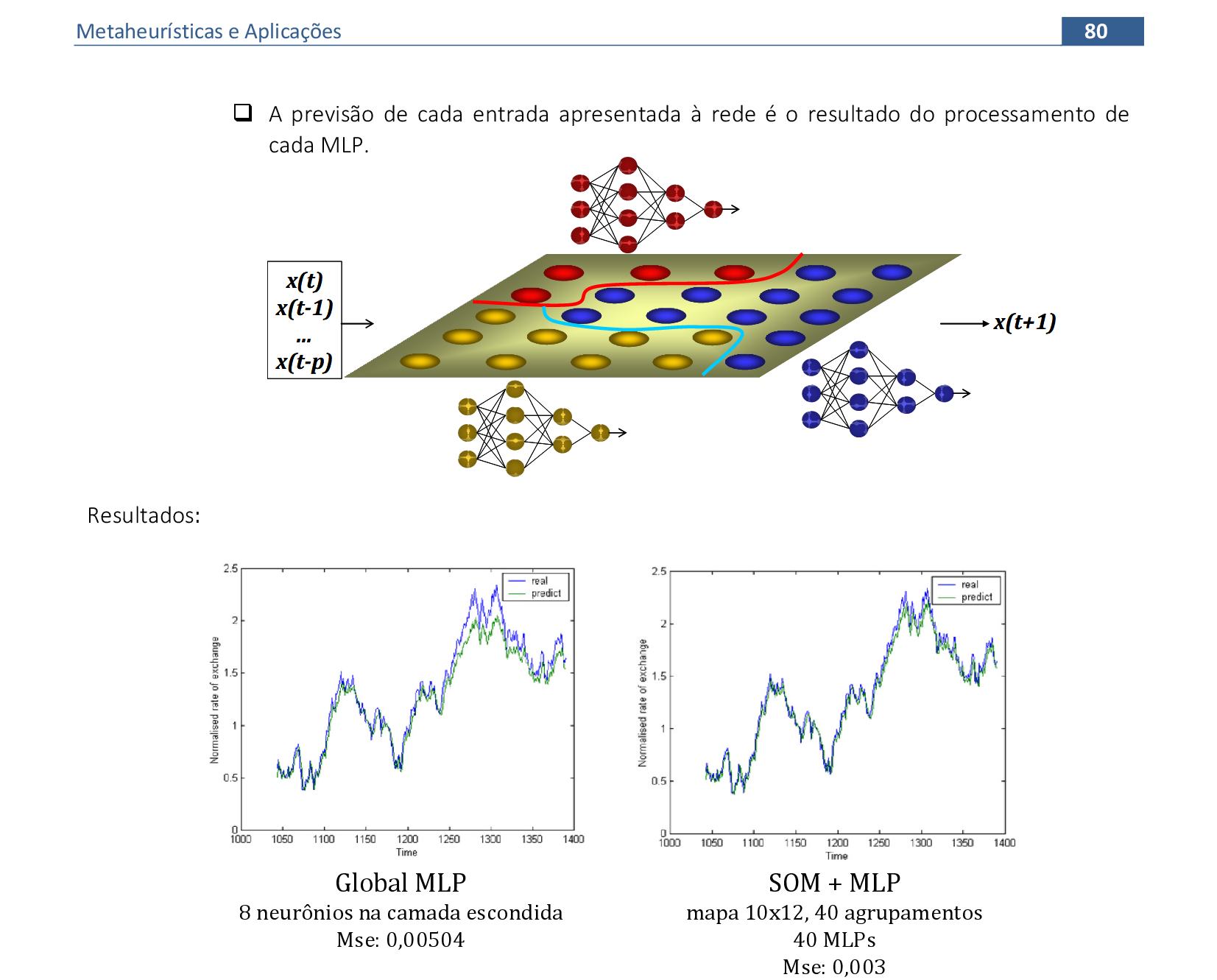
📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício de classificação de padrões com a Rede Neural Multi Layer Perceptron (MLP). Vamos usar saídas binárias para classificar os padrões de entrada em dois conjuntos: A e B.
-

A arquitetura da Rede Neural deste primeiro exercício fica análoga à arquitetura que usamos nos exemplos Perceptron e Adaline. O resumo dos cálculos está mostrado nesta imagem. Vamos iniciar com os pesos indicados de w e θ e a taxa de aprendizagem α = 1. -

O primeiro padrão (0, 2) é apresentado à rede. Calculamos a saída y* e aplicamos a função de ativação sigmóide (pois a saída está no intervalo [0,1]). Note que podemos simplificar a atualização dos pesos, pois o termo Δθ é comum nas atualizações dos pesos w1 e w2. -

O padrão (1, 2) é apresentado à rede, com a atualização automática dos pesos. Usamos a simplificação de atualização dos pesos para as próximas apresentações de padrões de entrada. -

O padrão (1, 3) é apresentado à rede, com a atualização automática dos pesos. Este é o último padrão de entrada do conjunto com d = 1. -

O padrão (2, 1) é apresentado à rede, com a atualização automática dos pesos. Este é o primeiro padrão de entrada do conjunto com d = 0. -
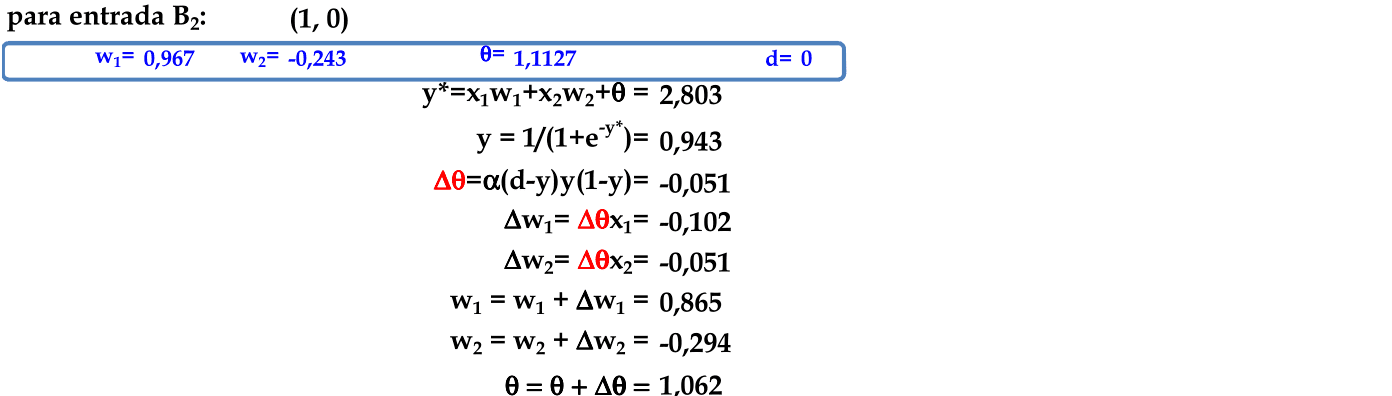
O padrão (1, 0) é apresentado à rede, com a atualização automática dos pesos. Este é o último padrão de entrada nesta rede, finalizando a primeira iteração. -
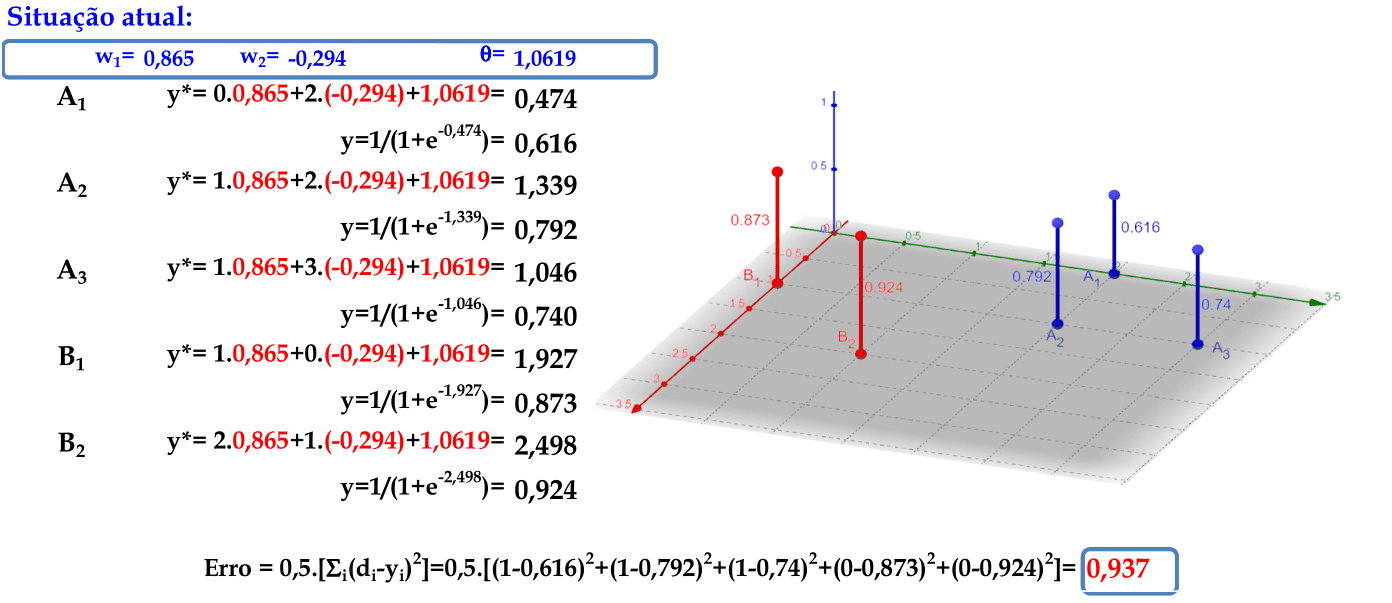
Calculamos as saídas y* e y de cada padrão de entrada para encontrarmos o erro desta iteração. A função do cálculo do erro é a mesma que foi usada para deduzir a Regra Delta: E = ∑k((dk - y)2)/2 = 0,937. A interpretação geométrica da MLP pode ser melhor compreendida usando o gráfico em 3 dimensões. -

Na segunda iteração, precisamos atualizar a taxa de aprendizagem: α = α.0,95. O primeiro padrão (0, 2) é apresentado à rede, com atualização automática dos pesos. -

O padrão (1, 2) é apresentado à rede, com atualização automática dos pesos. -

O padrão (1, 3) é apresentado à rede, com atualização automática dos pesos. -

O padrão (1, 0) é apresentado à rede, com atualização automática dos pesos. -

O padrão (2, 1) é apresentado à rede, com atualização automática dos pesos. -
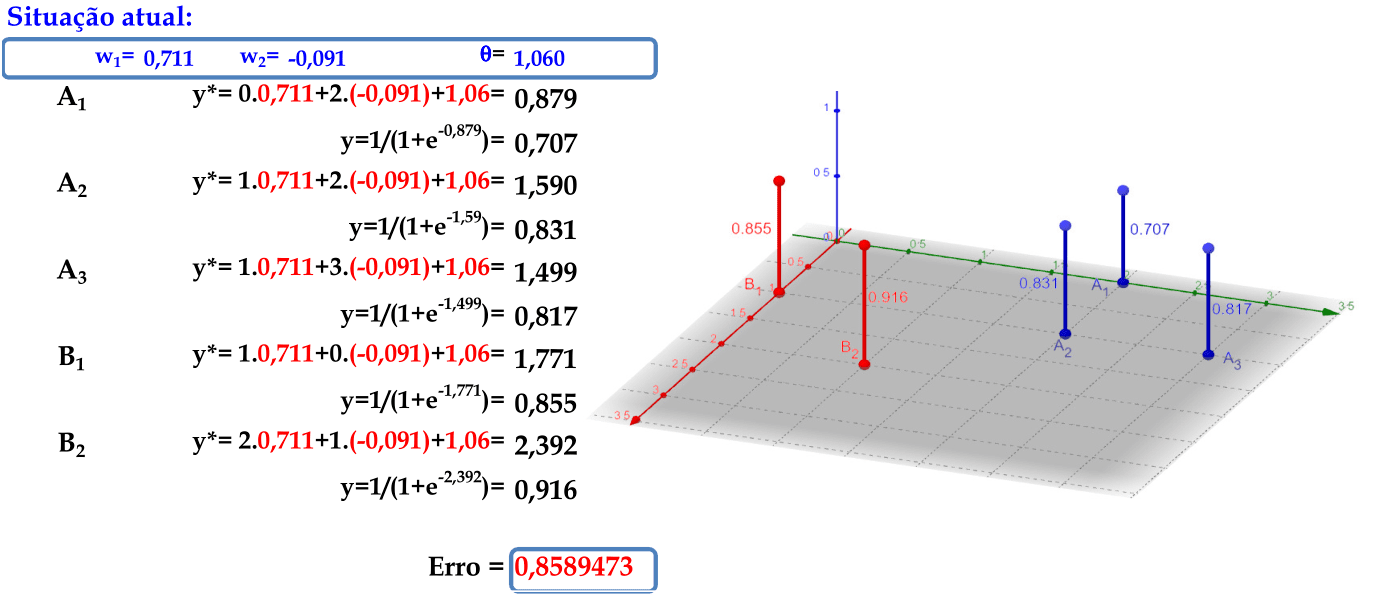
Calculamos as saídas y* e y de cada padrão de entrada para encontrarmos o erro desta iteração. A função do cálculo do erro é a mesma que foi usada para deduzir a Regra Delta: E = ∑k((dk - y)2)/2 = 0,859. -
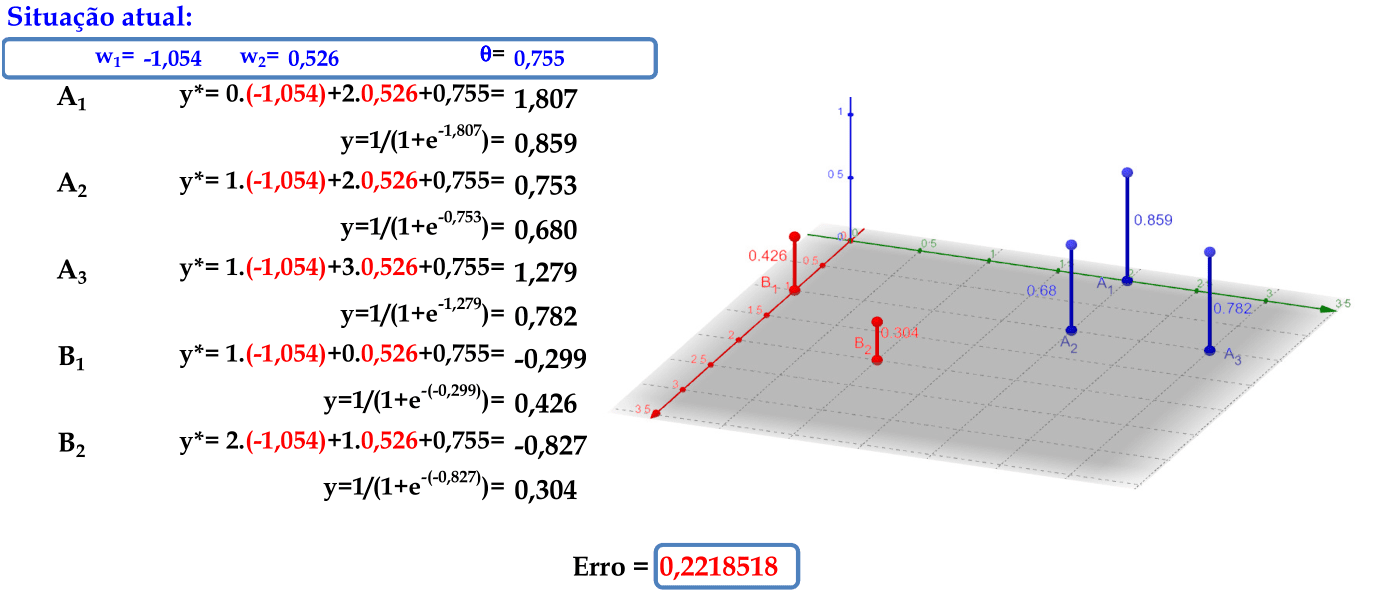
No final da 10ª iteração, temos esta combinação de pesos. O erro nesta iteração é E = ∑k((dk - y)2)/2 = 0,222, que representa uma grande redução quando comparada com as duas primeiras iterações.
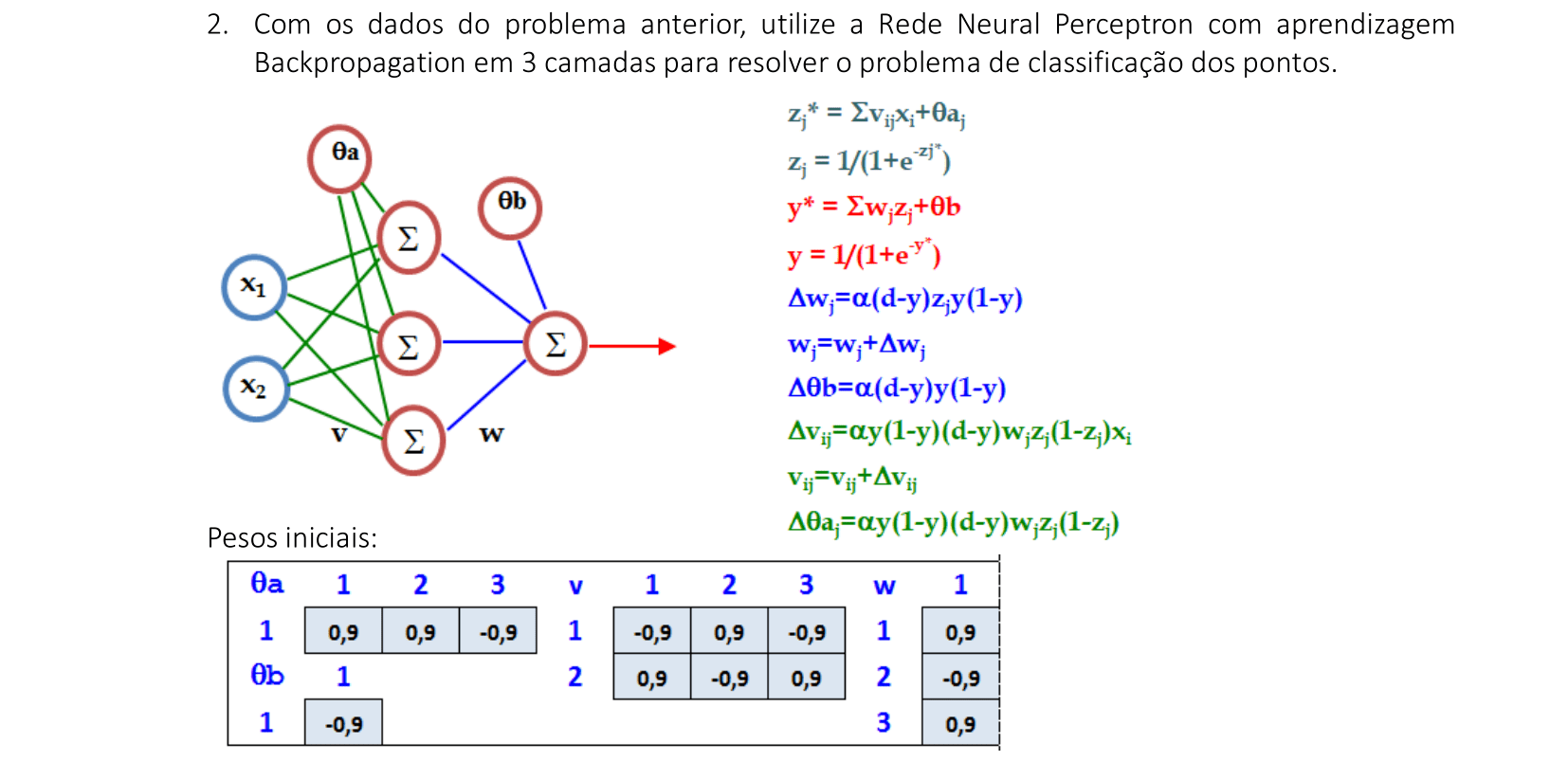
📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício de classificação de padrões usando uma Rede Neural Multi Layer Perceptron (MLP). Vamos usar saídas binárias para classificar os padrões de entrada em dois conjuntos A e B, além de uma camada escondida para acelerar a convergência.
-

A arquitetura da Rede Neural deste exercício tem 3 neurônios na camada escondida. O resumo dos cálculos está mostrado nesta imagem. Vamos inicializar com os pesos indicados de v, w, θa e θb e a taxa de aprendizagem α = 1. -
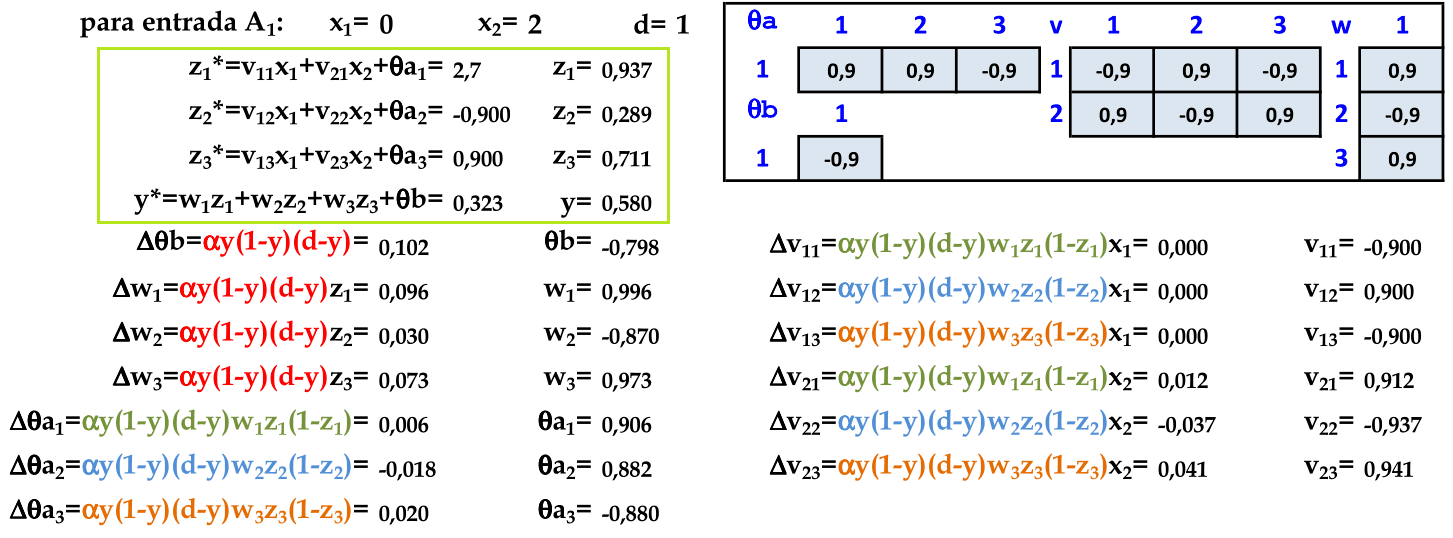
O primeiro padrão (0, 2) é apresentado à rede. Calculamos a saída z* e aplicamos a função de ativação sigmóide (na camada escondida, podemos aplicar a função tanh ou limiar). Com os valores z, calculamos a saída da rede y* com a função de ativação sigmóide. -
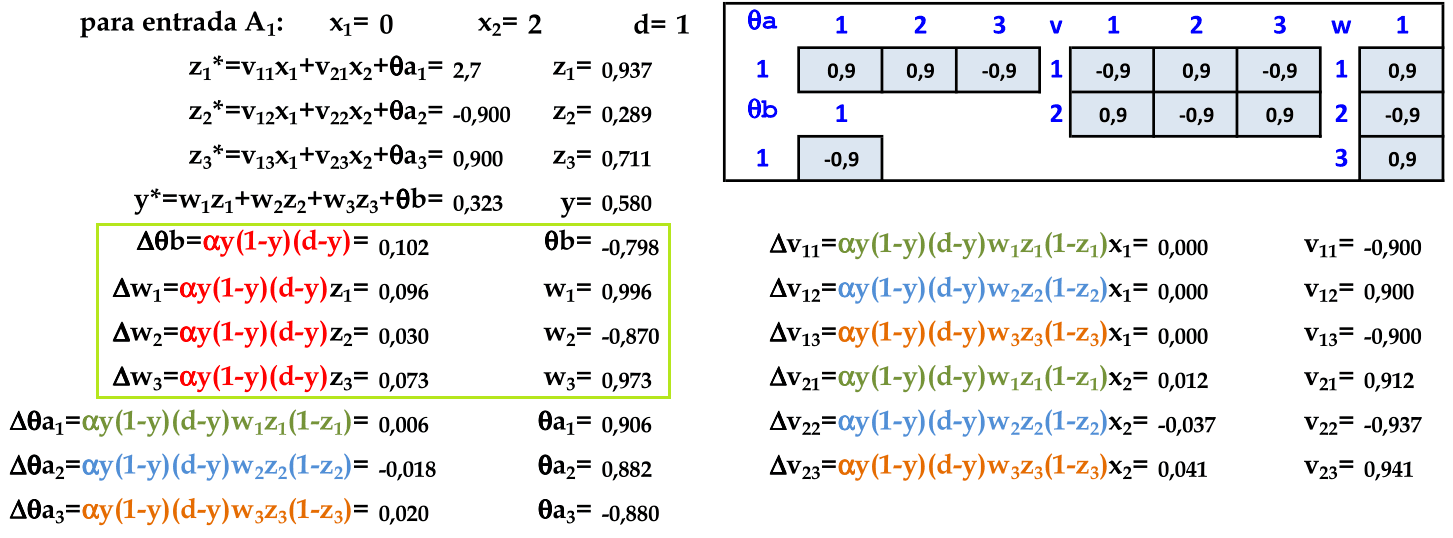
De acordo com o algoritmo Backpropagation, atualizamos primeiro os pesos da camada de saída w. Podemos simplificar a atualização dos pesos w, pois o termo Δθb é comum nas atualizações dos pesos w. -
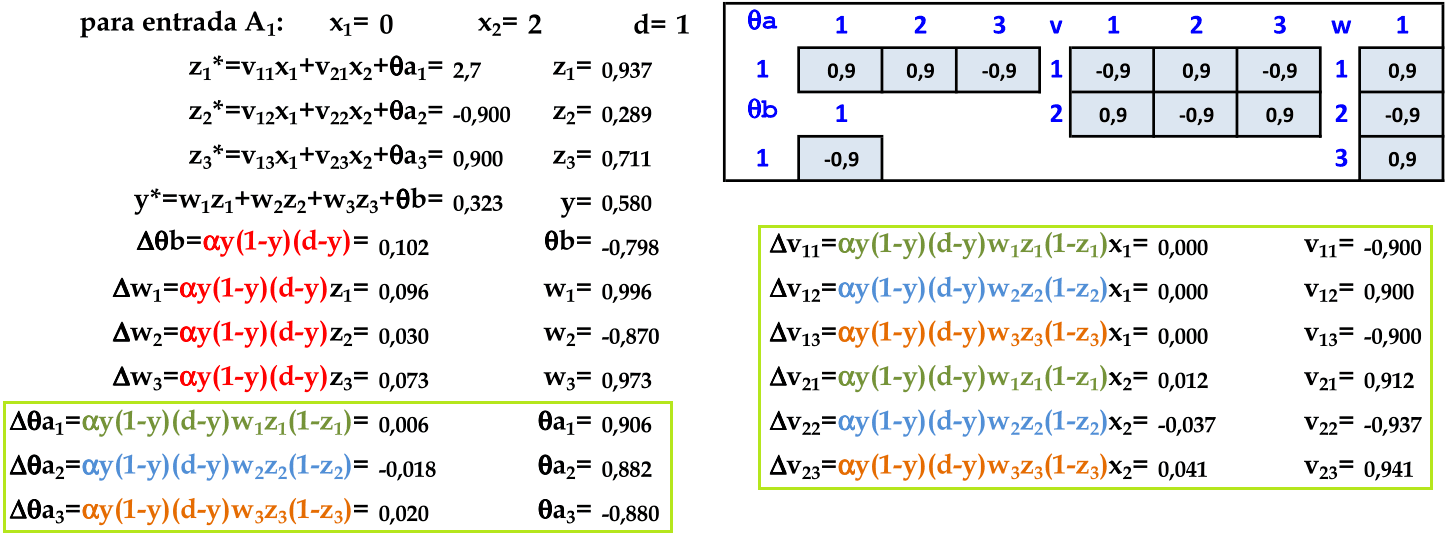
De acordo com o algoritmo Backpropagation, atualizamos a seguir os pesos da camada de entrada v. Podemos simplificar a atualização dos pesos v, pois os termos Δθa1, Δθa2 e Δθa3 são comuns nestas atualizações de pesos. -
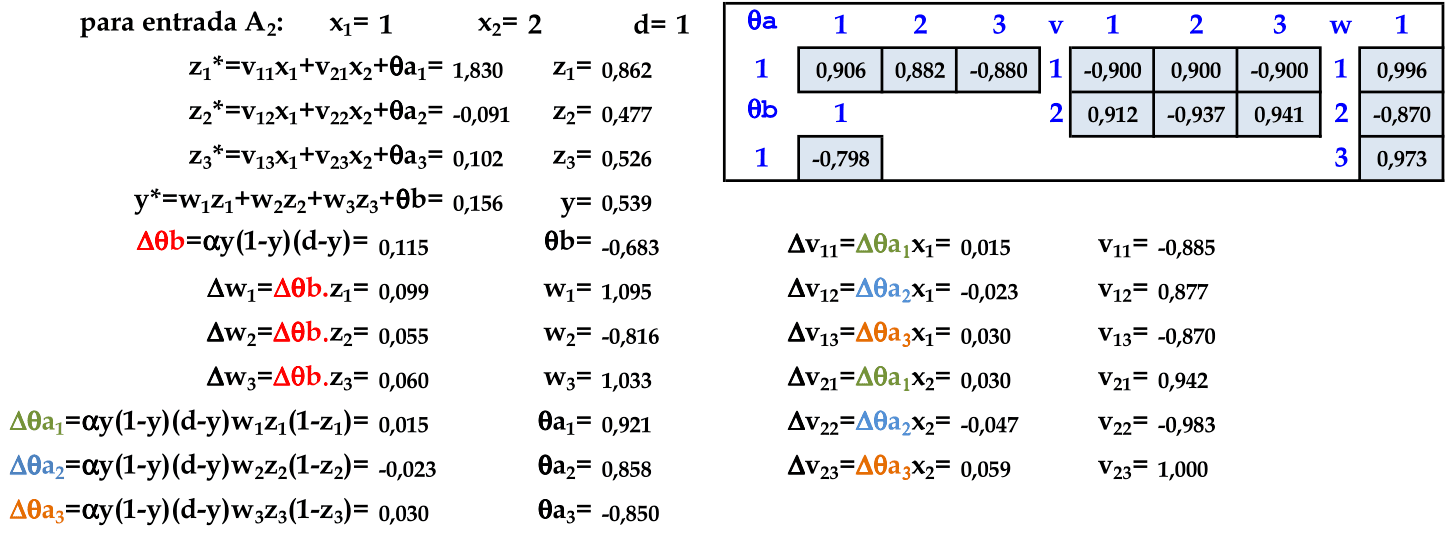
O padrão (1, 2) é apresentado à rede, com a atualização automática dos pesos. Usamos a simplificação de atualização dos pesos para as próximas apresentações de padrões de entrada. -
O padrão (1, 3) é apresentado à rede, com a atualização automática dos pesos. Este é o último padrão de entrada do conjunto com d = 1. -
O padrão (2, 1) é apresentado à rede, com a atualização automática dos pesos. Este é o primeiro padrão de entrada do conjunto com d = 0. -

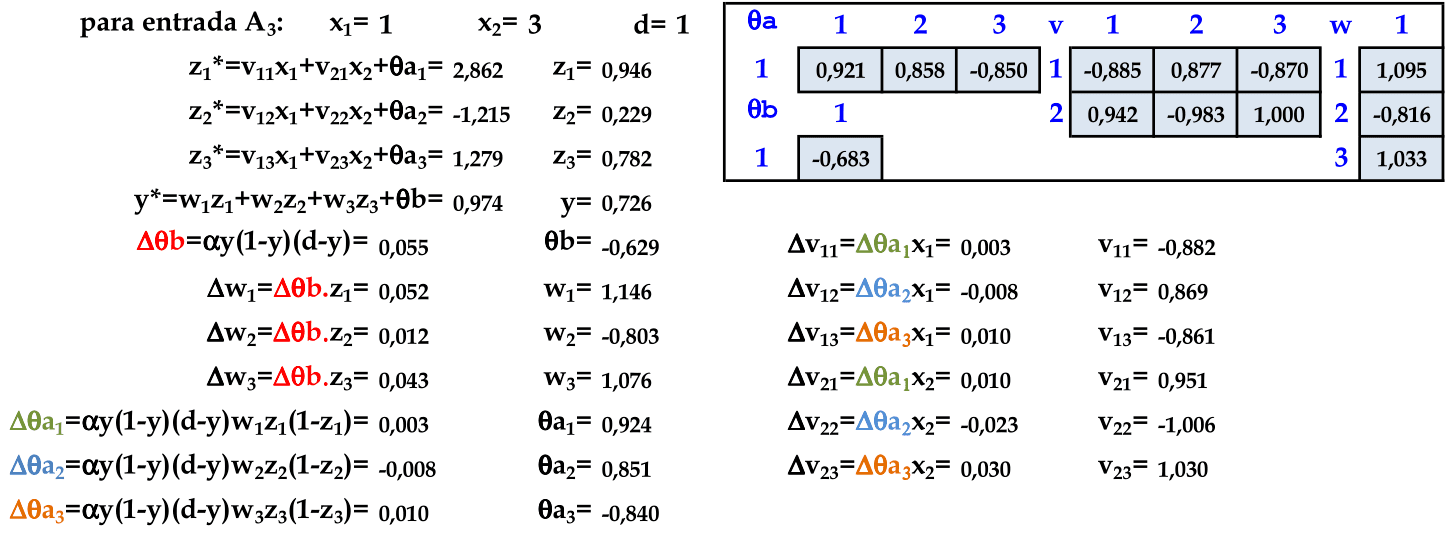
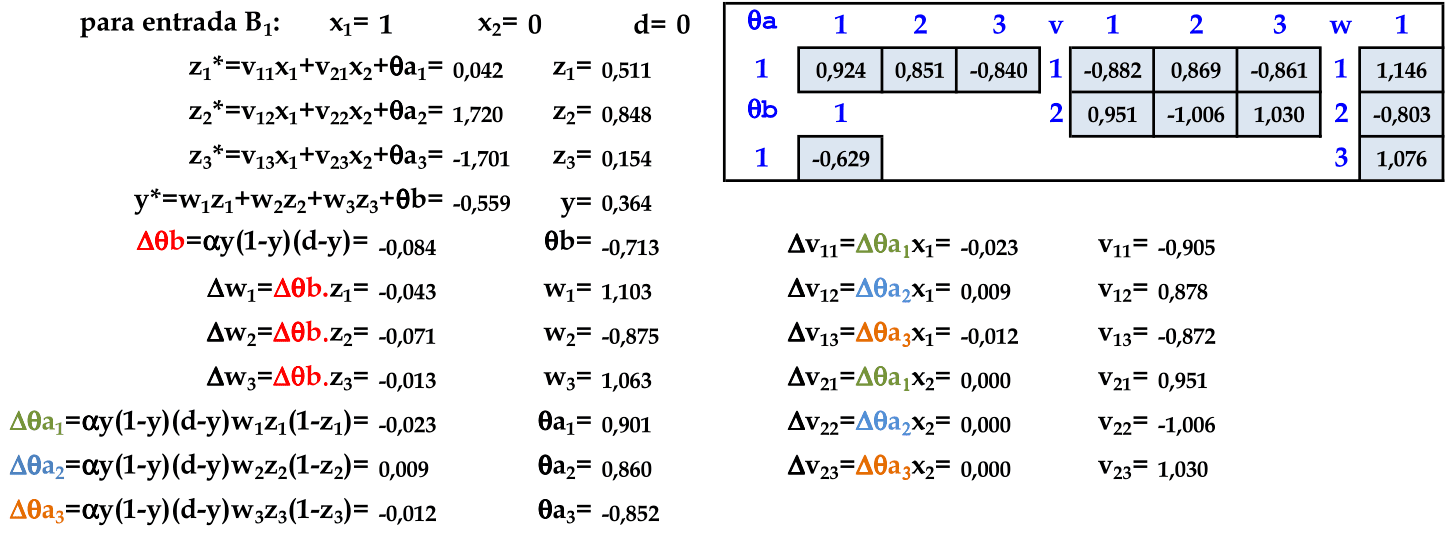
O padrão (1, 0) é apresentado à rede, com a atualização automática dos pesos. Este é o último padrão de entrada nesta rede, finalizando a primeira iteração. -
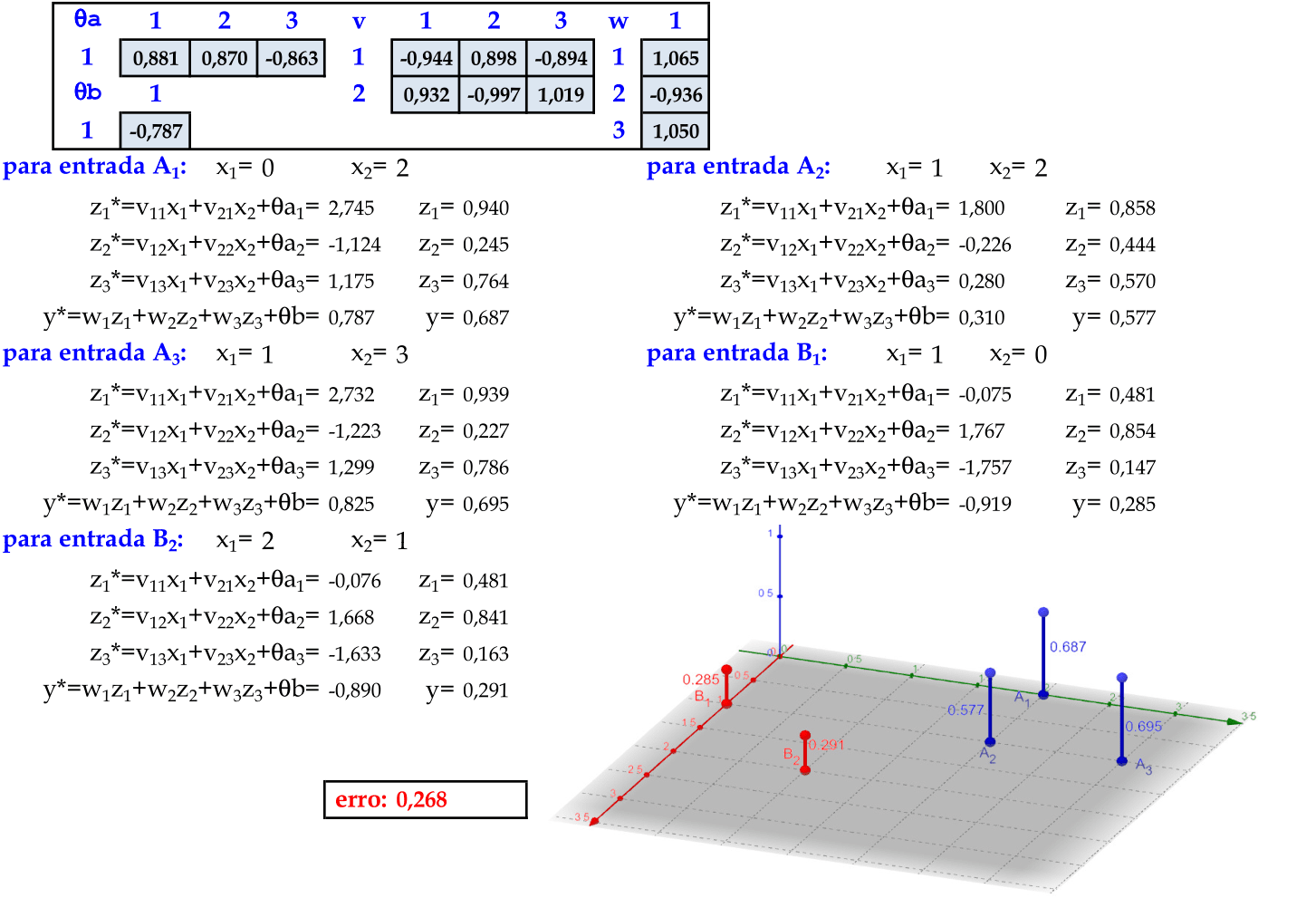
Calculamos as saídas z* e z para determinar as saídas y* e y de cada padrão de entrada. A função do cálculo do erro é a mesma que foi usada para deduzir a Regra Delta: E = ∑k((dk - y)2)/2 = 0,268. A interpretação geométrica da MLP pode ser melhor compreendida usando o gráfico em 3 dimensões. -

Na segunda iteração, precisamos atualizar a taxa de aprendizagem: α = α.0,95. O primeiro padrão (0, 2) é apresentado à rede, com atualização automática dos pesos. -

No final da 10ª iteração, temos esta configuração de pesos. O erro nesta iteração é E = ∑k((dk - y)2)/2 = 0,102.
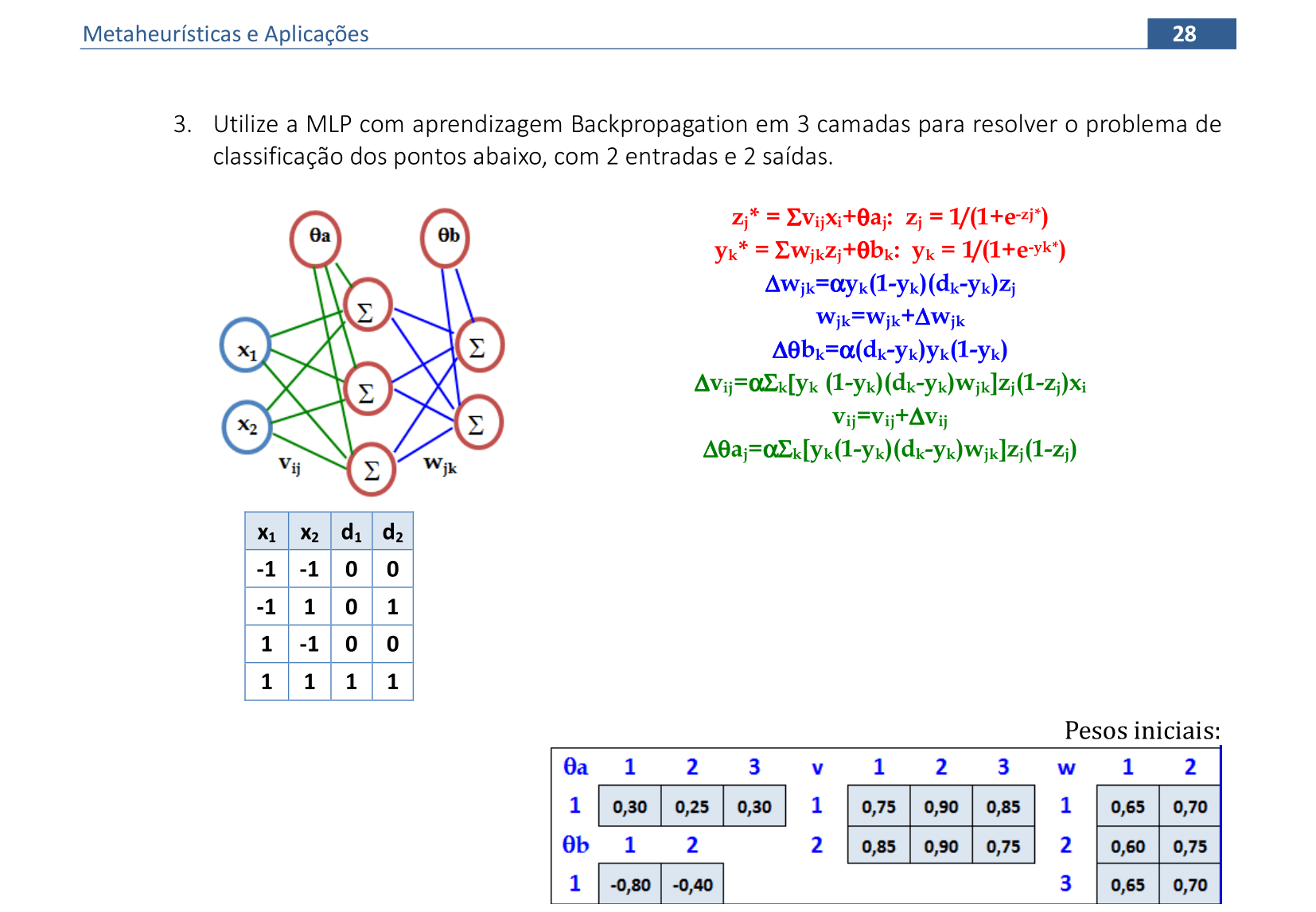
📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício de classificação de padrões usando uma Rede Neural Multi Layer Perceptron (MLP). Vamos usar saídas binárias para classificar os padrões de entrada com duas variáveis de saída y e uma camada escondida.
-

A arquitetura da Rede Neural deste exercício tem 3 neurônios na camada escondida. O resumo dos cálculos está mostrado nesta imagem. Vamos iniciar com os pesos indicados de v, w, θa e θb e a taxa de aprendizagem α = 1. -
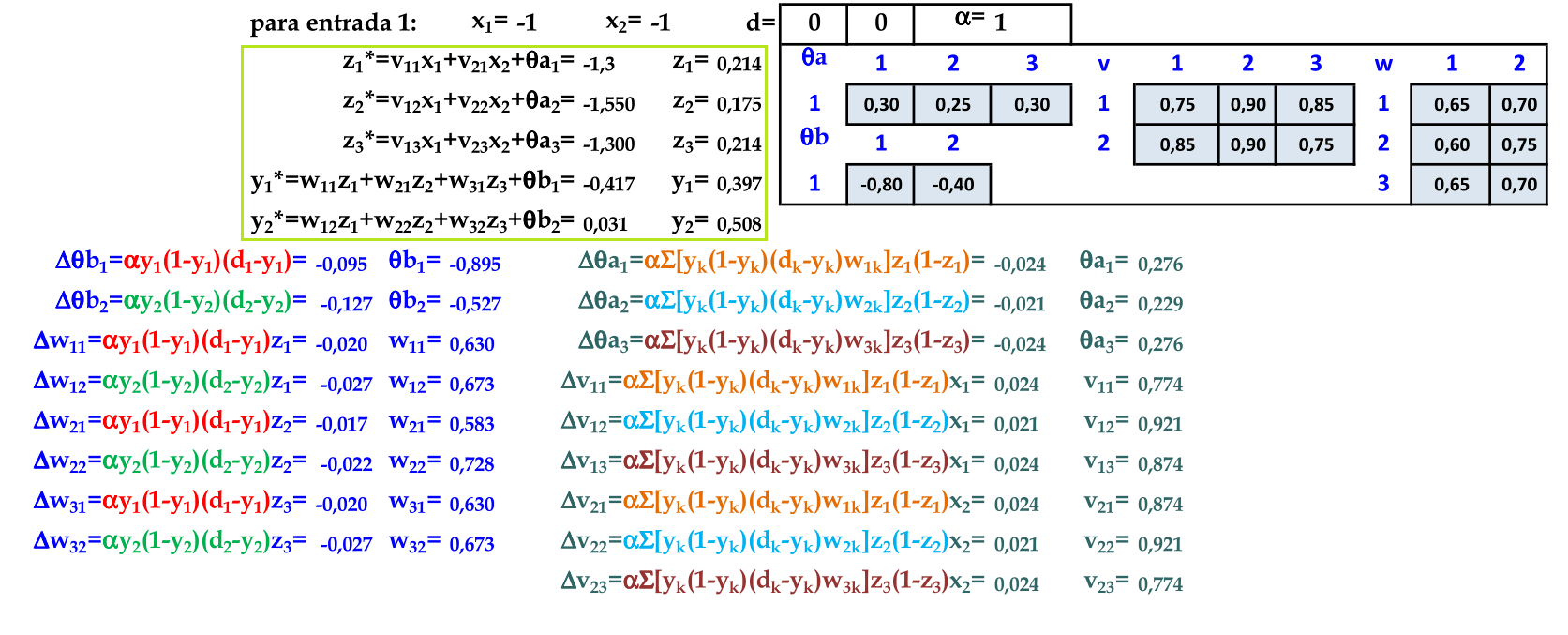
O primeiro padrão (-1, -1) é apresentado à rede. Calculamos a saída z* e aplicamos a função de ativação sigmóide (na camada escondida, podemos aplicar a função tanh ou limiar). Com os valores z, calculamos a saída da rede y* com a função de ativação sigmóide. -
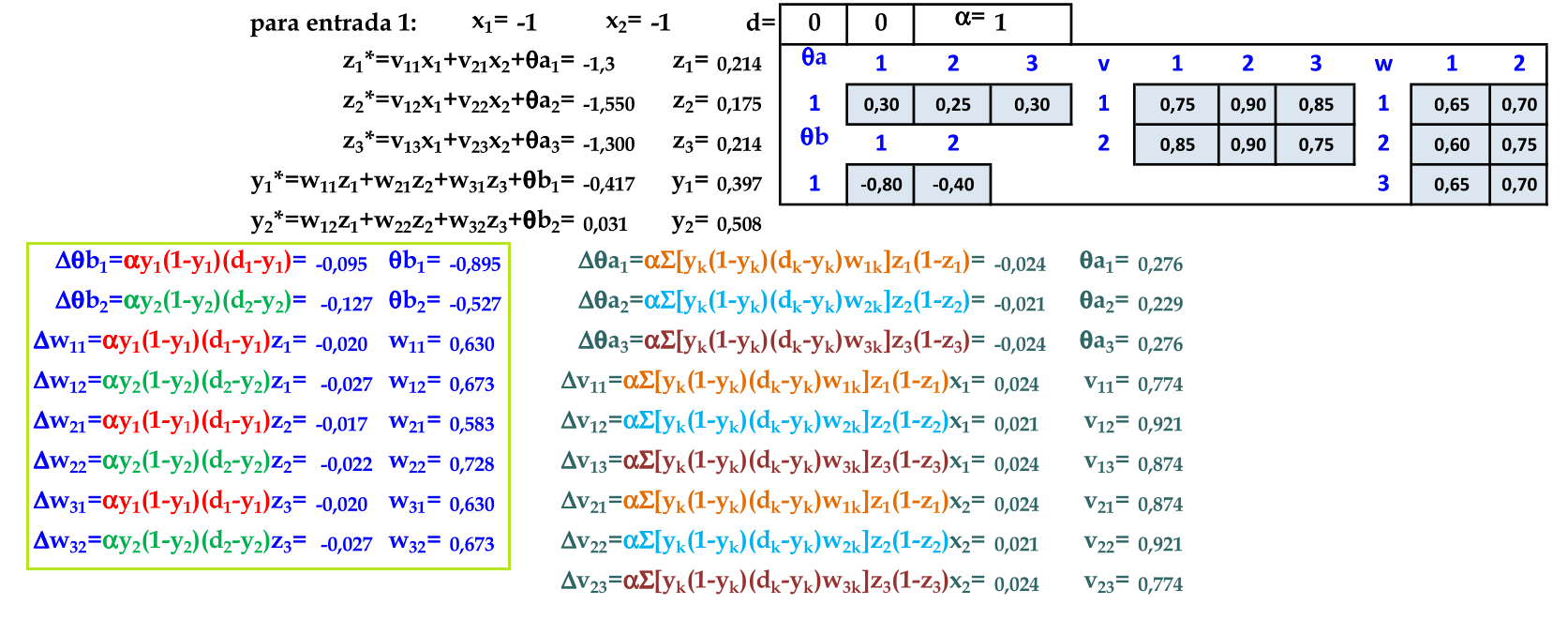
De acordo com o algoritmo Backpropagation, atualizamos primeiro os pesos da camada de saída w. Podemos simplificar a atualização dos pesos w, pois os termos Δθb1 e Δθb2 são comuns nas atualizações dos pesos w. -

De acordo com o algoritmo Backpropagation, atualizamos a seguir os pesos da camada de entrada v. Podemos simplificar a atualização dos pesos v, pois os termos Δθa1, Δθa2 e Δθa3 são comuns nestas atualizações de pesos. -
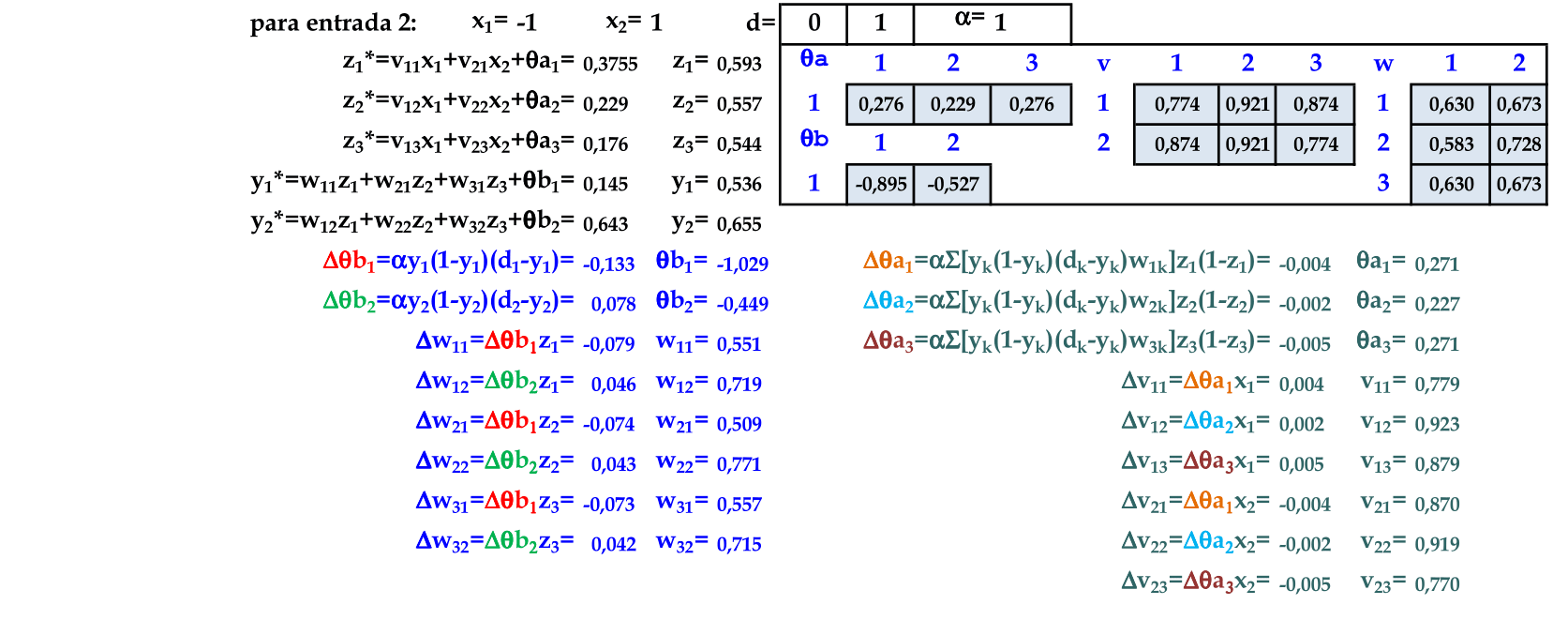
O padrão (-1, 1) é apresentado à rede, com a atualização automática dos pesos. Usamos a simplificação de atualização dos pesos para as próximas apresentações de padrões de entrada. -
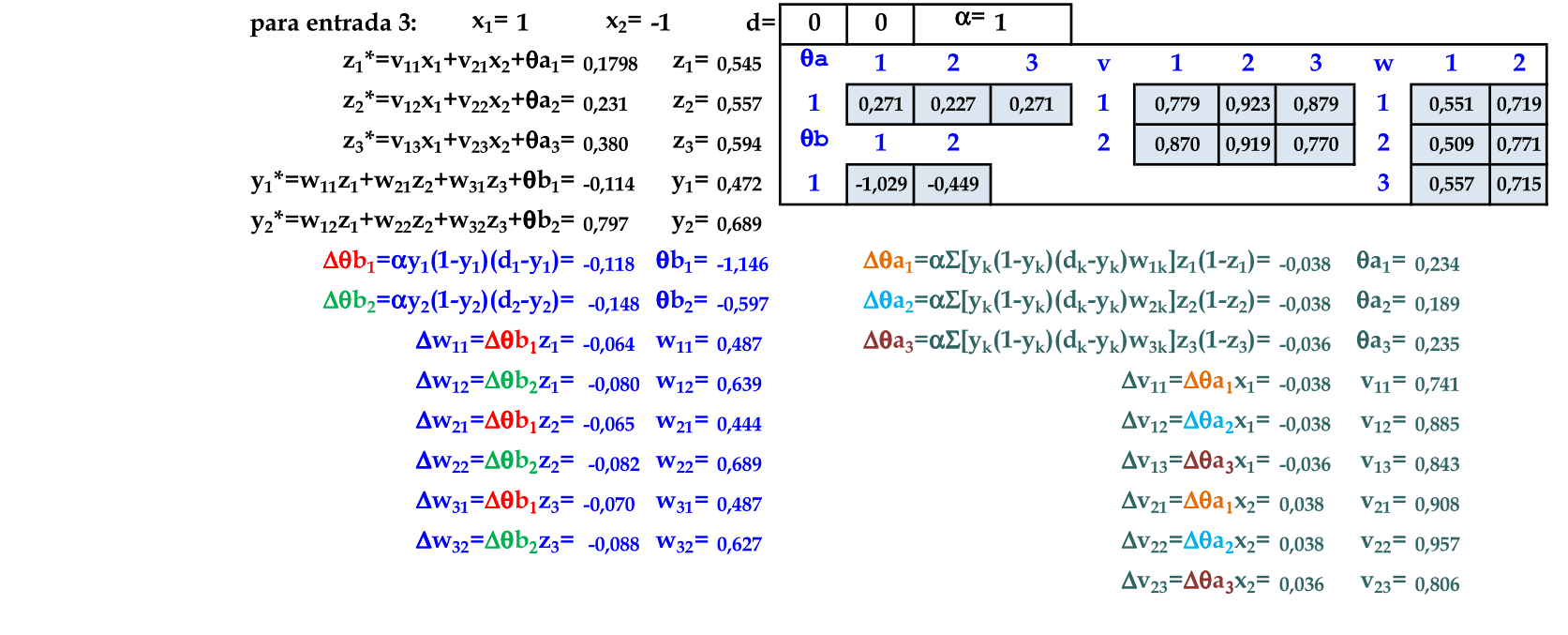
O padrão (1, -1) é apresentado à rede, com a atualização automática dos pesos. -
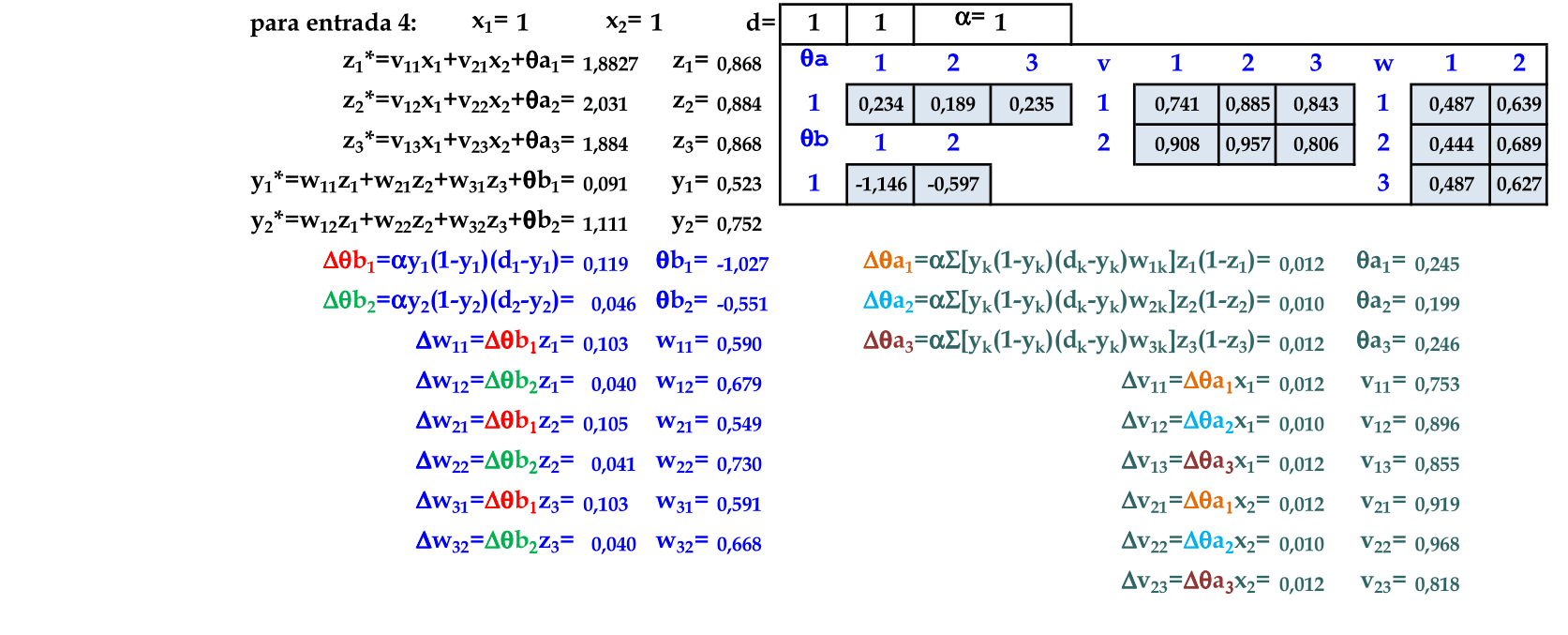
O padrão (1, 1) é apresentado à rede, com a atualização automática dos pesos. Este é o último padrão de entrada nesta rede, finalizando a primeira iteração. -

Calculamos as saídas z* e z para determinar as saídas y* e y de cada padrão de entrada. A função do cálculo do erro é a mesma que foi usada para deduzir a Regra Delta: E = ∑k((dk - y)2)/2 = 0,753. -

Na segunda iteração, precisamos atualizar a taxa de aprendizagem: α = α.0,99. O primeiro padrão (-1, -1) é apresentado à rede, com atualização automática dos pesos. -

No final da 7ª iteração, temos esta configuração de pesos. O erro nesta iteração é E = ∑k((dk - y)2)/2 = 0,523.

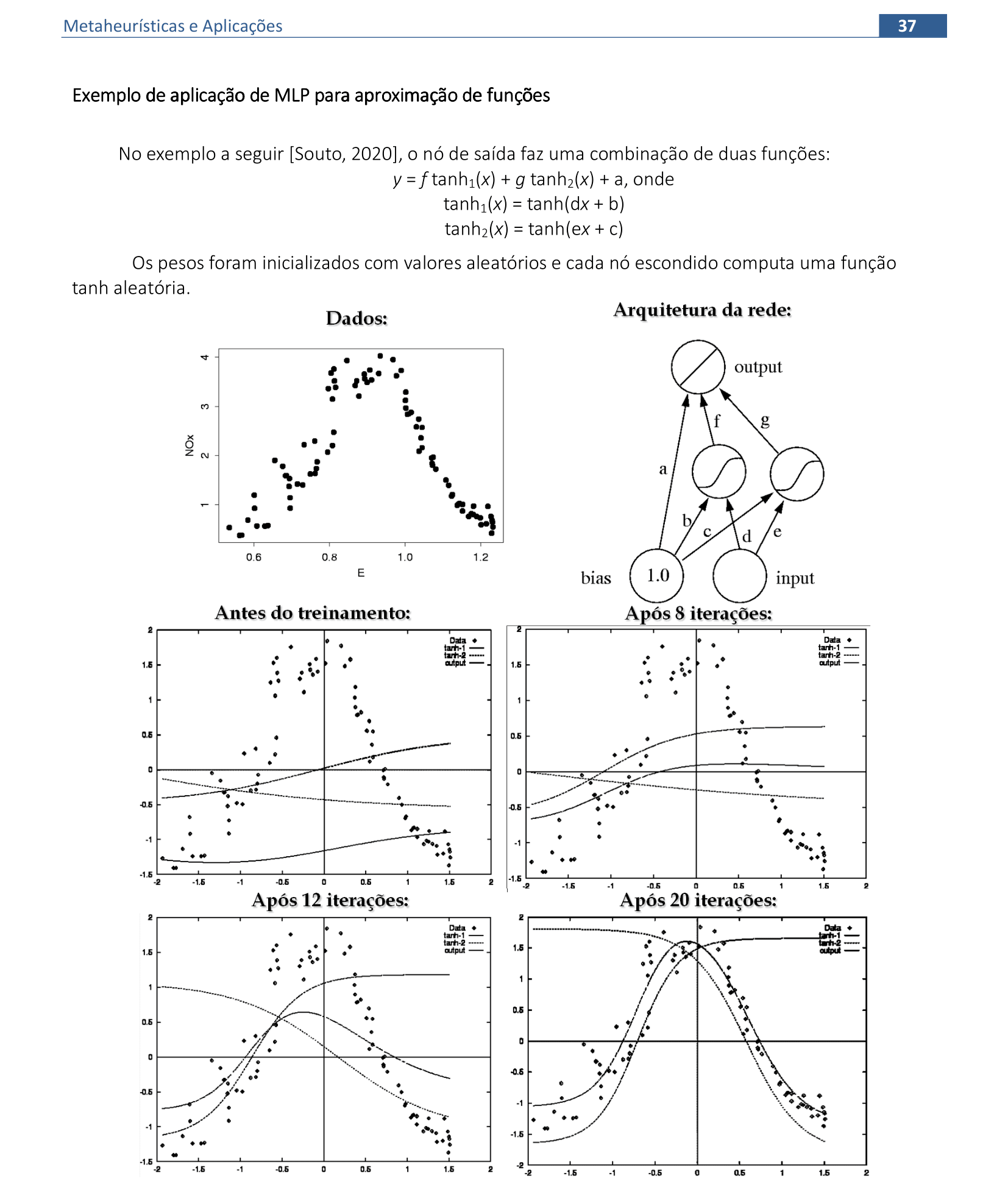
3. Multi Layer Perceptron (MLP) e aplicações
Material das páginas 29 até 40.












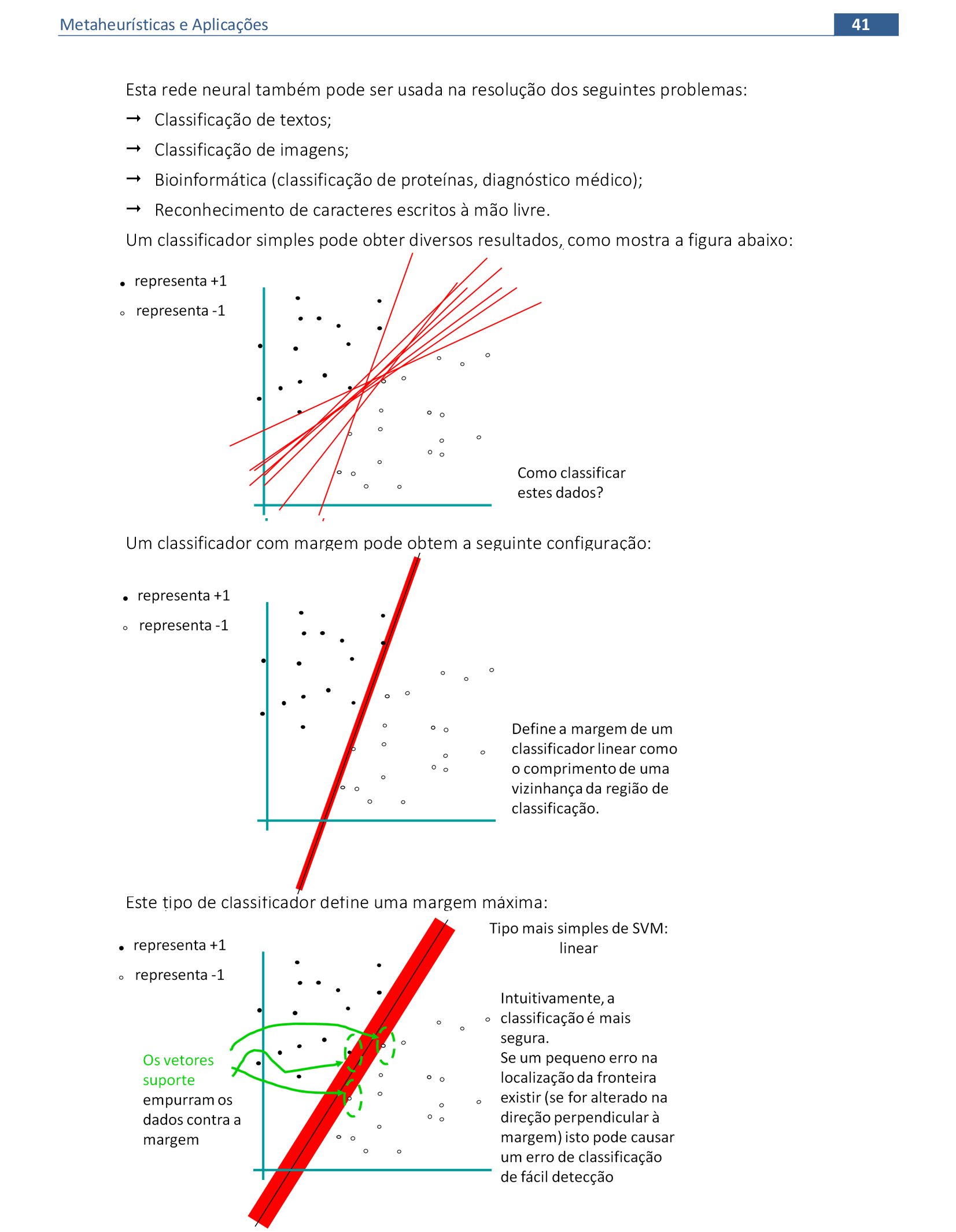
4. Support Vector Machines e Redes de Bases Radiais
Material das páginas 40 até 49.


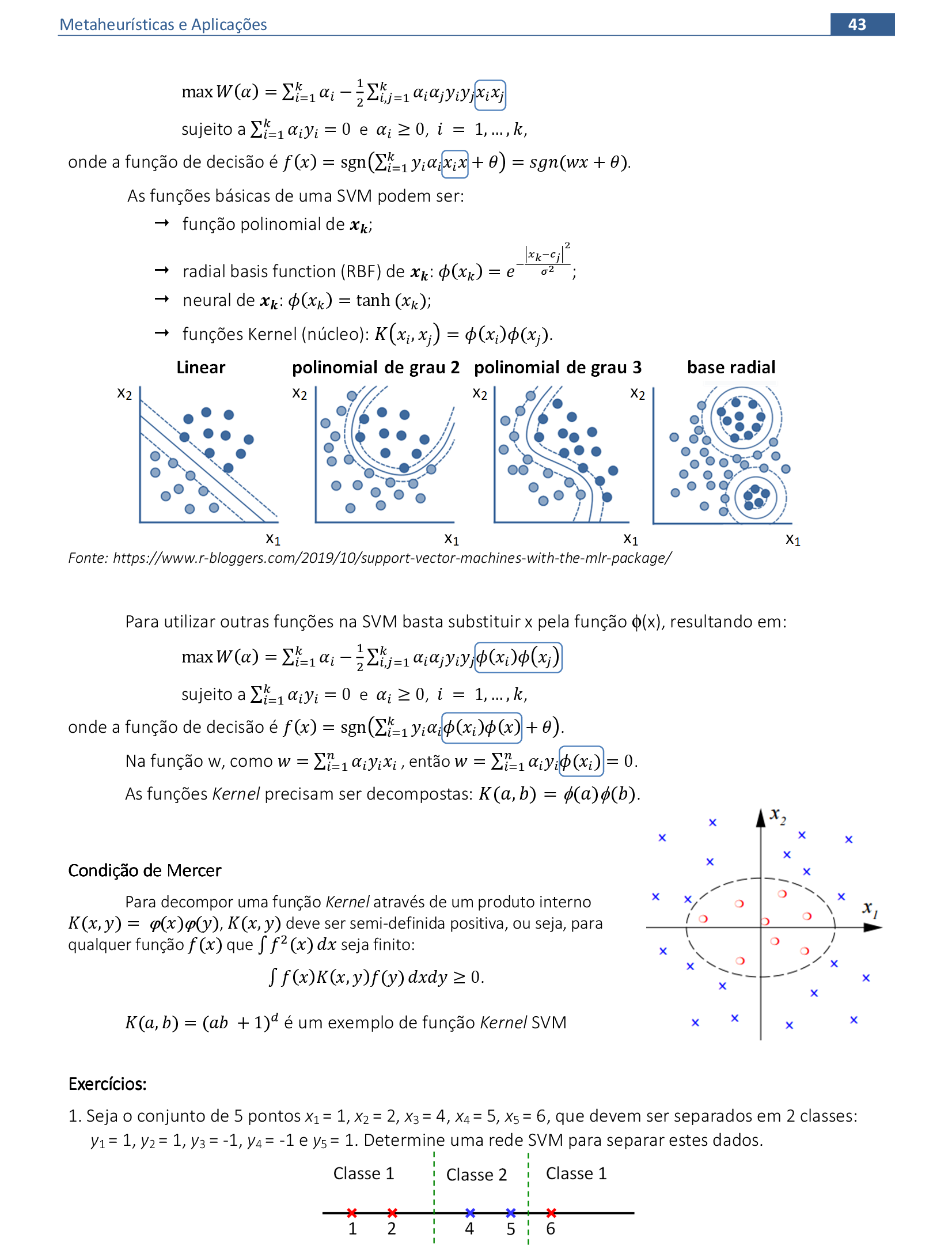
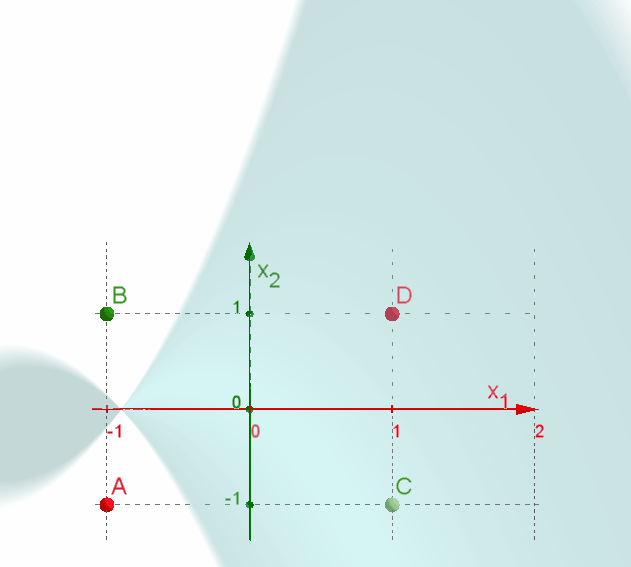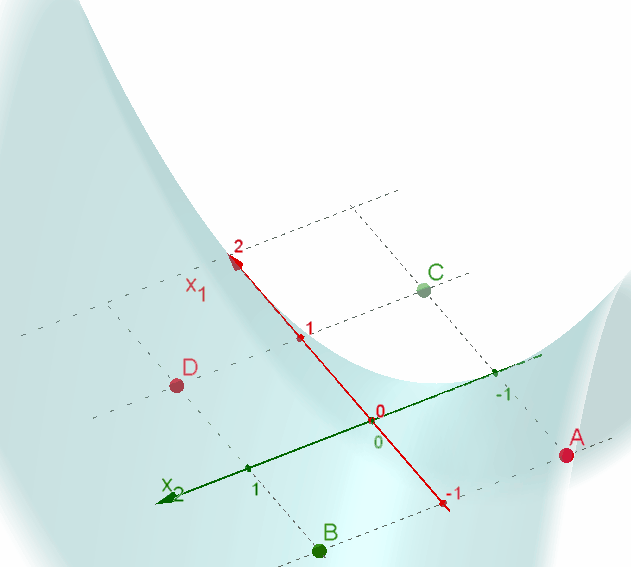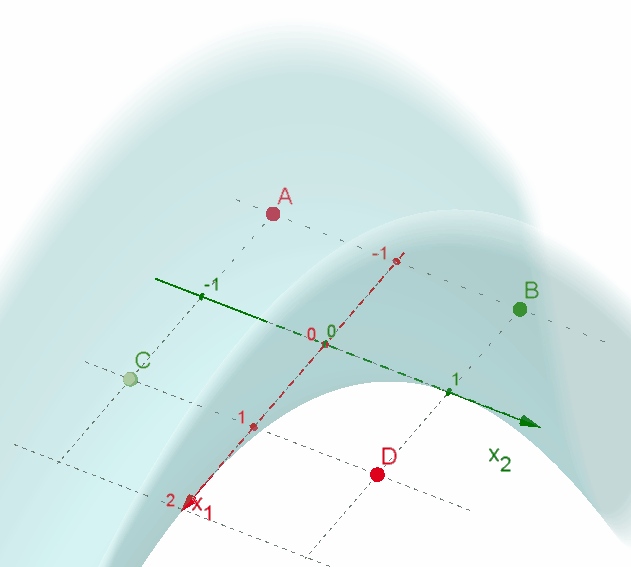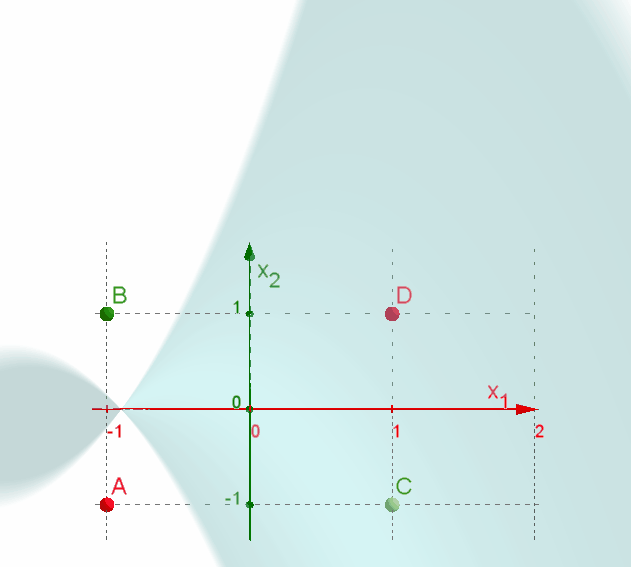
📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício da Rede Support Vector Machine (SVM) para classificação de padrões. A rede deve separar os dados de entrada em duas classes.
-

Utilizando a função de núcleo (1 + xTx), temos o problema de Programação Quadrática apresentado. Os valores de αi diferentes de zero nos mostram quais serão os vetores suporte: 2, 4 e 6. -

Substituindo os valores de x na função de decisão, encontramos a função de 2º grau. A parábola faz a separação dos dados nas classes 1 e 2.

📃 Resolução
Vamos acompanhar os resultados e as interpretações geométricas deste exercício de classificação usando a Rede Support Vector Machine (SVM). Os dados devem ser separados em duas classes.
-

Utilizando a função de núcleo (1 + xTx), precisamos desenvolvê-la para inserir os dados de entrada das variáveis x1 e x2. -
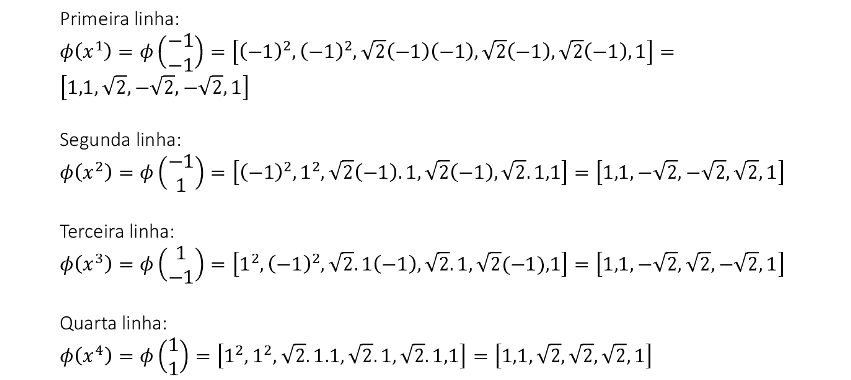
Substituindo os valores de x1 e x2 na função de decisão, encontramos os vetores de decisão. -

Resolvendo o problema de programação quadrática, todas as variáveis de decisão ficam com os respectivos valores $\mathsf{\alpha_i = {1 \over 8}}$, ou seja, todas as variáveis representam vetores suportes. Substituindo estes valores, temos o vetor w. -
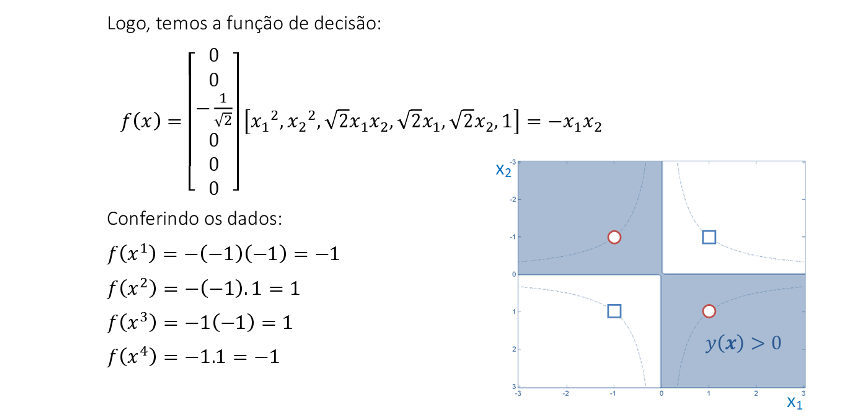
A função decisão fica representada por f(x) = −x1x2. Todos os dados de entrada ficam classificados corretamente com a SVM apresentada. -



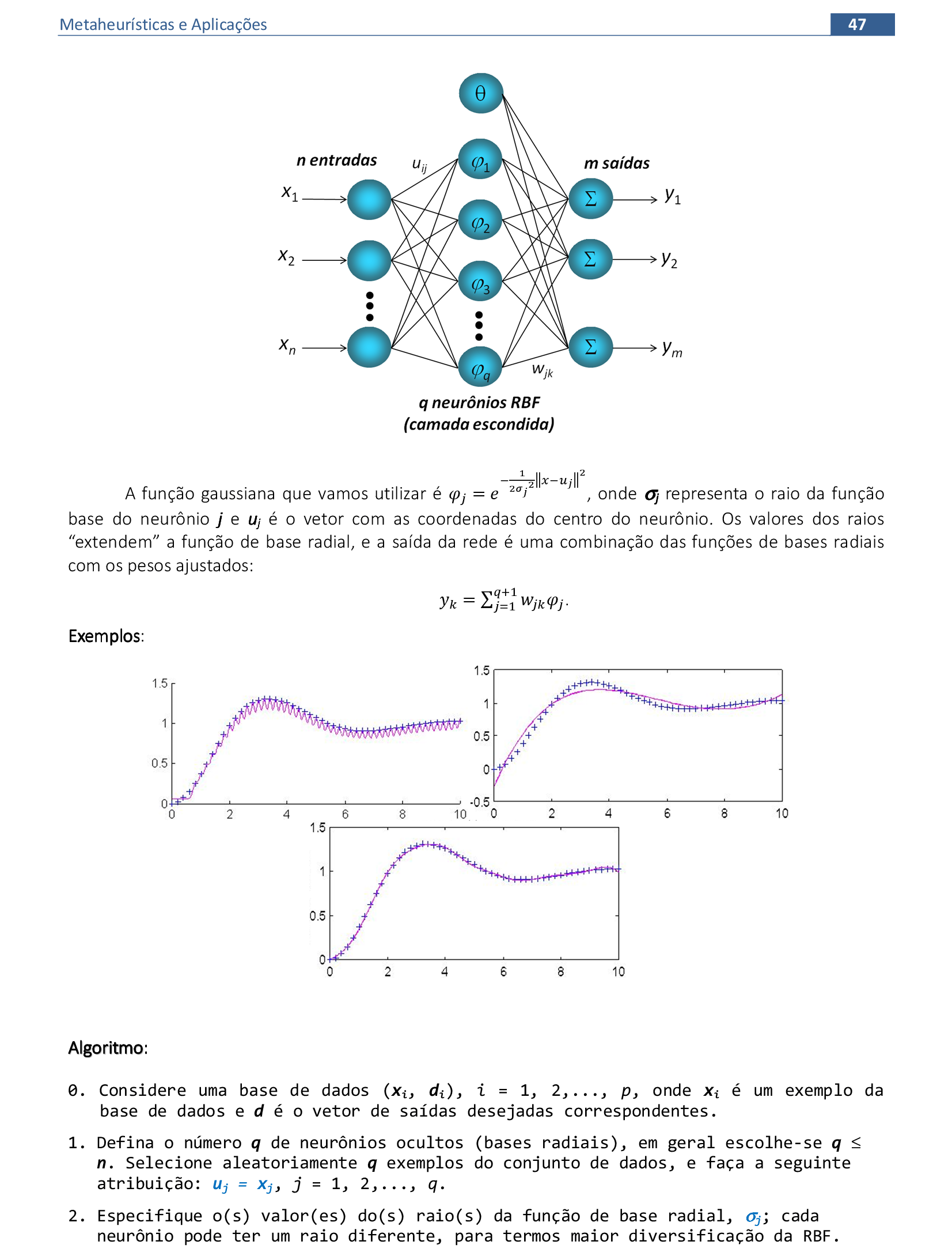

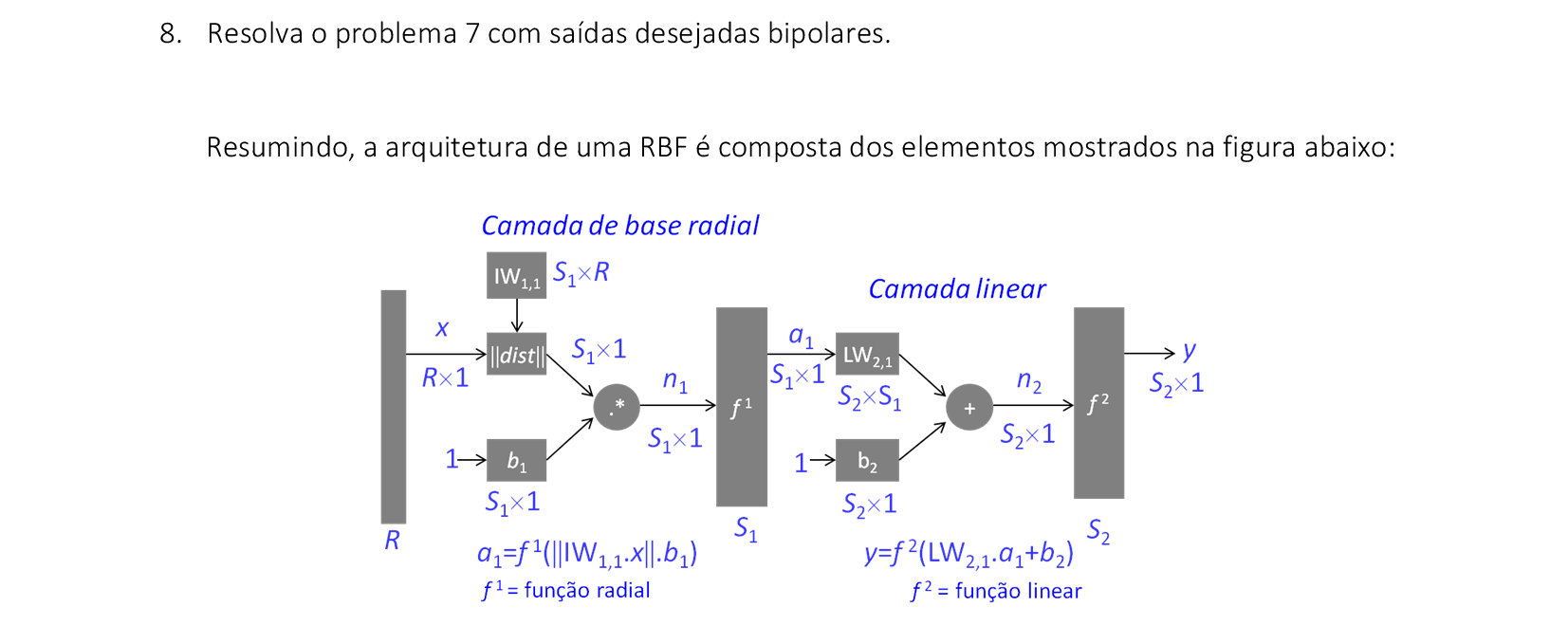
📃 Algoritmo comentado
0. Considere uma base de dados (xi, di), i = 1, 2,..., p, onde xi é um exemplo da base de dados
e d é o vetor de saídas desejadas correspondentes.
1. Defina o número q de neurônios ocultos (bases radiais), em geral escolhe-se q ≤ n.
Selecione aleatoriamente q exemplos do conjunto de dados, e faça a seguinte atribuição:
uj = xj, j = 1, 2,..., q.
2. Especifique o(s) valor(es) do(s) raio(s) da função de base radial, σj.
Cada neurônio pode ter um raio diferente, para termos maior diversificação da RBF.
3. Para cada exemplo da base de dados xi, onde i = 1, 2, ..., p, execute os passos 4 e 5:
4. Calcule a ativação de cada neurônio j da camada escondida:
ϕj = e-1/(2σ2)‖xi−uj‖2
5. Atribua os valores das ativações dos neurônios na matriz G:
Gi,j = ϕj, e Gi,q+1 = θ
6. Após a apresentação de todos os exemplos, calcule os pesos da saída:
w = (GTG)-1GTd
Temos essa expressão de w, pois:
Gw = d ⇒ GTGw = GTd ⇒ (GTG)-1(GTG)w = (GTG)-1GTd ⇒ w = (GTG)-1GTd.
7. Calcule a saída de cada exemplo: yk = ∑j=1q+1wjkϕj. Calcule o erro de classificação.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões com a rede neural Radial Basis Function (RBF). A rede deve separar os dados de entrada em duas classes usando 2 centros.
-
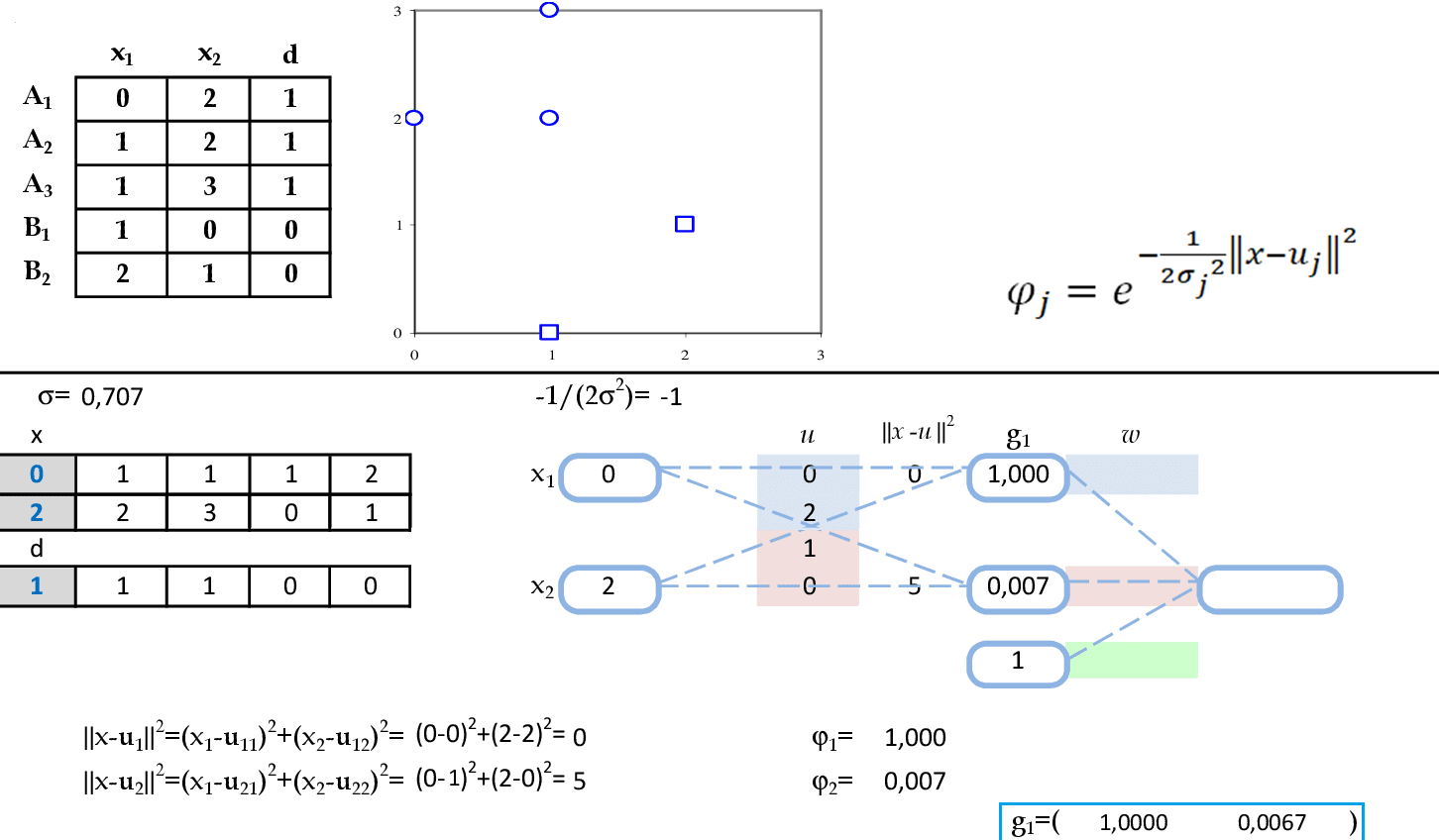
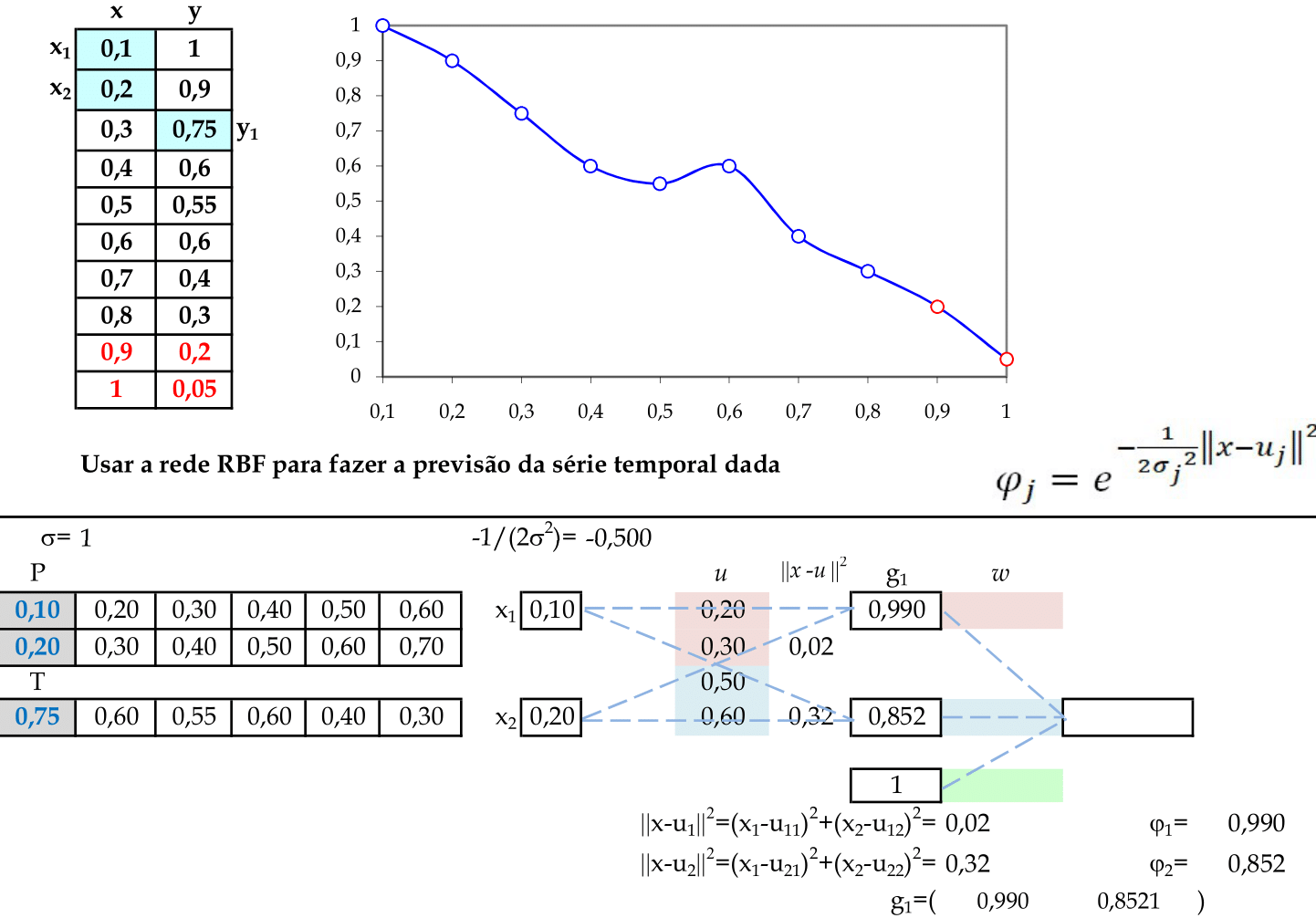
Vamos começar com a apresentação do padrão de entrada (x1, x2) = (0, 2), com σ = $\mathsf{\sqrt {0,5}}$. O resultado da ativação de cada neurônio da camada escondida será guardado na primeira linha da matriz G: g1. -

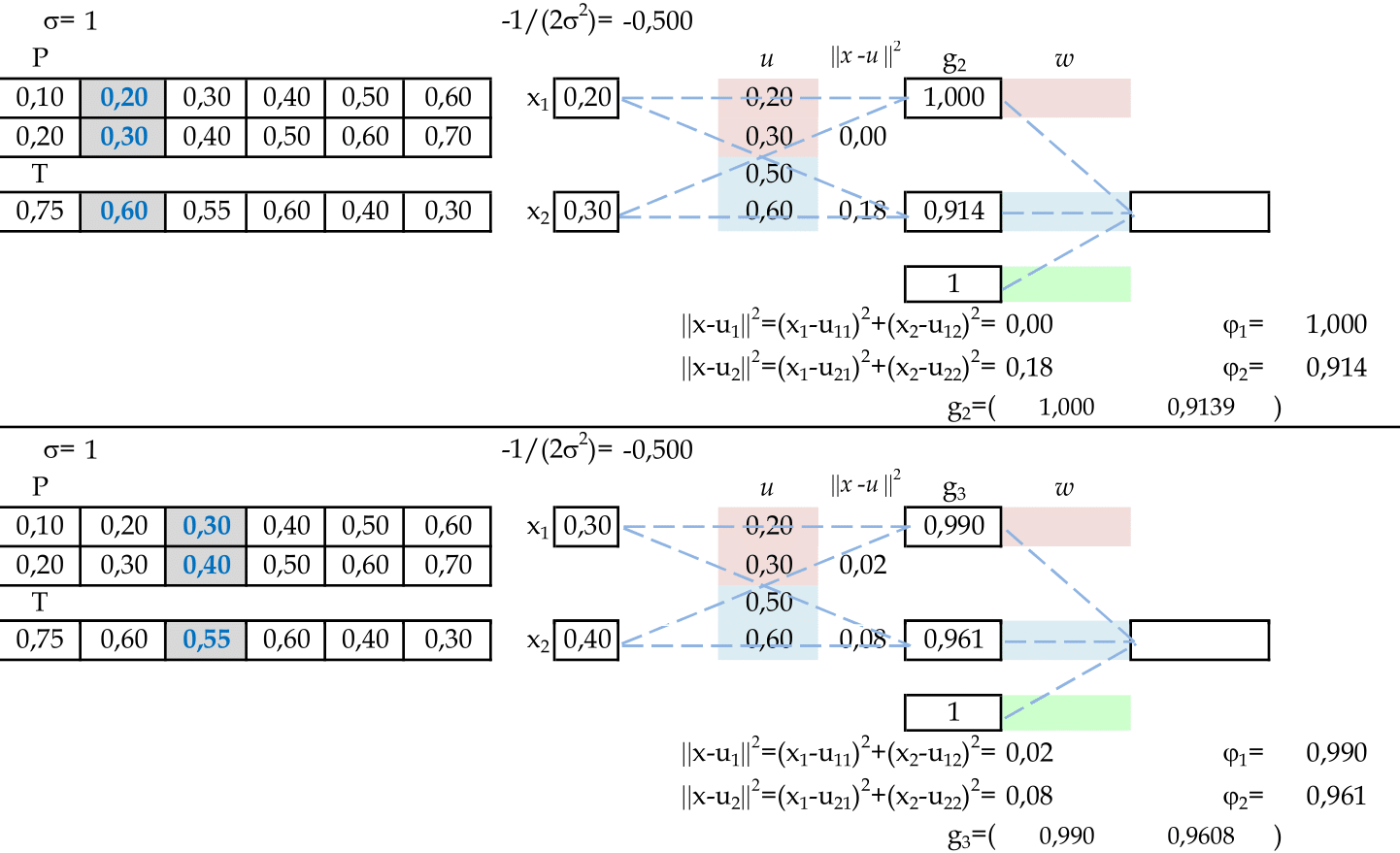
Agora temos as apresentações dos padrões de entrada (1, 2) e (1, 3). O resultado da ativação de cada neurônio da camada escondida será guardado nas linhas da matriz G: g2 e g3. -

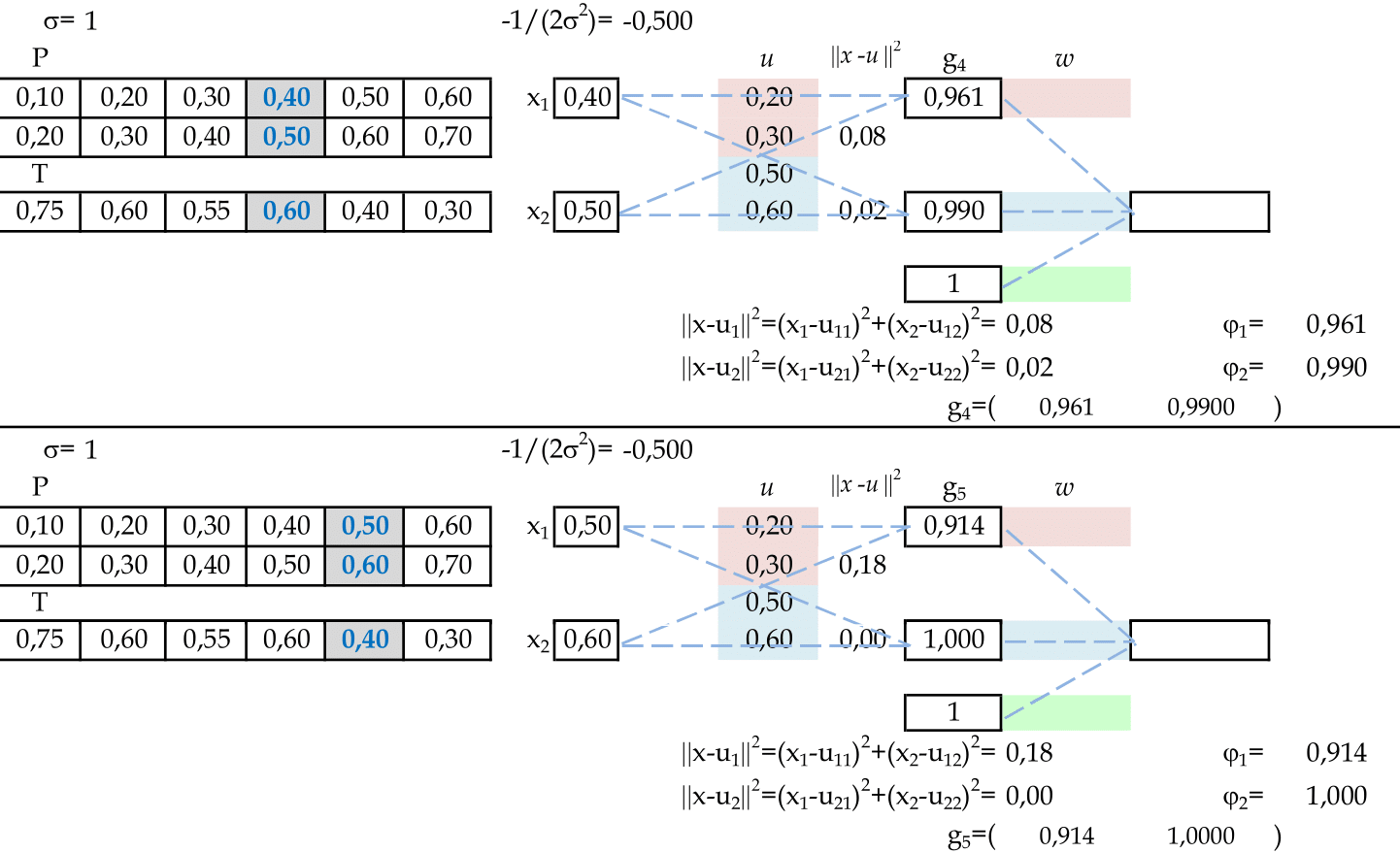
Agora temos as apresentações dos padrões de entrada (1, 0) e (2, 1). O resultado da ativação de cada neurônio da camada escondida será guardado nas linhas da matriz G: g4 e g5. -

Agora podemos calcular o vetor de pesos usando a matriz G. Note que a terceira coluna desta matriz tem valores iguais a 1, pois são as ativações de θ. Temos o vetor de pesos calculado da seguinte maneira: w = (GTG)-1GTd. -

Podemos calcular as saídas e os erros quadráticos desta rede para os dois primeiros padrões de entrada: y = w1φ1 + w2φ2 + θ e Ek = (dk − y)2)/2. -

Seguem os cálculos das saídas e os erros quadráticos desta rede para mais dois padrões de entrada. -
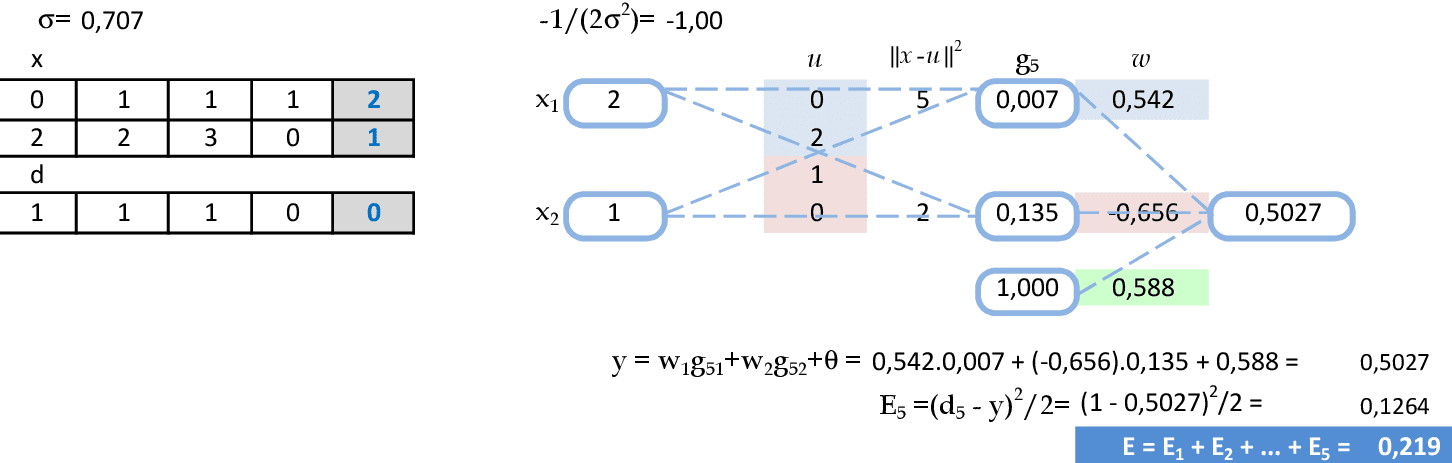
Para finalizar, são mostrados os cálculos da saída e do erro quadrático da rede para o último padrão de entrada. O erro quadrático total desta RBF ficou em E = 0,219.
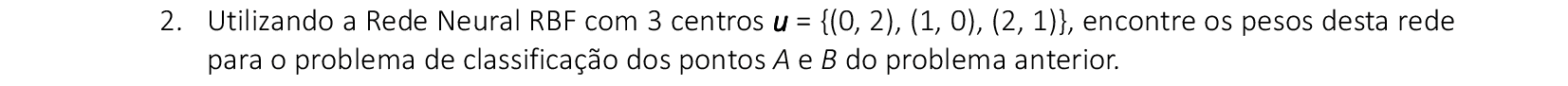
📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões com a rede neural Radial Basis Function (RBF). A rede deve separar os dados de entrada em duas classes com 3 centros.
-
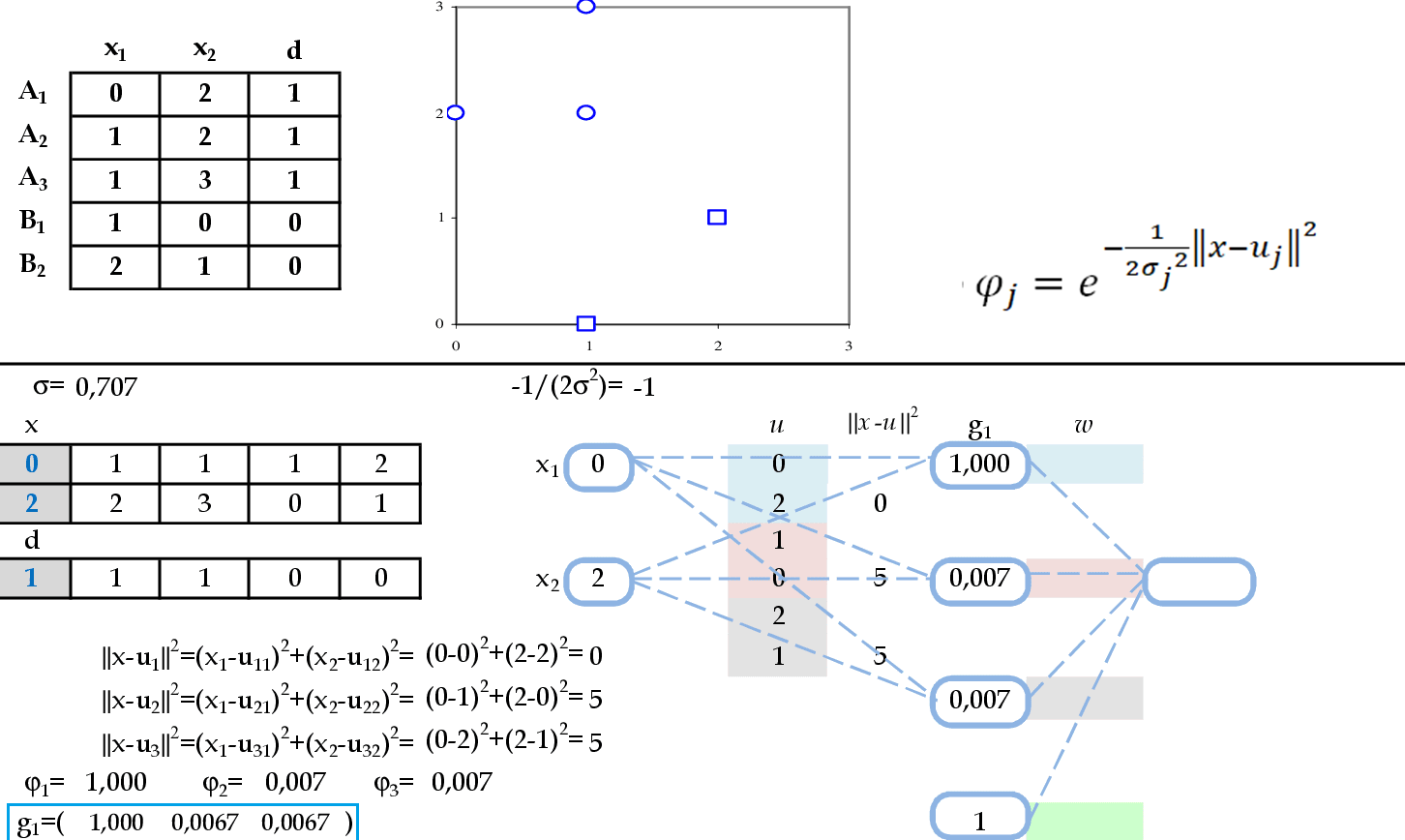
Vamos começar com a apresentação do padrão de entrada (x1, x2) = (0, 2), com σ = $\mathsf{\sqrt {0,5}}$. O resultado da ativação de cada neurônio da camada escondida será guardado na primeira linha da matriz G: g1. -
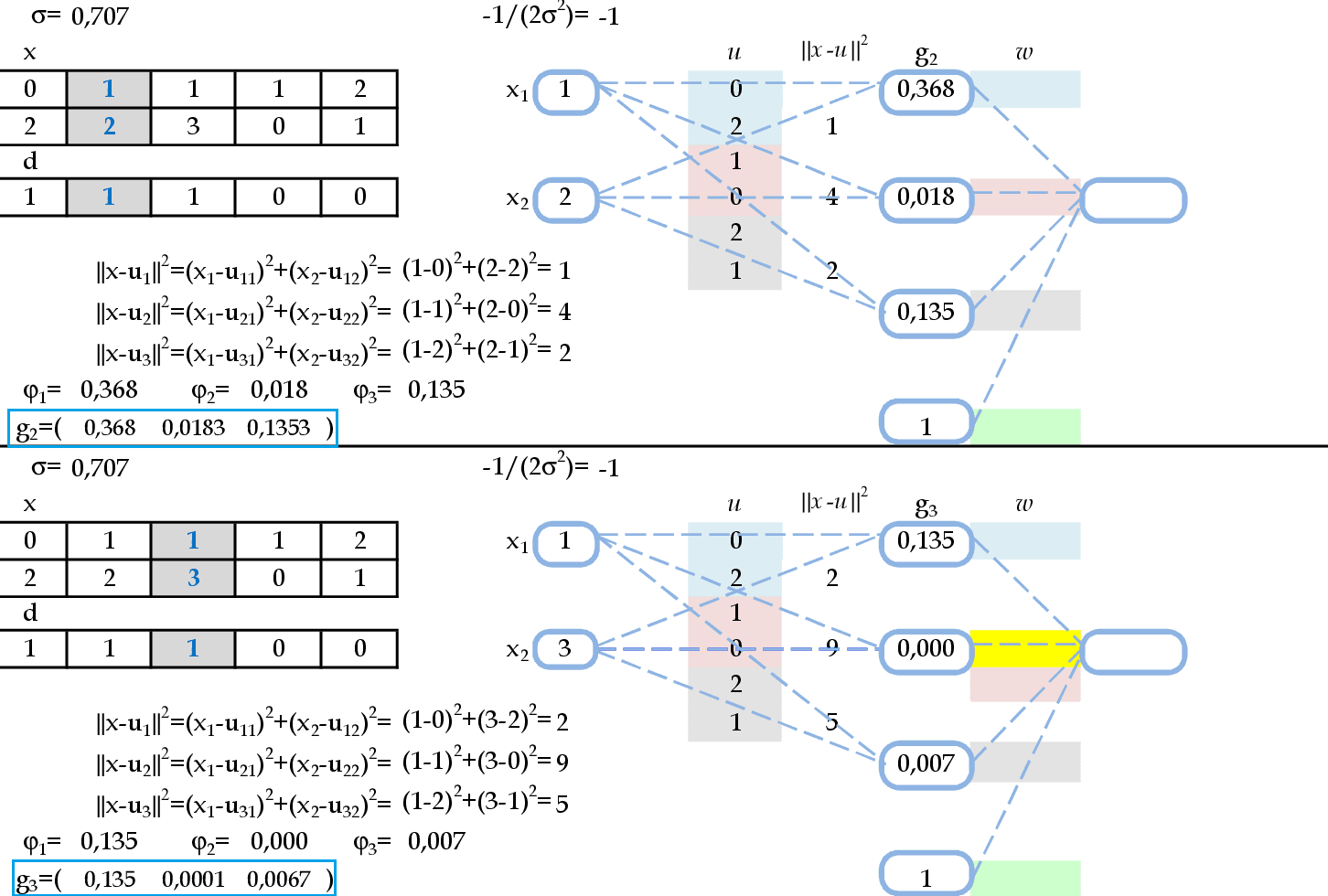
Agora temos as apresentações dos padrões de entrada (1, 2) e (1, 3). O resultado da ativação de cada neurônio da camada escondida será guardado nas linhas da matriz G: g2 e g3. -
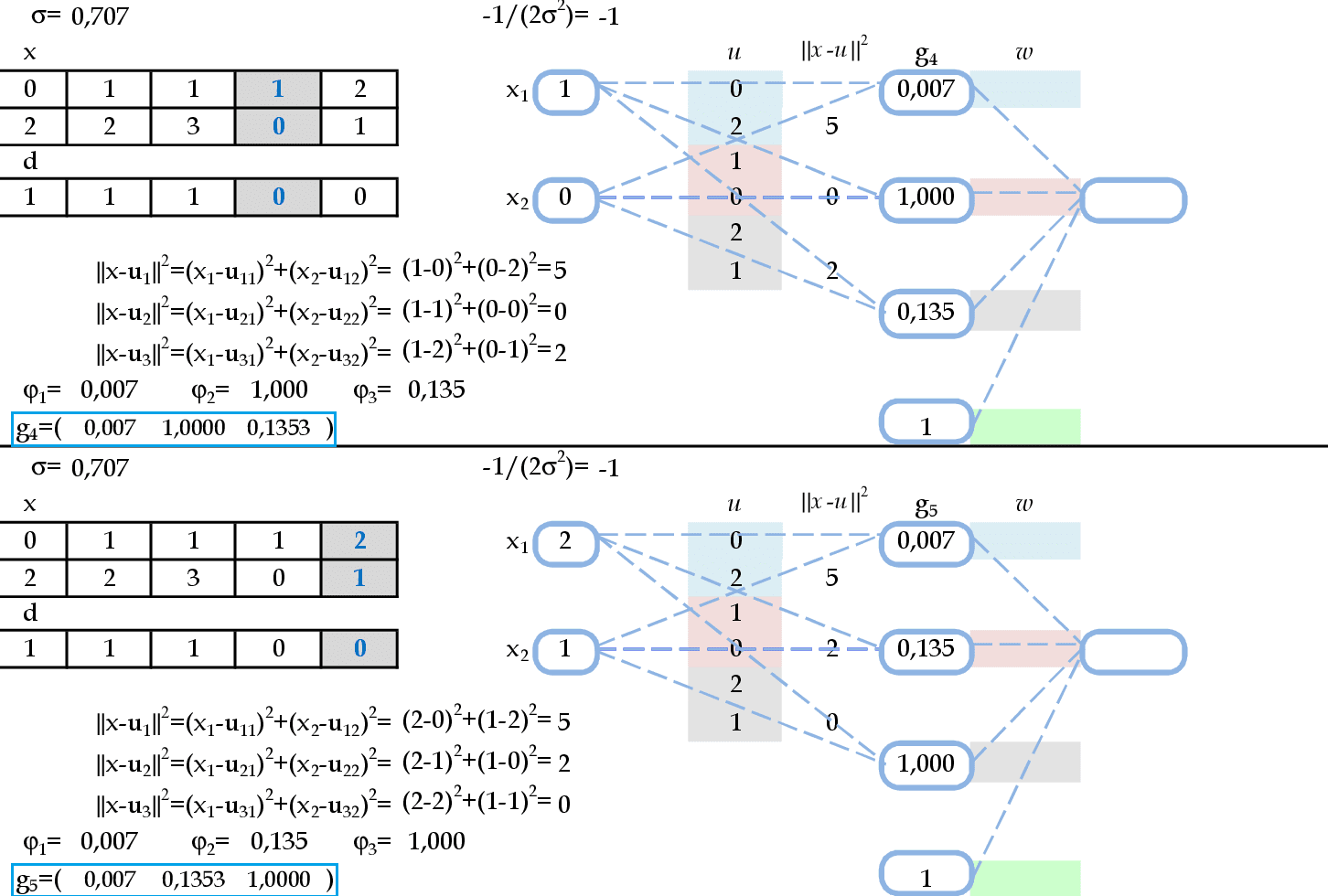
Agora temos as apresentações dos padrões de entrada (1, 0) e (2, 1). O resultado da ativação de cada neurônio da camada escondida será guardado nas linhas da matriz G: g4 e g5. -

Agora podemos calcular o vetor de pesos usando a matriz G. Note que a quarta coluna desta matriz tem valores iguais a 1, pois são as ativações de θ. Temos o vetor de pesos calculado da seguinte maneira: w = (GTG)-1GTd. -
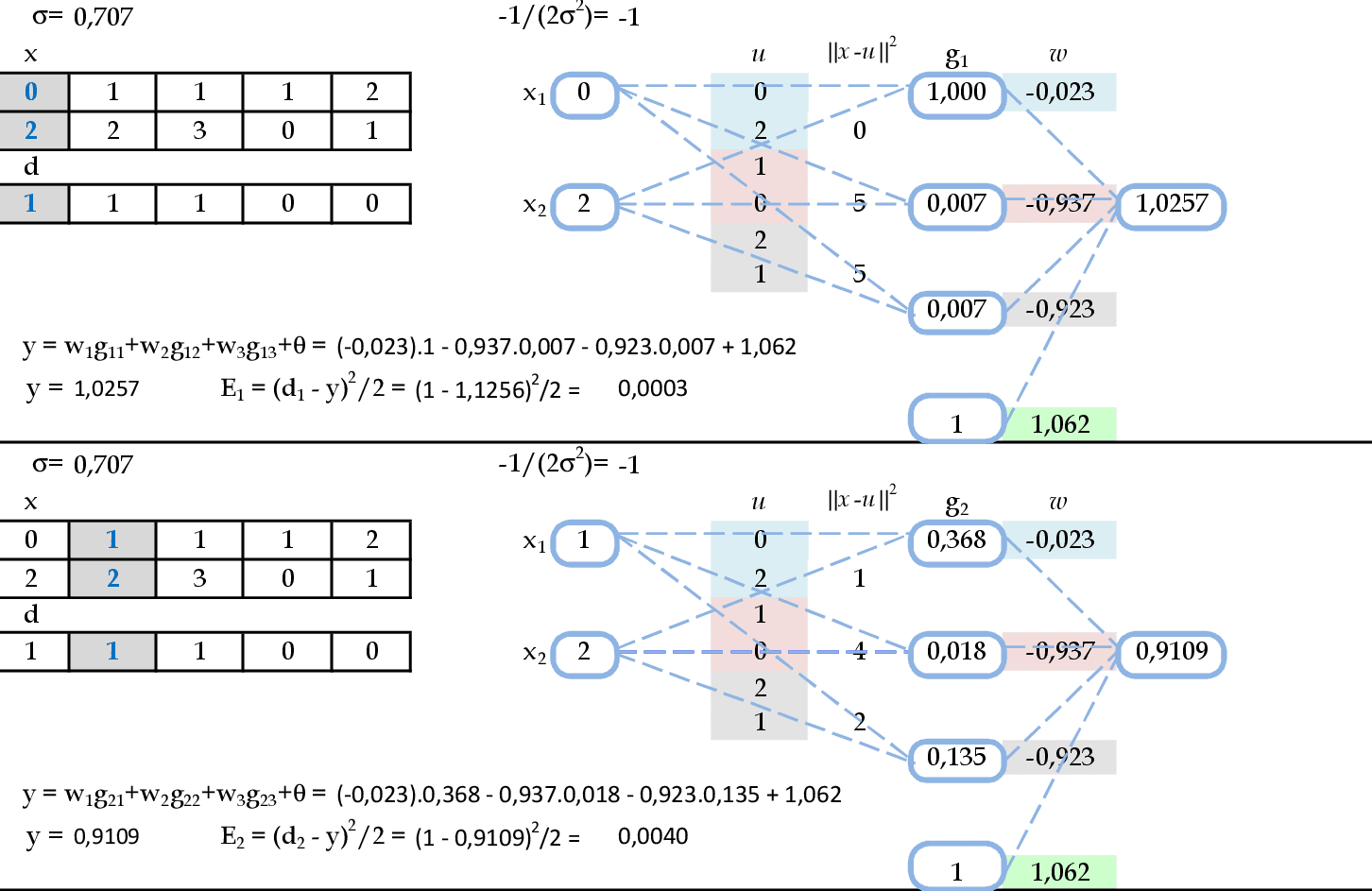
Podemos calcular as saídas e os erros quadráticos desta rede para os dois primeiros padrões de entrada: y = w1φ1 + w2φ2 + w3φ3 + θ e Ek = (dk − y)2)/2. -
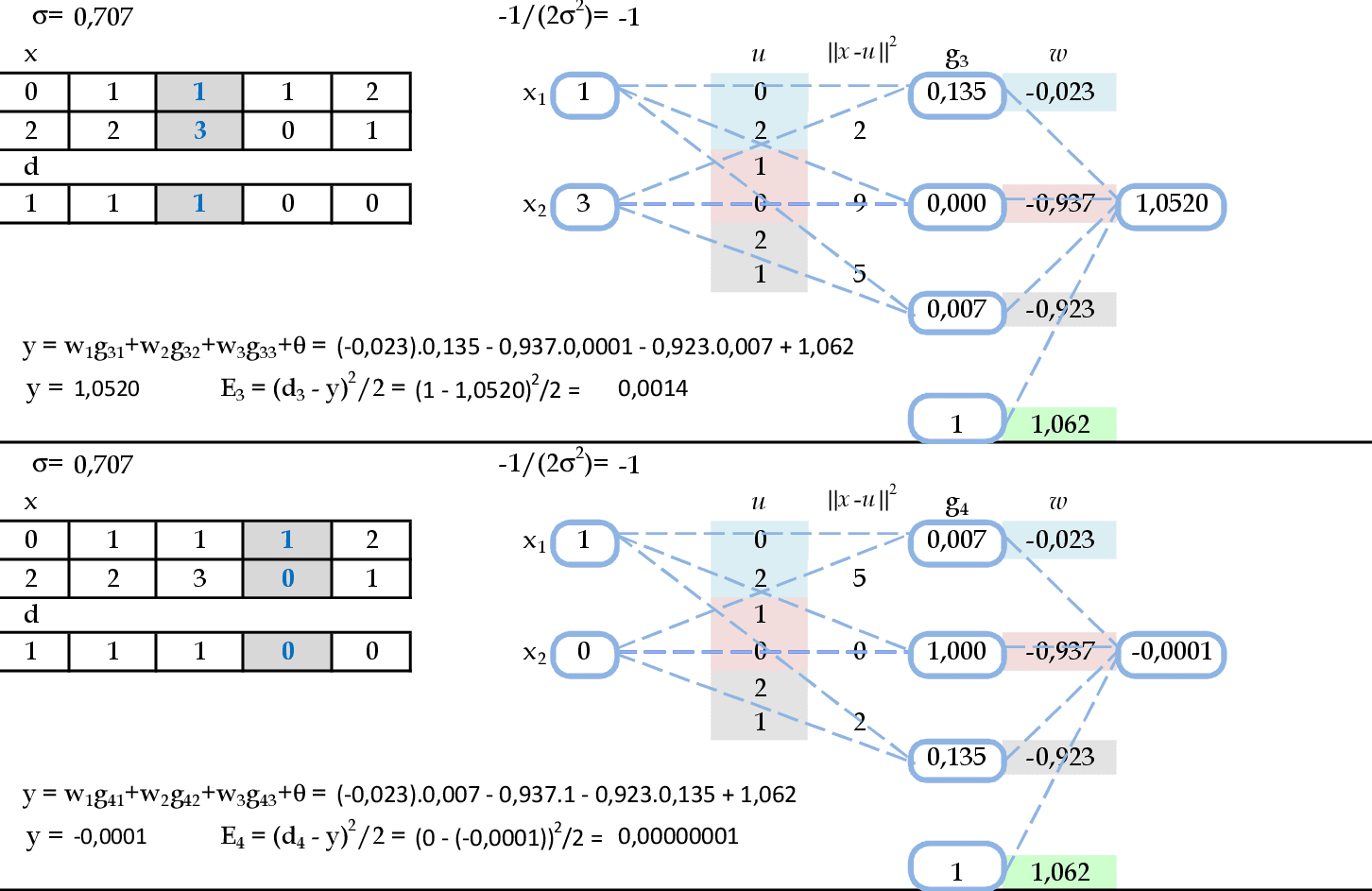
Seguem os cálculos das saídas e os erros quadráticos desta rede para mais dois padrões de entrada. -
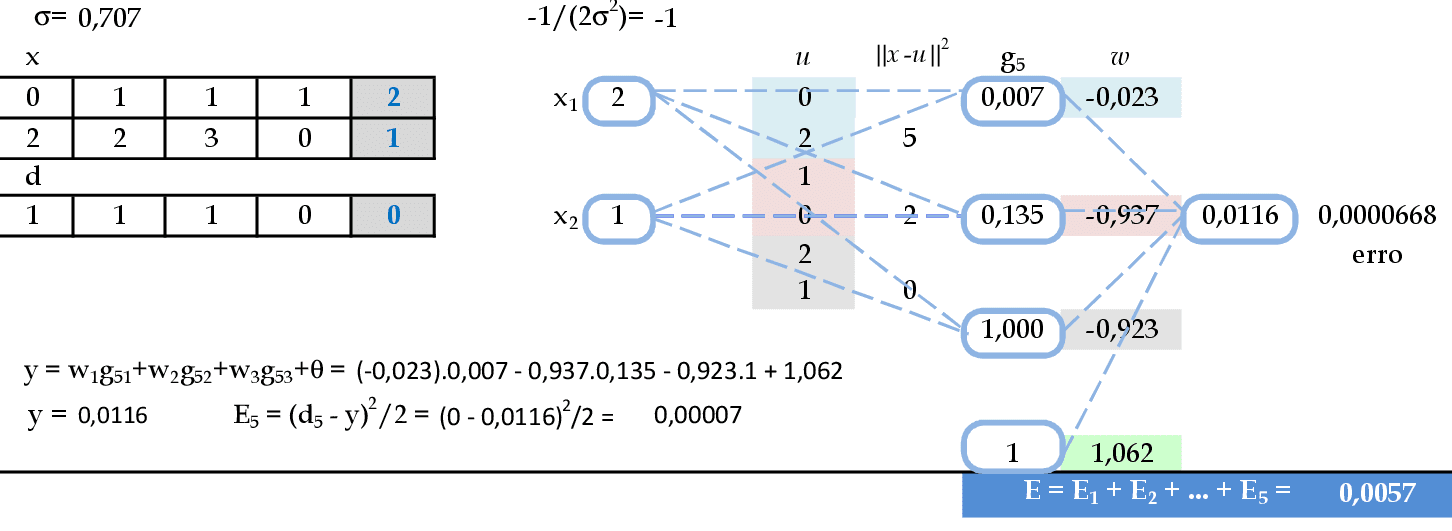
Para finalizar, são mostrados os cálculos da saída e do erro quadrático da rede para o último padrão de entrada. O erro quadrático total desta RBF ficou em E = 0,0057.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões da função "OU EXCLUSIVO" com a rede neural Radial Basis Function (RBF). Vamos utilizar 2 centros.
-
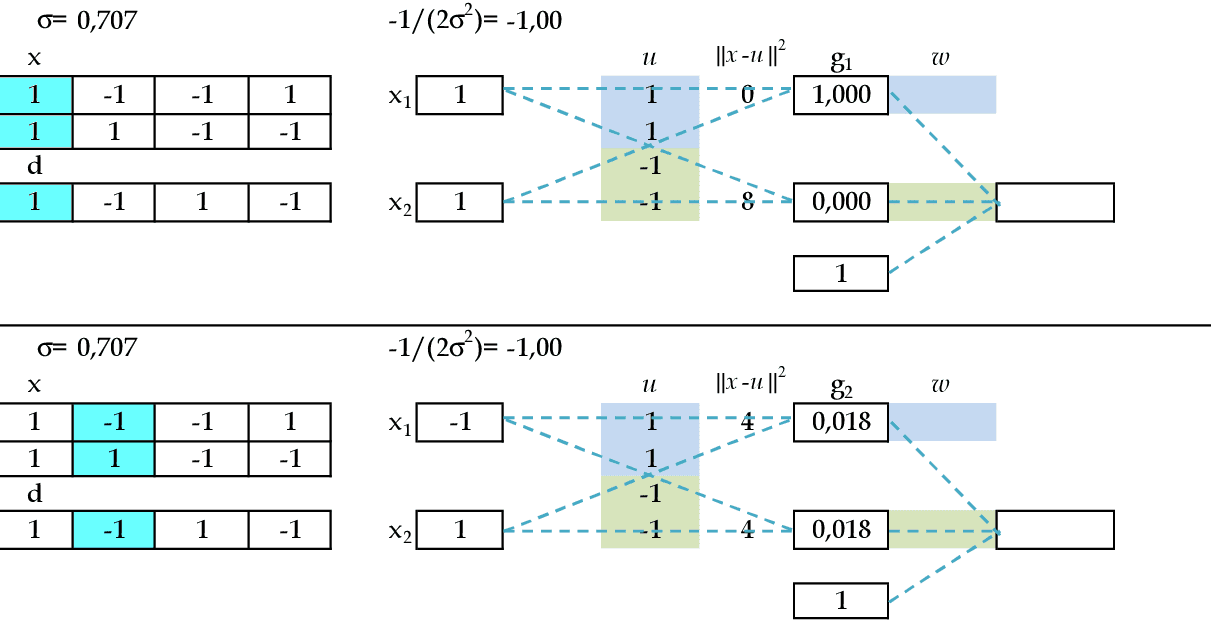
Vamos começar com a apresentação dos padrões de entrada (x1, x2) = (1, 1) e (-1, 1), com σ = $\mathsf{\sqrt {0,5}}$. O resultado da ativação de cada neurônio da camada escondida será guardado nas duas primeiras linha da matriz G: g1 e g2. -
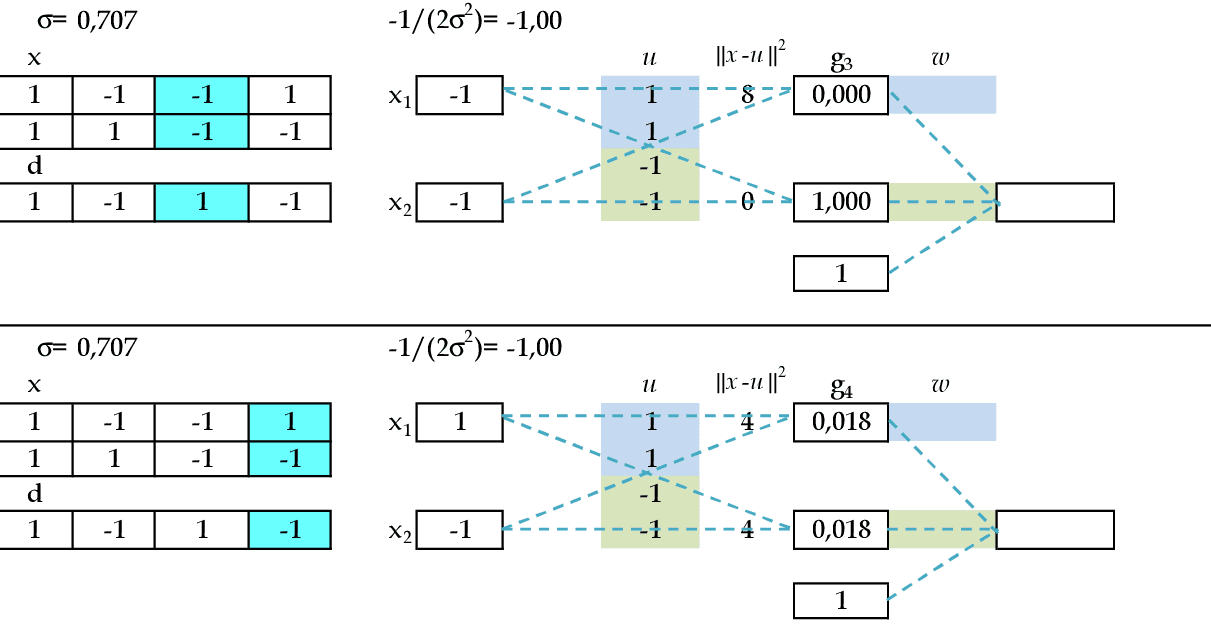
Agora temos as apresentações dos padrões de entrada (-1, -1) e (1, -1). O resultado da ativação de cada neurônio da camada escondida será guardado nas linhas da matriz G: g3 e g4. -
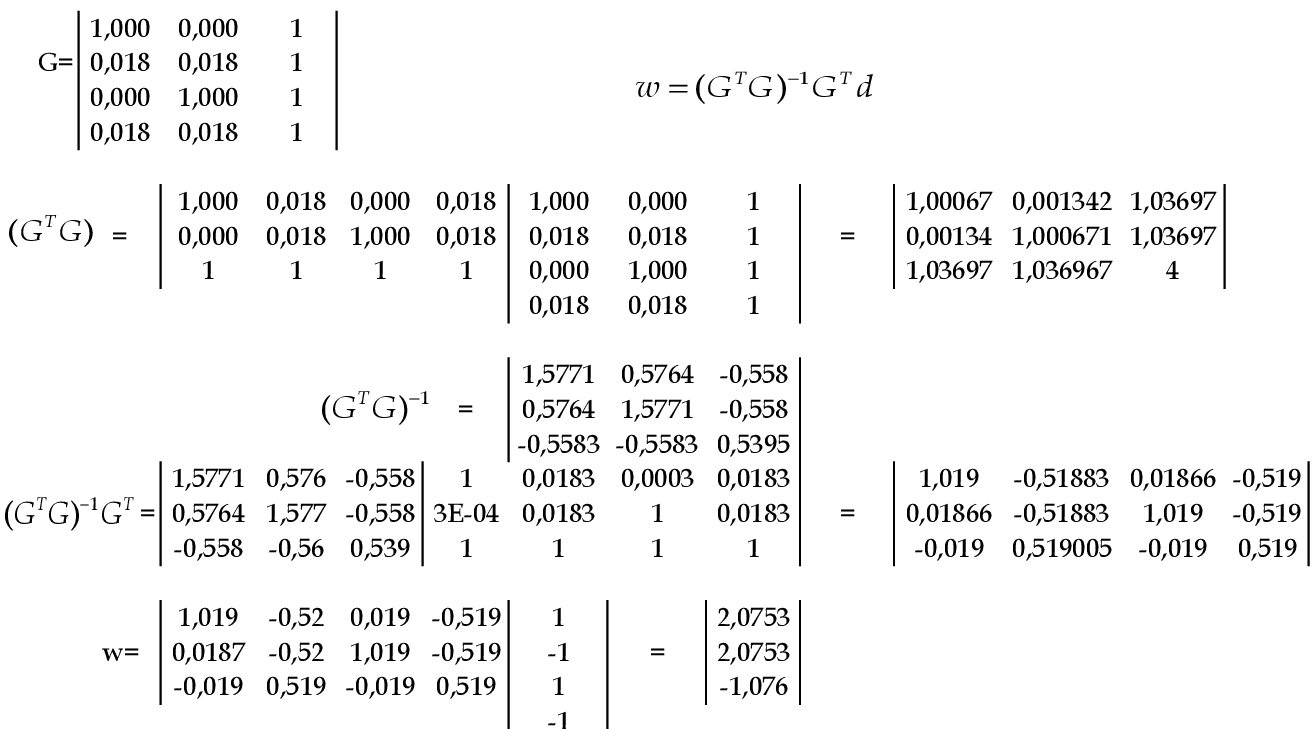
Agora podemos calcular o vetor de pesos usando a matriz G. Note que a terceira coluna desta matriz tem valores iguais a 1, pois são as ativações de θ. Temos o vetor de pesos calculado da seguinte maneira: w = (GTG)-1GTd. -

Podemos calcular as saídas e os erros quadráticos desta rede para os dois primeiros padrões de entrada: y = w1φ1 + w2φ2 + θ e Ek = (dk − y)2)/2. -

Temos que o erro é igual a ZERO para este problema de classificação usando a RBF de 2 centros.


5. Redes de Hebb e Mapas auto-organizáveis
Material das páginas 49 até 59.

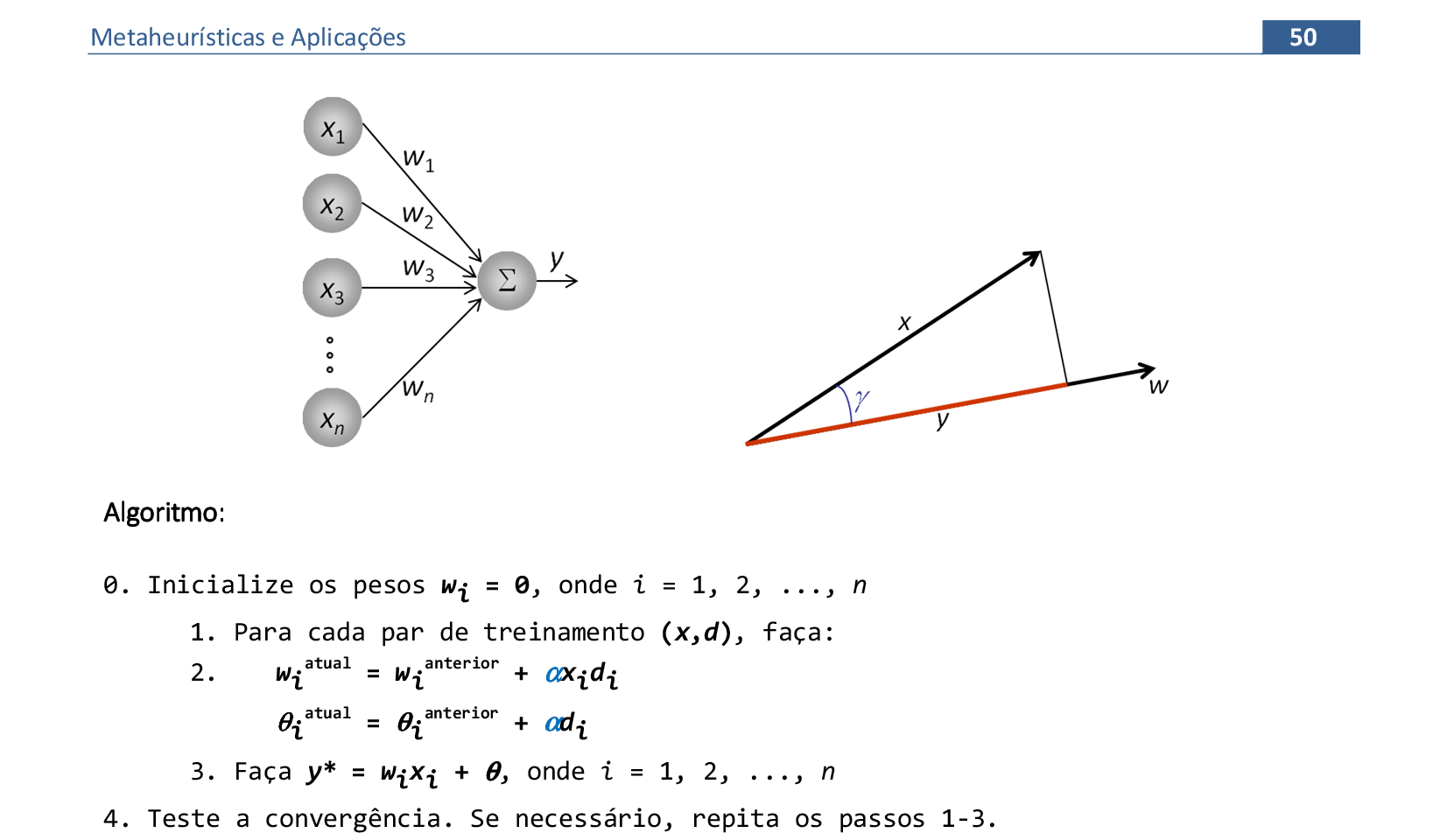
📃 Algoritmo comentado
0. Inicialize os pesos wi = 0, onde i = 1, 2, ..., n
1. Para cada par de treinamento (x,d), faça:
2. wiatual = wianterior + αxidi
θiatual = θianterior + αdi
3. Faça y* = wixi + θ, onde i = 1, 2, ..., n
4. Teste a convergência. Se necessário, repita os passos 1-3.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões da função "OU" utilizando a rede neural de Hebb, com α = 1.
-
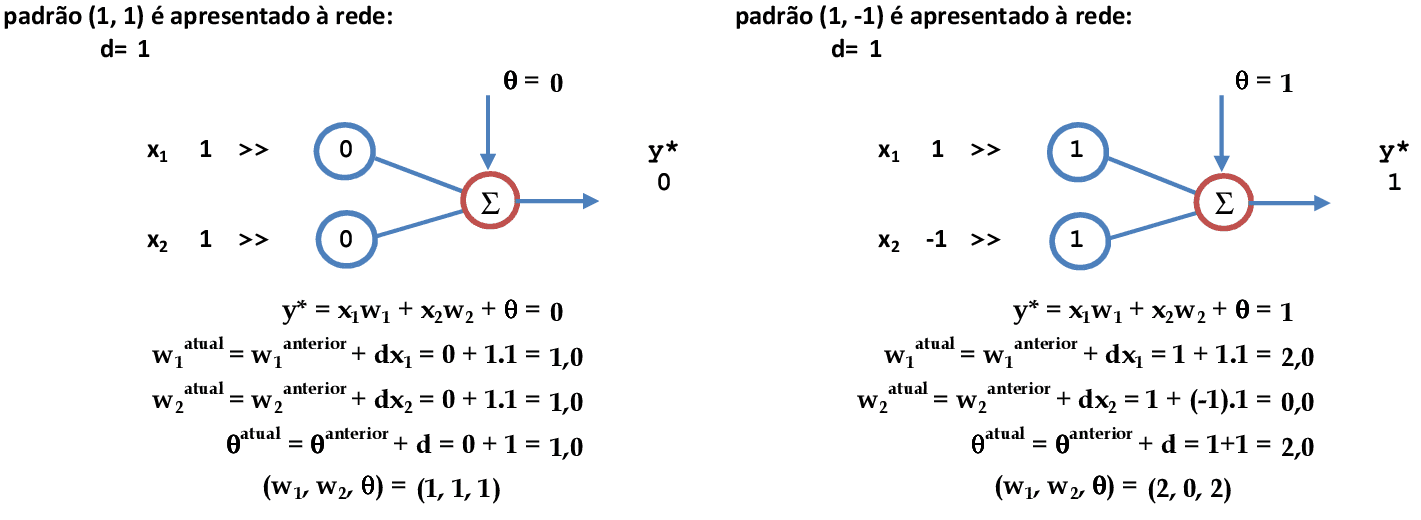
Vamos começar com a apresentação dos padrões de entrada (x1, x2) = (1, 1) e (1, -1) para a rede. As atualizações dos pesos são automáticas e produzem o vetor (w1, w2, θ) = (2, 0, 2). -

Continuando a apresentação dos padrões de entrada: (-1, 1) e (-1, -1). As atualizações dos pesos produzem o vetor (w1, w2, θ) = (2, 2, 2). -

Ao final da 1ª iteração, temos todos os padrões classificados corretamente. Logo, o treinamento pode ser finalizado.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões com a rede neural de Hebb, com α = 1. Precisamos deixar os padrões de entrada no intervalo [-1, 1] para que a rede de Hebb funcione corretamente.
-
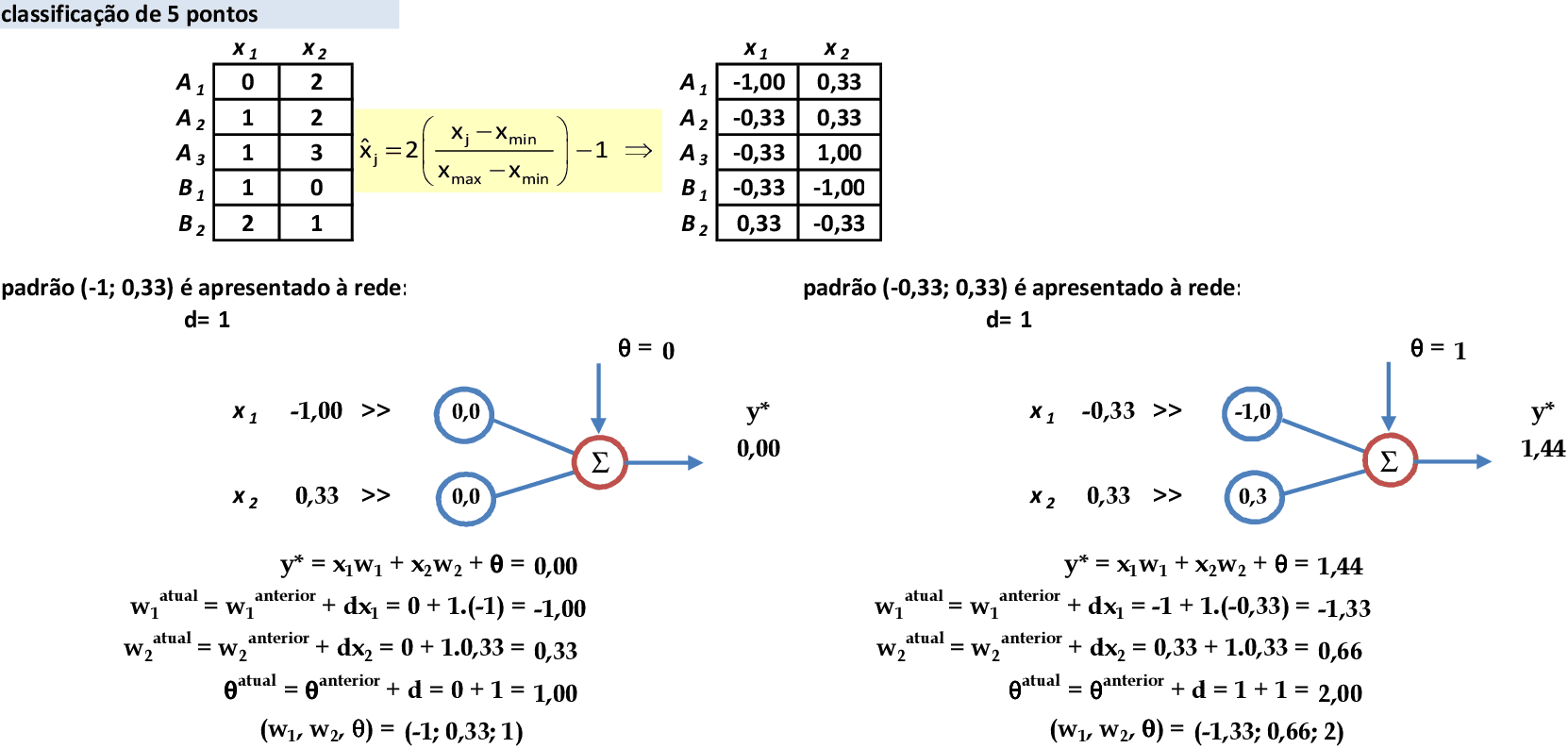
Vamos começar com a apresentação dos padrões de entrada (x1, x2) = (-1, 0.33) e (-0.33, 0.33) para a rede. As atualizações dos pesos são automáticas e produzem o vetor (w1, w2, θ) = (-1.33, 0.66, 2). -
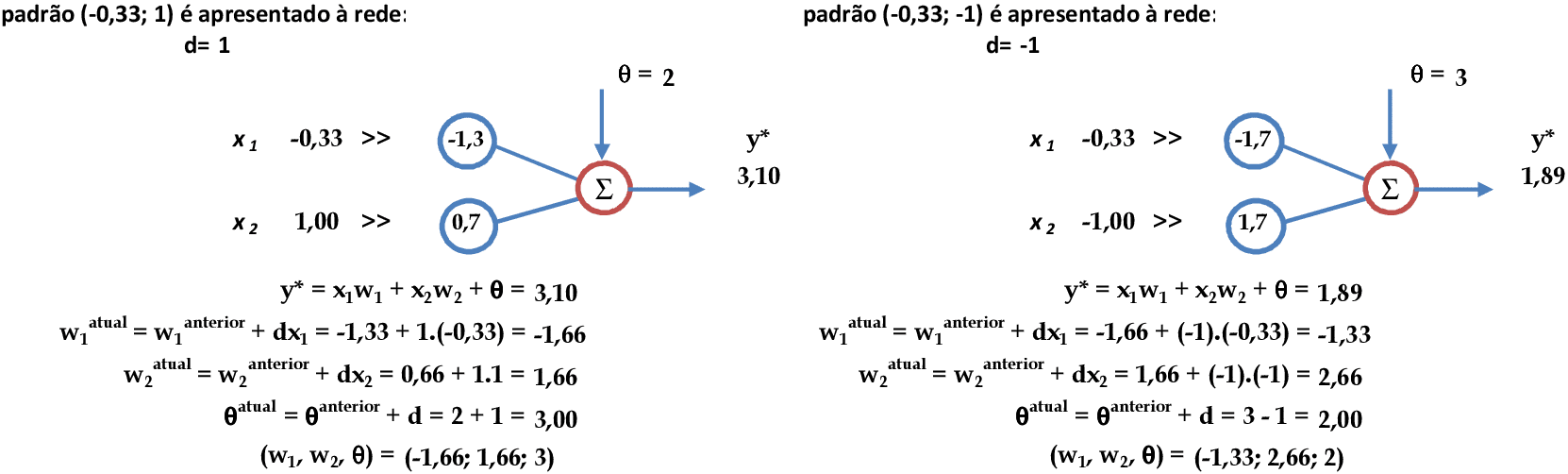
Continuando a apresentação dos padrões de entrada: (-0.33, 1) e (-0.33, -1). As atualizações dos pesos produzem o vetor (w1, w2, θ) = (-1.33, 2.66, 2). -
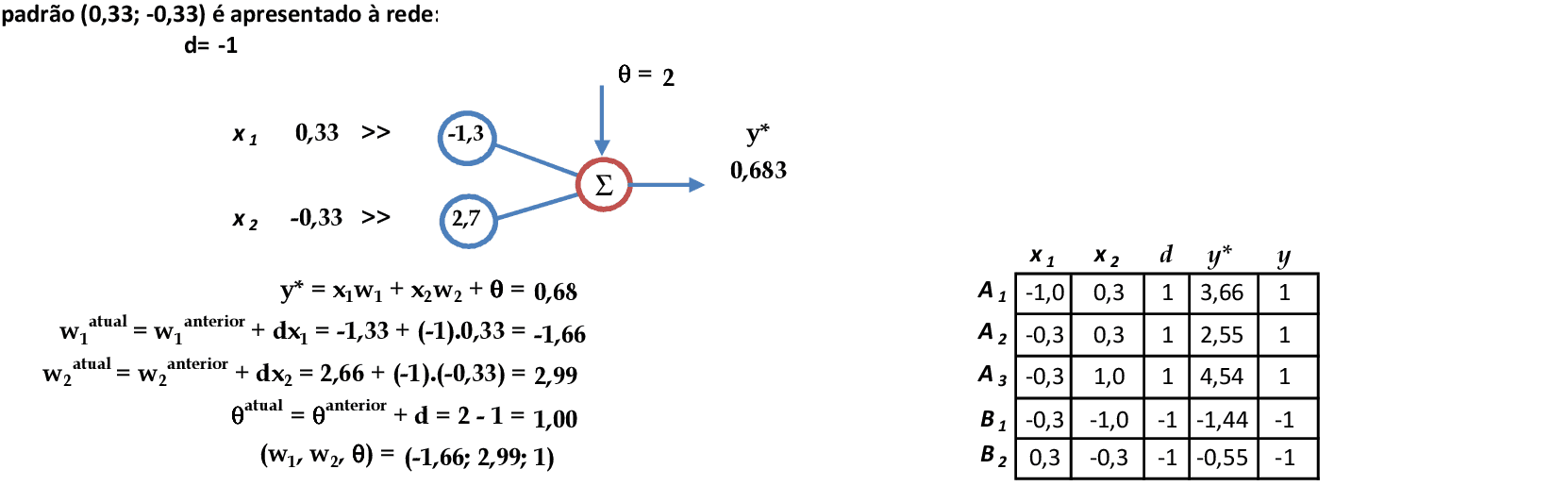
Ao final da 1ª iteração, o vetor de pesos (w1, w2, θ) = (-1.66, 2.99, 1). Todos os padrões são classificados corretamente, e o treinamento da rede pode ser finalizado.


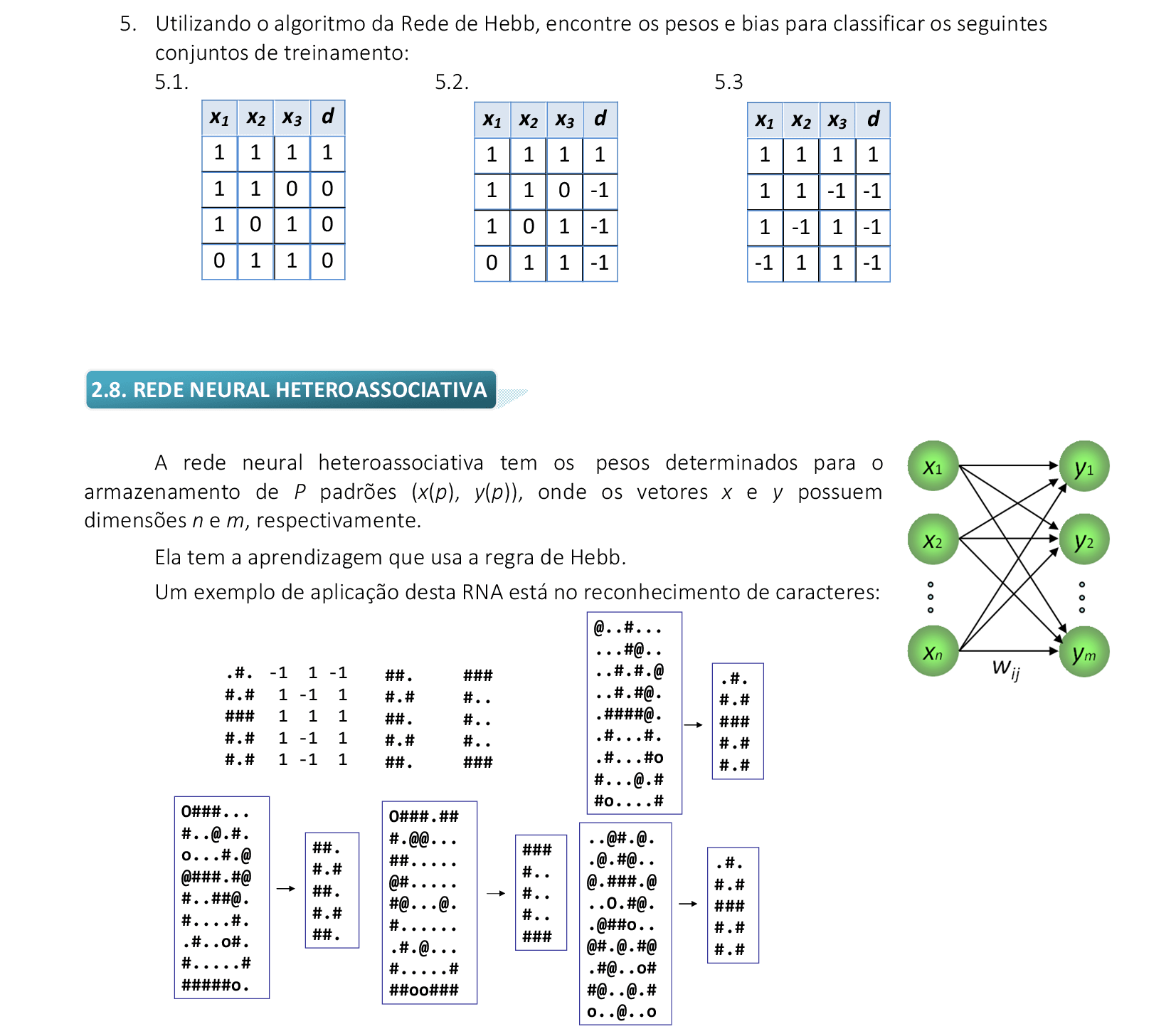

📃 Algoritmo comentado
0. Inicialize os pesos wij = 0, onde i = 1, 2, ..., n, j = 1, 2, ..., m.
1. Para cada par de treinamento (x,d), faça os passos 2-4:
2. yj* = ∑ixiwij
3. Se yj* > 0, yj = 1
Se yj* = 0, yj = 0
Se yj* < 0, yj = -1
4. wijatual = wijanterior + αxidi
5. Reduza α e teste a convergência. Se necessário, repita os passos de 1-4.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de classificação de padrões com a rede neural Heteroassociativa, com α = 1.
-
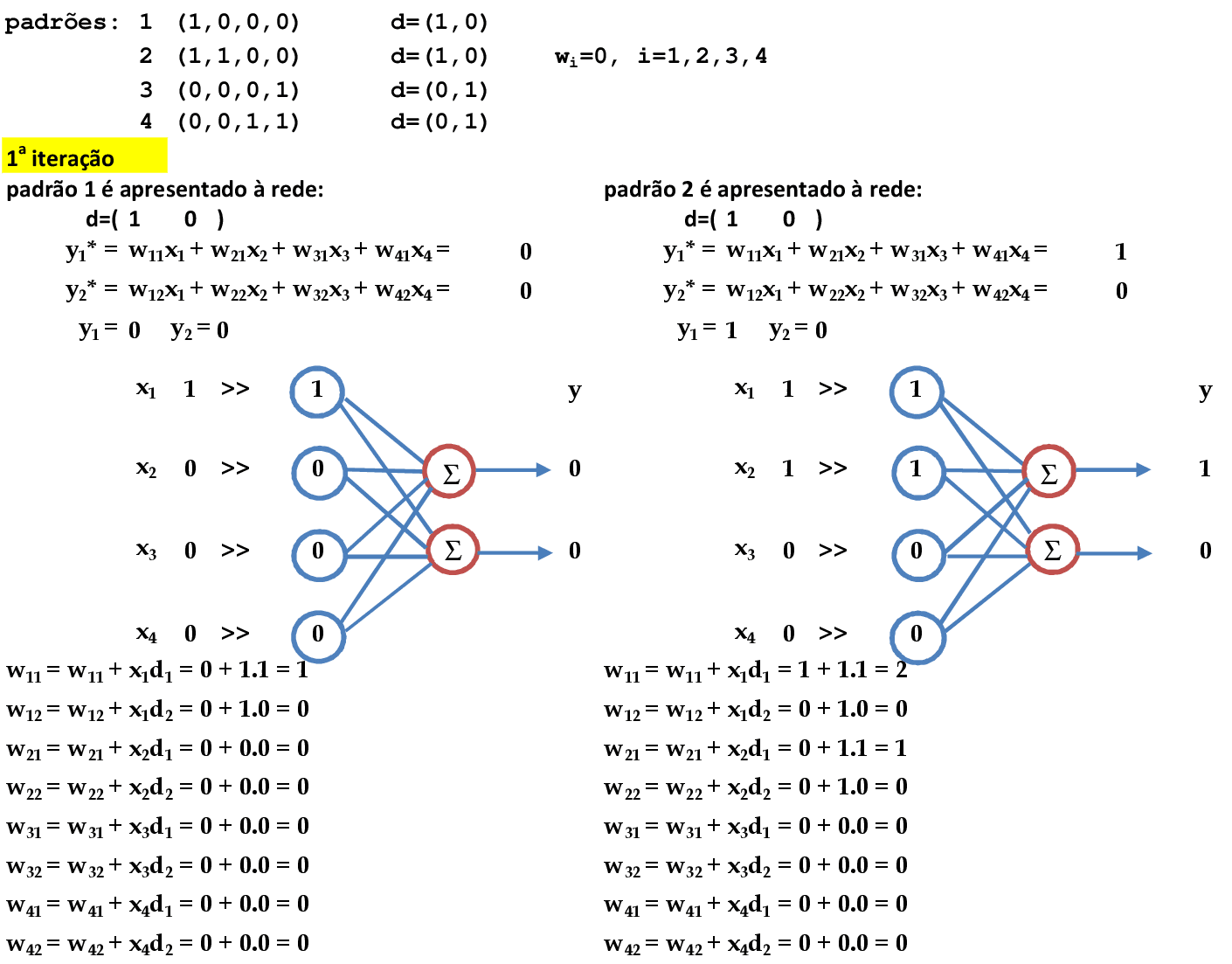
Vamos começar com a apresentação dos padrões de entrada (x1, x2, x3, x4) = (1, 0, 0, 0) e (1, 1, 0, 0) para a rede. As atualizações dos pesos são automáticas e produzem a matriz de pesos indicada wij, com i = 1, 2, 3, 4 e j = 1, 2. -
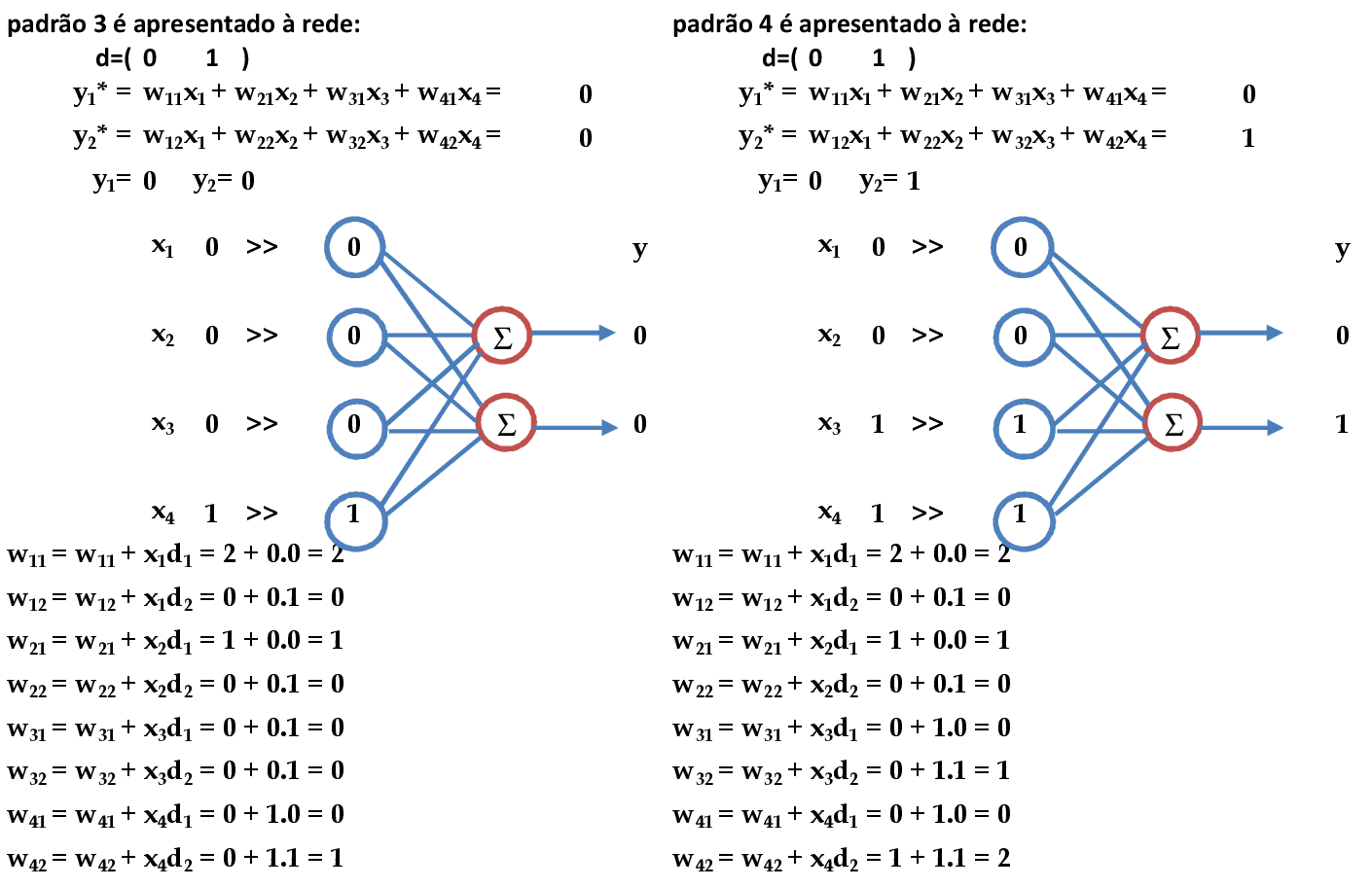
Continuando a apresentação dos padrões de entrada: (0, 0, 0 ,1) e (0, 0, 1, 1). As atualizações dos pesos produzem a matriz de pesos indicada wij, com i = 1, 2, 3, 4 e j = 1, 2. -

Multiplicando-se a matriz de pesos W pelos vetores dos dados de entrada, temos o reconhecimento destes padrões. O processo de treinamento desta rede pode ser finalizado.





📃 Algoritmo comentado
0. Iniciar os pesos dos n neurônios da rede com valores aleatórios baixos: wij
1. Apresentar cada entrada x para a rede, e executar os passos 2 e 3:
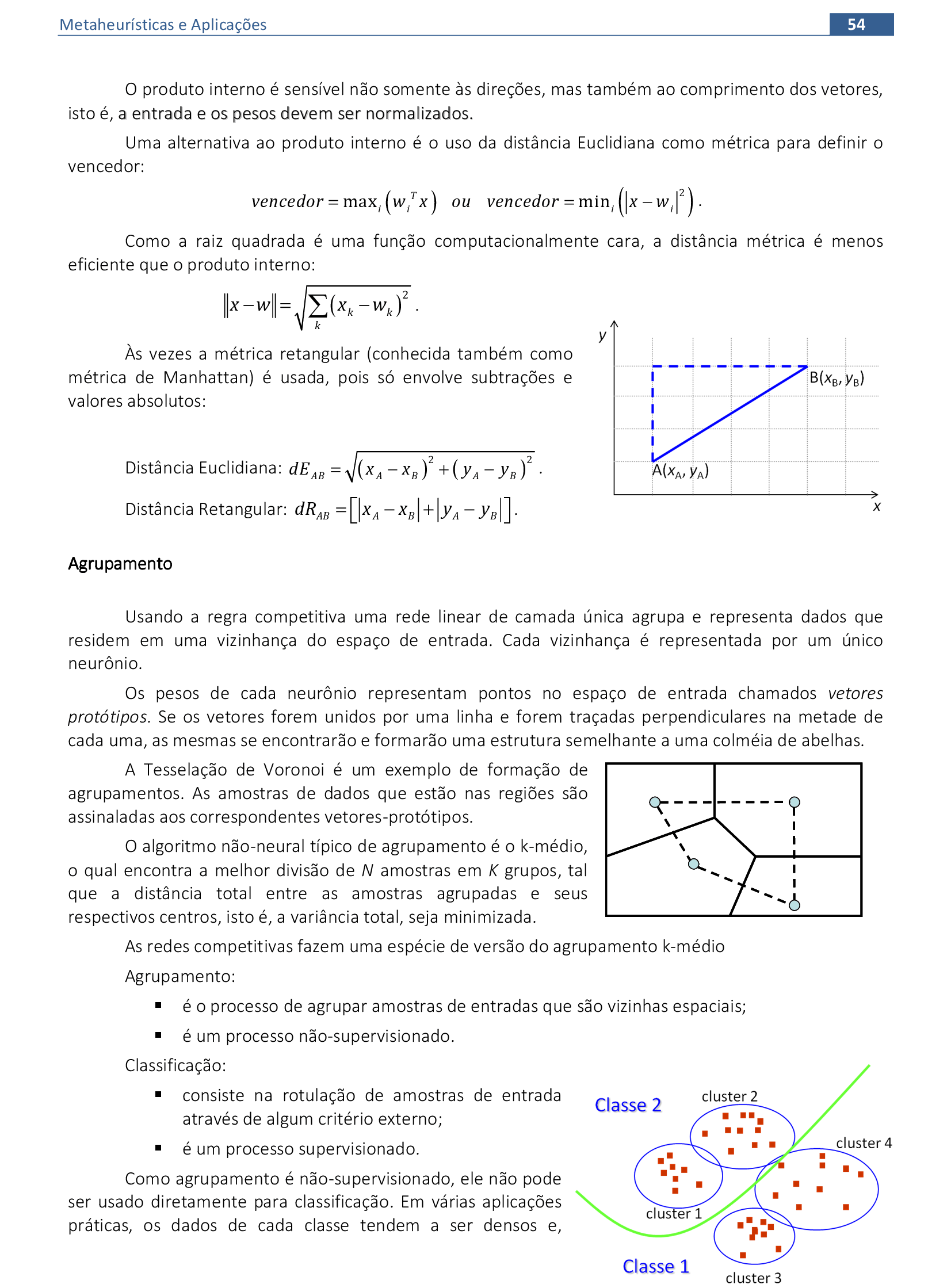
2. Determinar o neurônio i que possui a menor distância (euclidiana) do peso w com o vetor x.
di = ∑j=1n(xj − wij)2
Este neurônio é denominado “vencedor”.
3. Ajustar os pesos do neurônio vencedor e de todos os neurônios que pertencem a uma vizinhança
centrada nele, Vi.
wijatual = wijanterior + α[xj − wijanterior]
onde i ∈ Vi.
5. Ajustar a taxa de aprendizado α e o raio de vizinhança.
Se não existirem mais mudanças substanciais no mapa, pare; caso contrário, volte ao passo 1.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede de Kohonen, com α = 0,5. Temos um mapa com 4 neurônios em formato quadrado, e os dados com valores no intervalo [-1, 1], o que garante a convergência mais rápida da rede.
-

Vamos começar com a apresentação do padrão de entrada A(-0,15; 0,25). Calculamos as distâncias di entre as coordenadas deste padrão e as coordenadas wij dos pesos dos neurônios. O vencedor é o neurônio 2. -

Neste exemplo, vamos usar o treinamento "hard", que só atualiza o neurônio vencedor. -
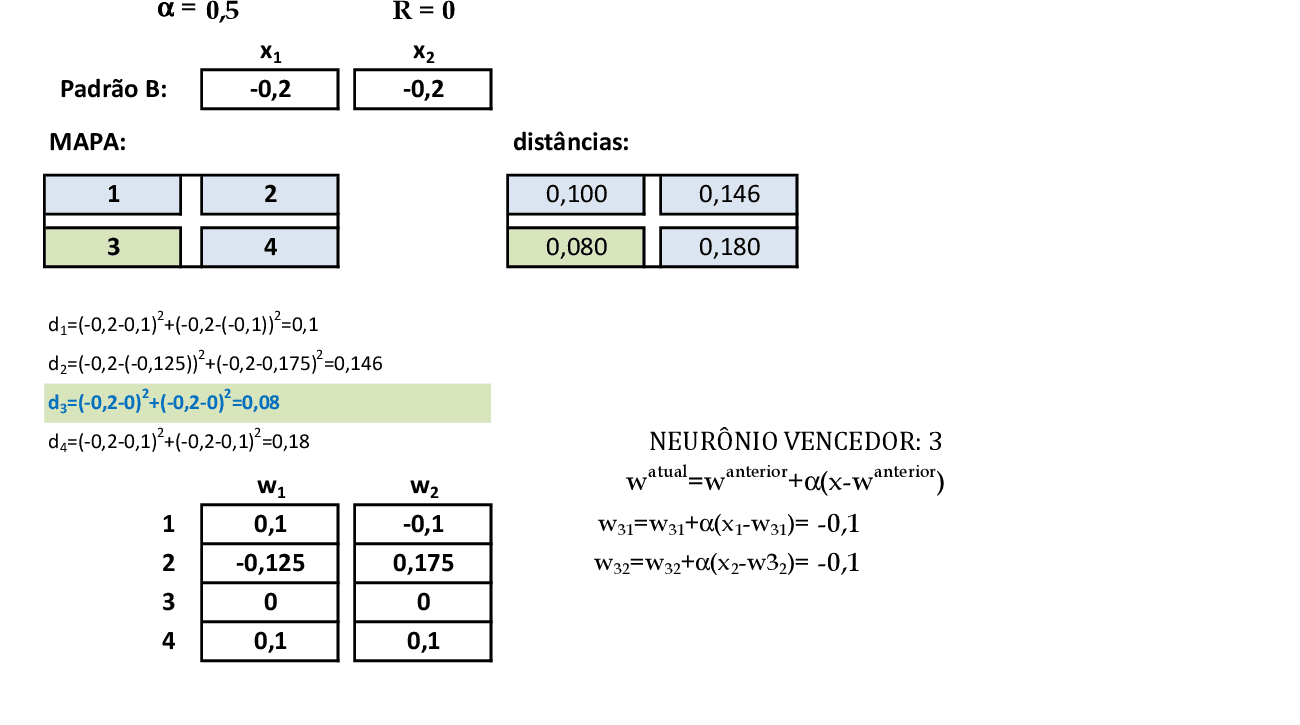
Na apresentação do padrão de entrada B(-0,2; -0,2), calculamos as distâncias di entre as coordenadas deste padrão e as coordenadas wij dos pesos dos neurônios. O vencedor é o neurônio 3, que é atualizado. -
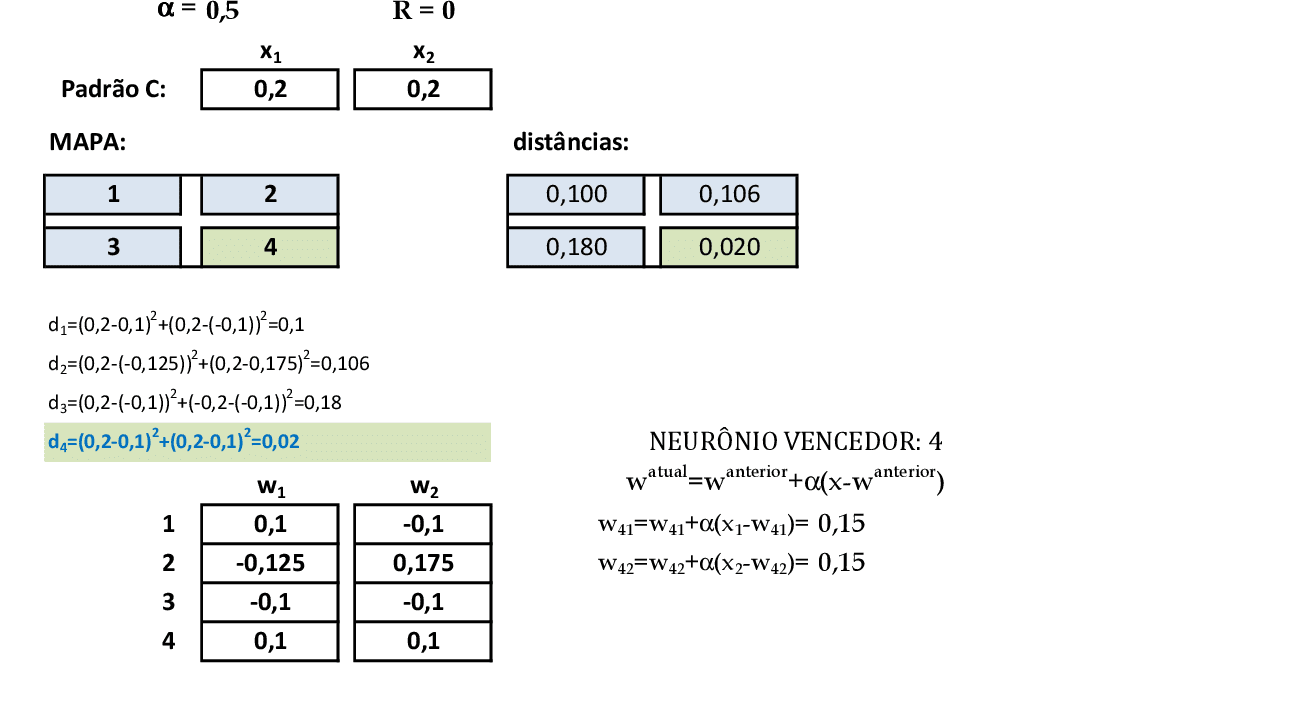
Quando apresentamos o padrão de entrada C(0,2; 0,2), temos que o neurônio vencedor é o 4, que tem seus pesos atualizados. -
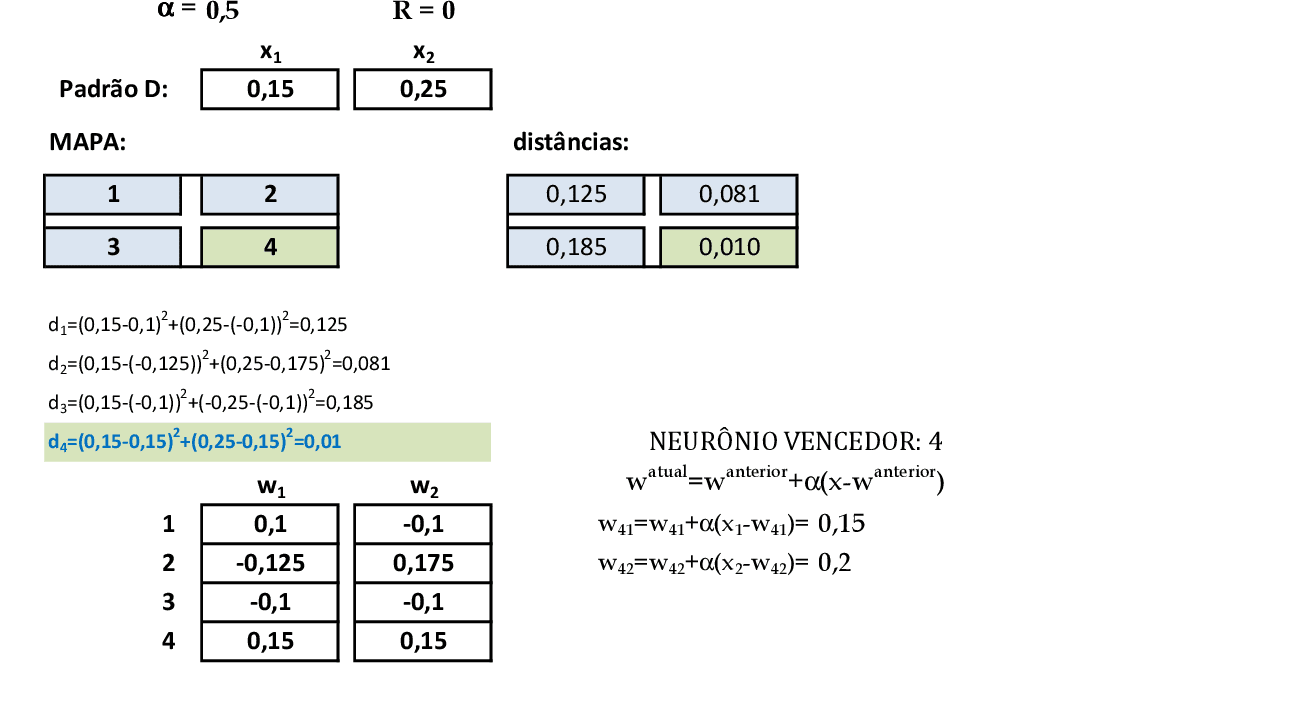
Quando apresentamos o padrão de entrada D(0,15; 0,25), temos que o neurônio vencedor é o 4, que tem seus pesos atualizados. -
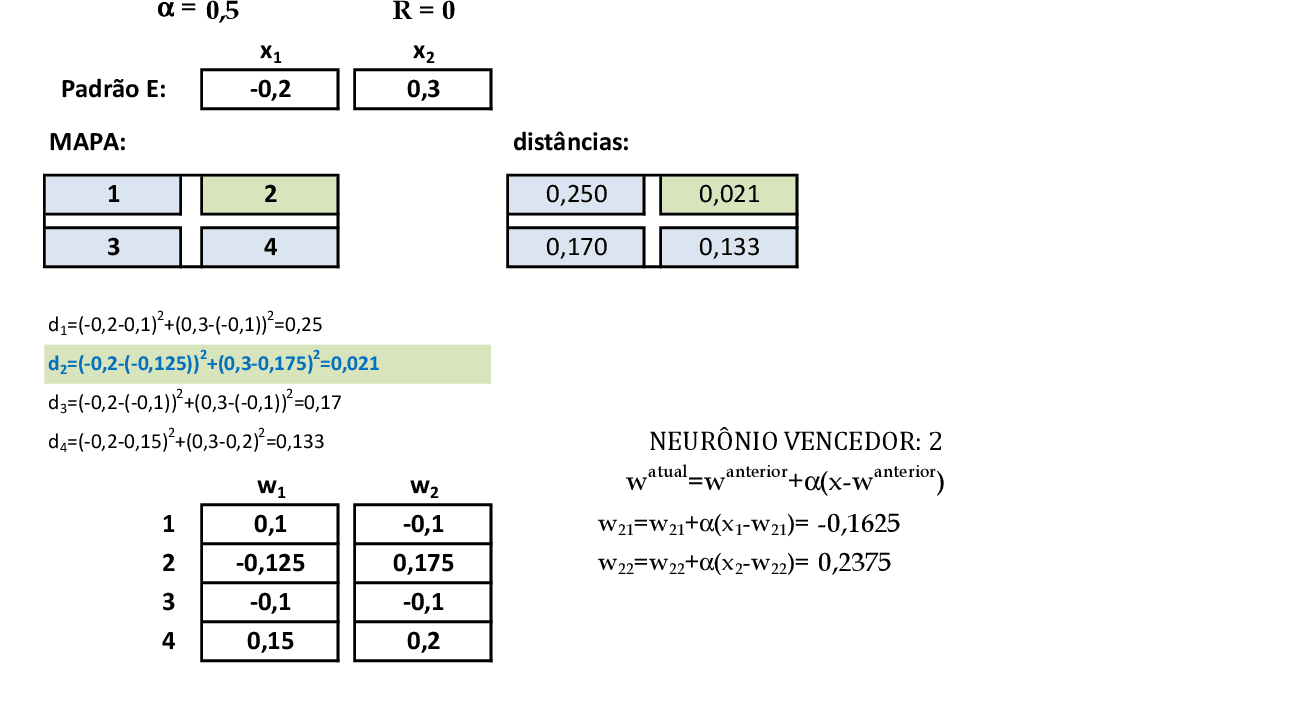
Quando apresentamos o padrão de entrada E(-0,2; 0,3), temos que o neurônio vencedor é o 2, que tem seus pesos atualizados. -
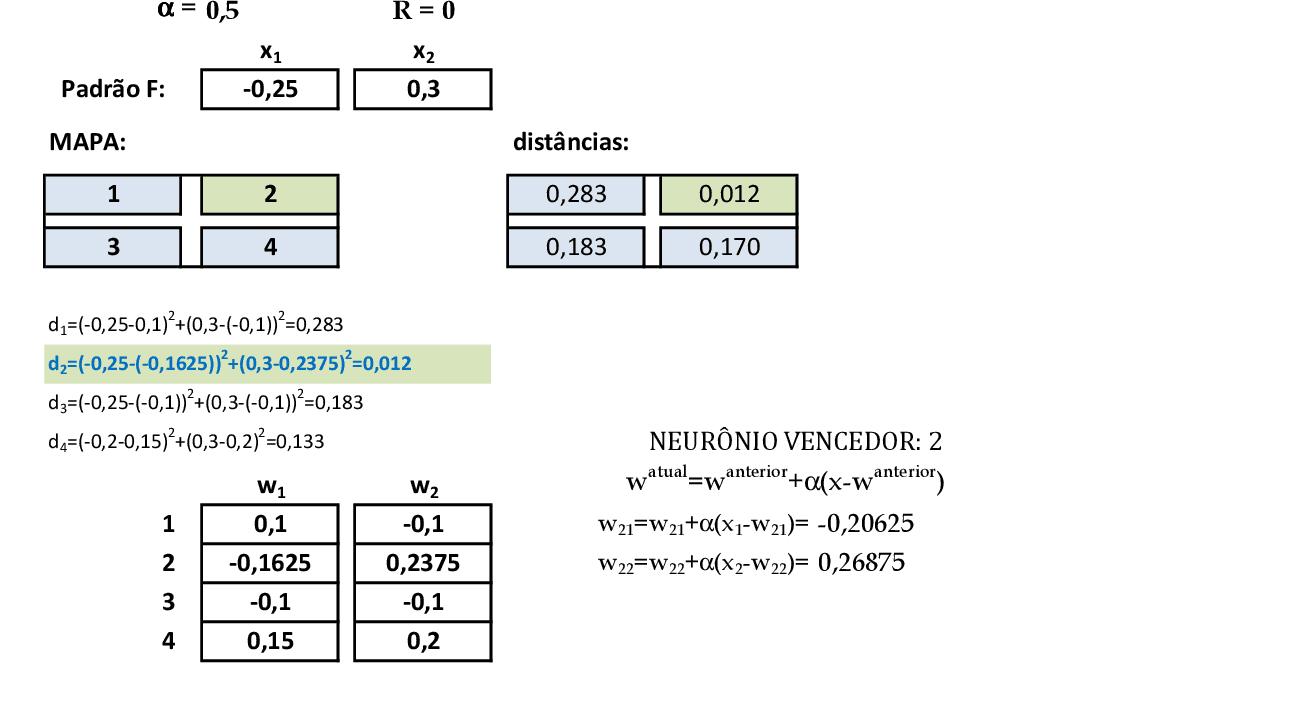
Quando apresentamos o padrão de entrada F(-0,25; 0,3), temos que o neurônio vencedor é o 2, que tem seus pesos atualizados. -
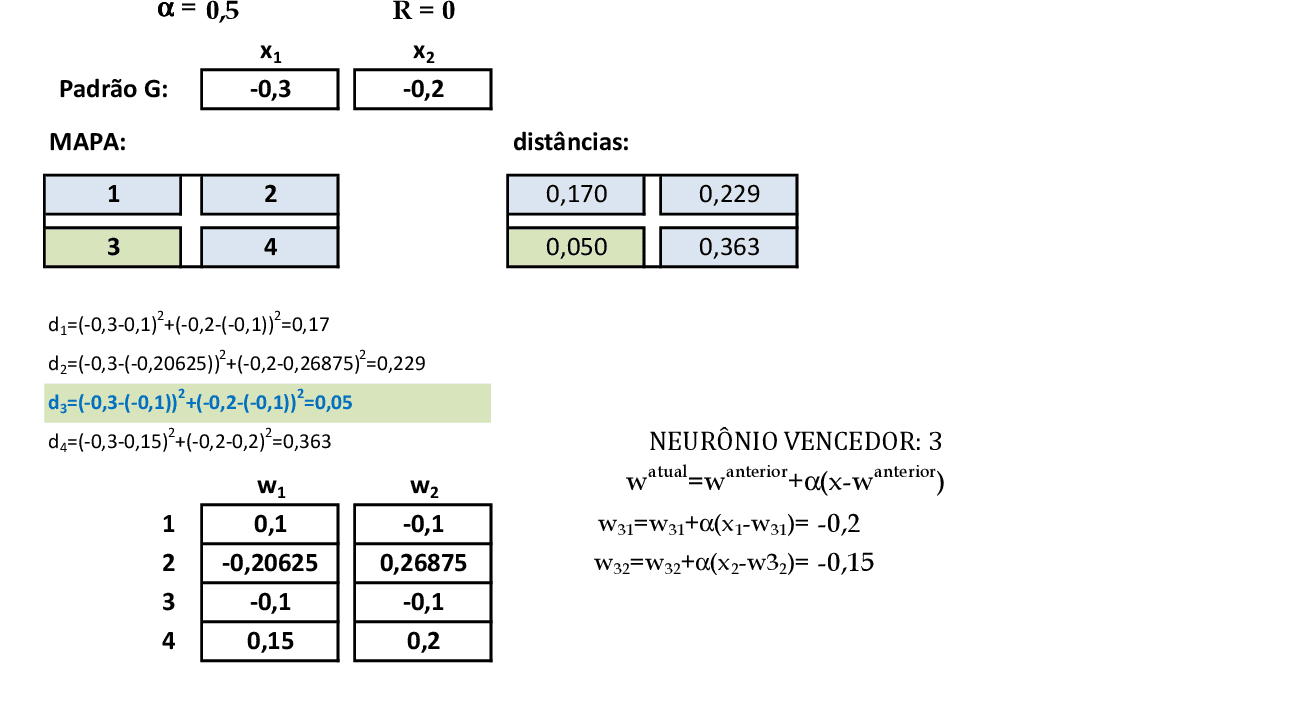
Quando apresentamos o padrão de entrada G(-0,3; -0,2), temos que o neurônio vencedor é o 3, que tem seus pesos atualizados. Finalizamos a primeira iteração. -
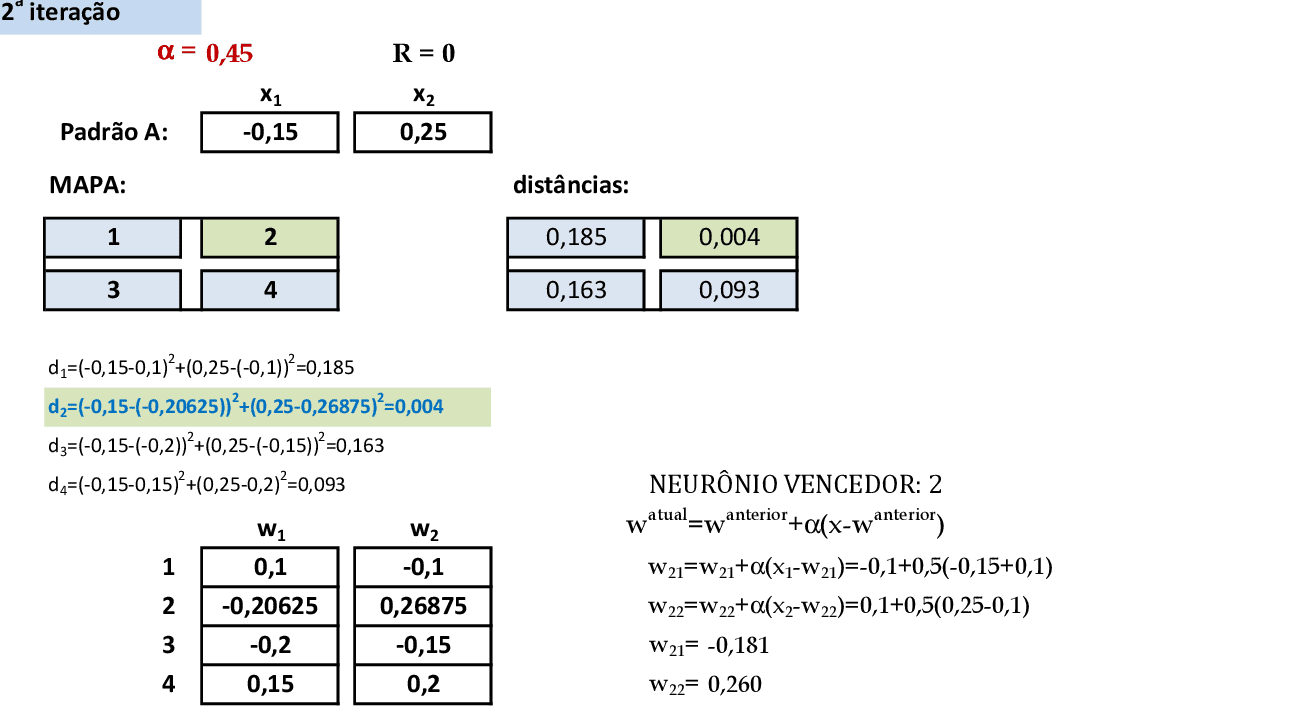
Na segunda iteração, reduzimos a taxa de aprendizagem α e apresentamos novamente os padrões de entrada para a rede. O critério de parada é a "convergência" da rede, ou seja, quando os pesos sofrem poucas modificações de uma iteração para outra.


6. Mapas auto-organizáveis e PCV
Material das páginas 59 até 66.

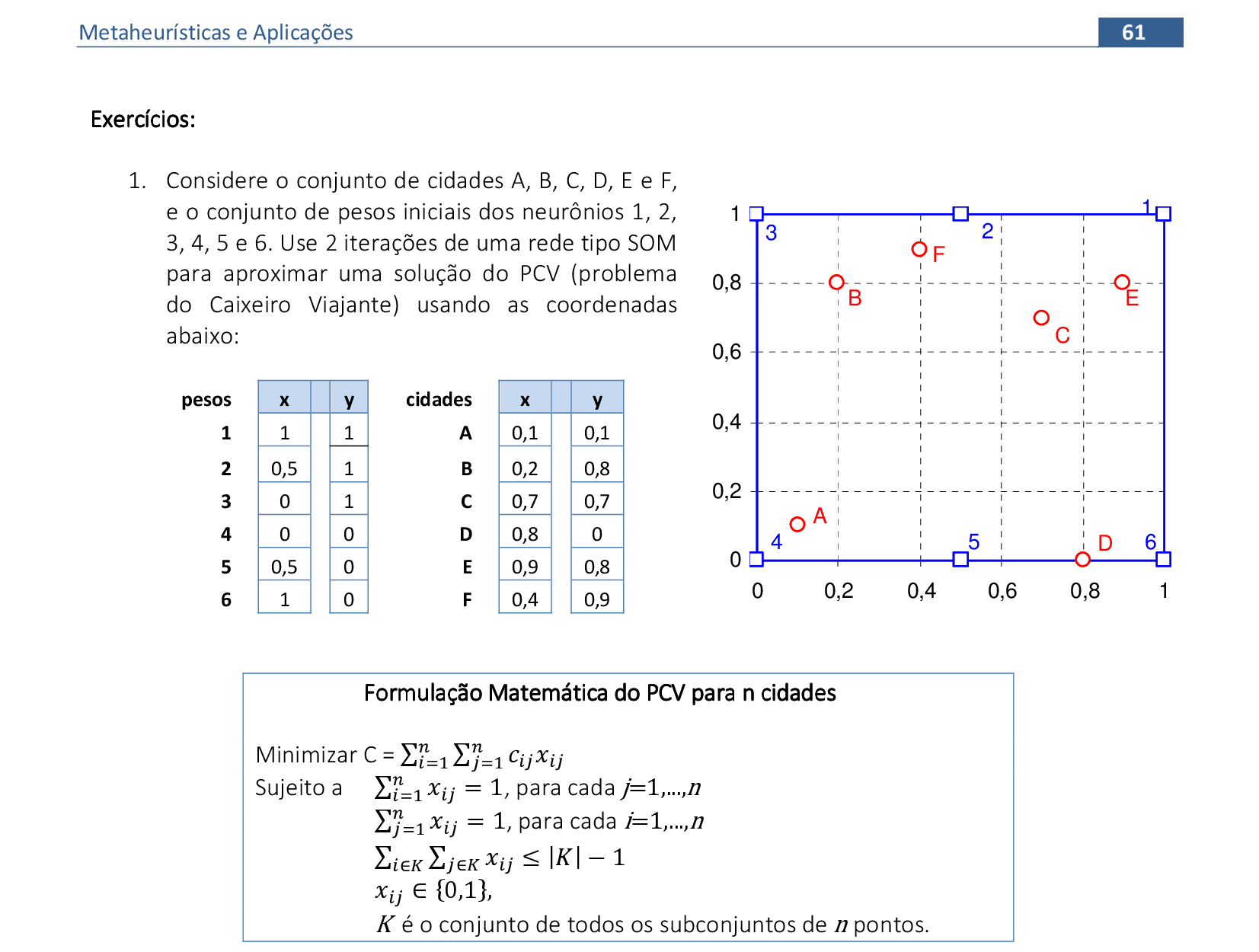
📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede de Kohonen para resolver o Problema do Caixeiro Viajante, com α = 0,5. Temos um mapa com 6 neurônios em formato retangular 2 x 3, e os dados com valores no intervalo [-1, 1], o que garante a convergência mais rápida da rede. O comprimento da rota inicial é igual a 4.
-
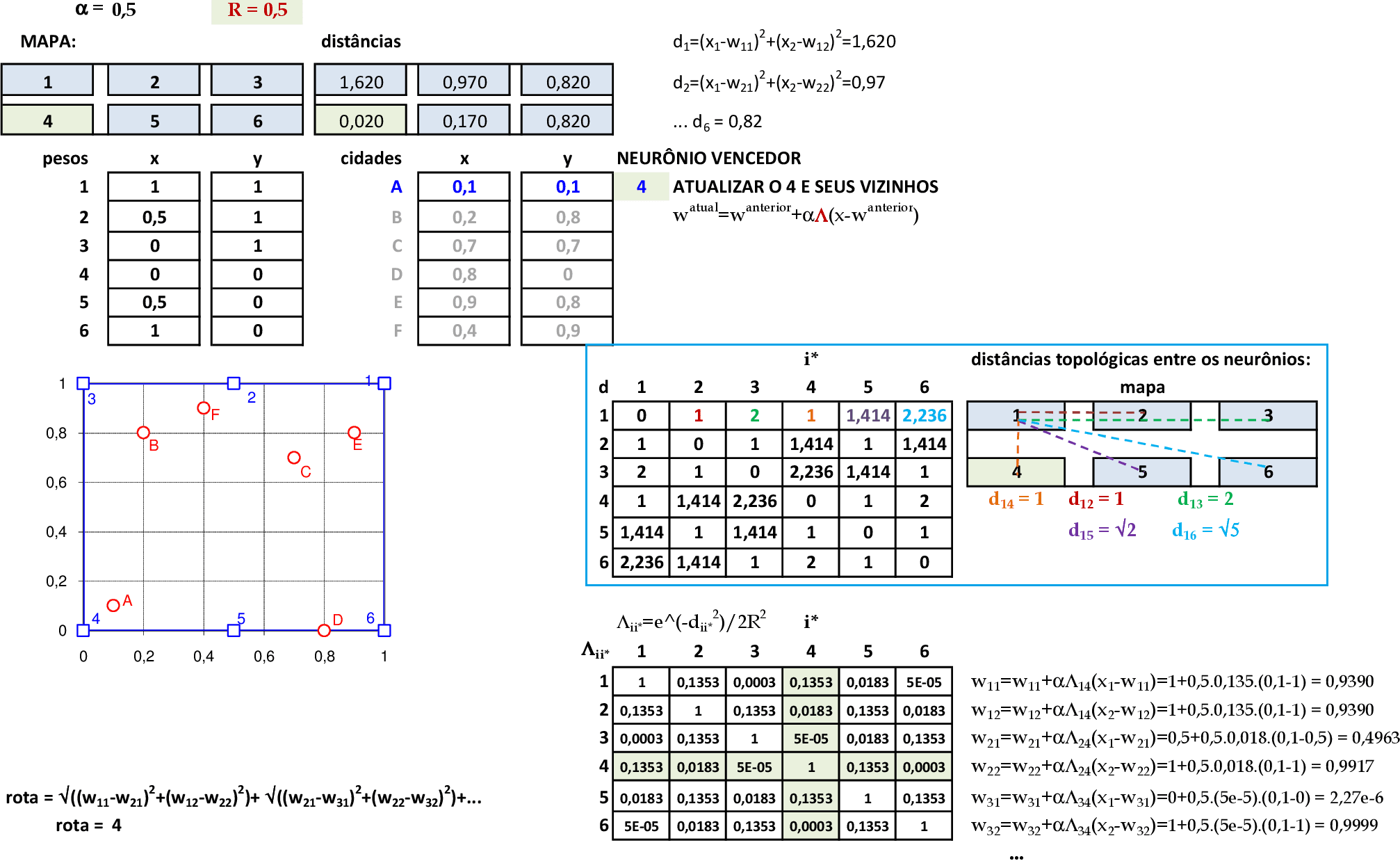
Neste caso, vamos usar a vizinhança Gaussiana com a função Λii* com as distâncias topológicas dii* entre os neurônios: por exemplo, o neurônio 1 tem distância topológica d12 = 1 ao neurônio 2; já a distância até o neurônio 3 será d13 = 2. -
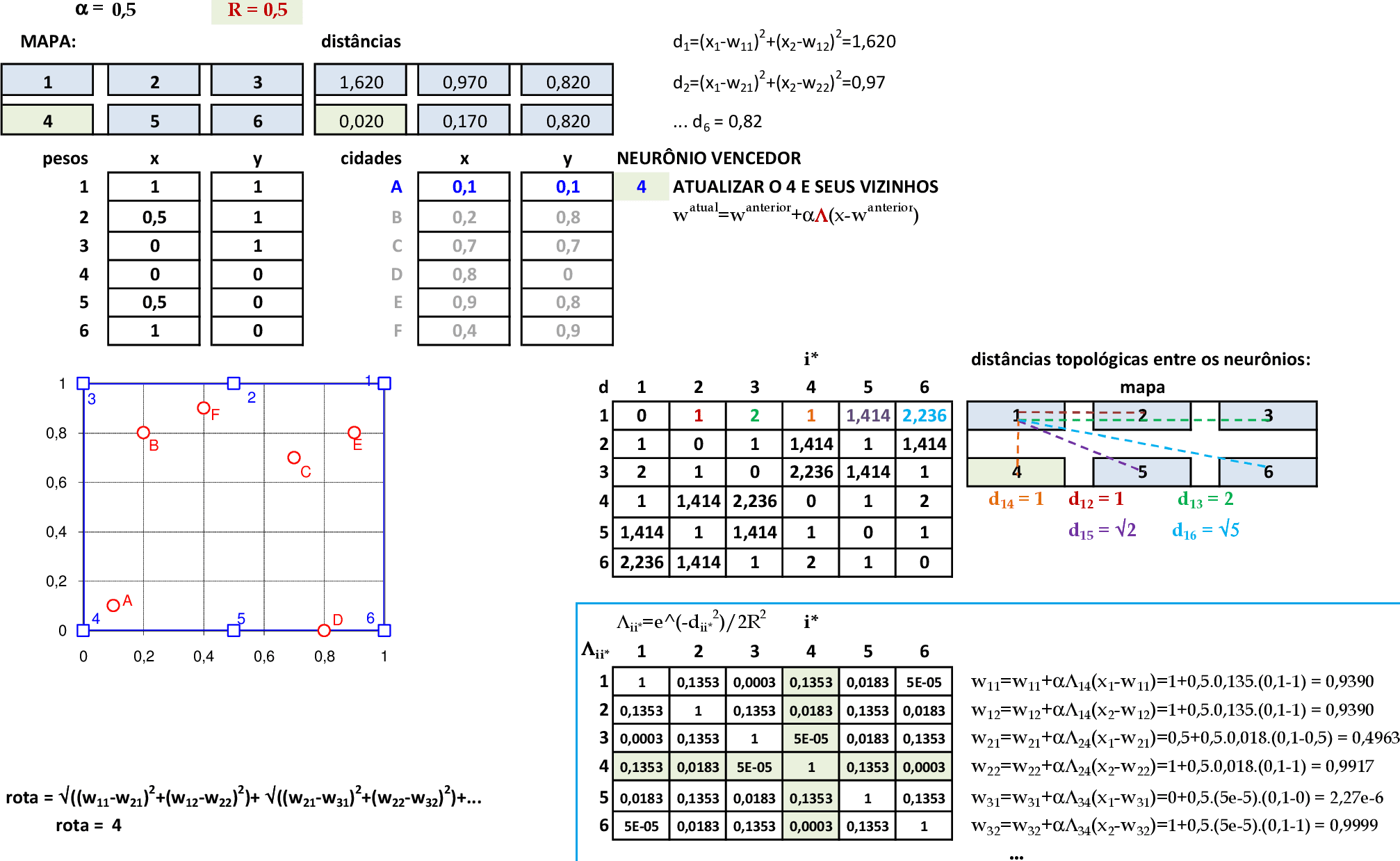
Apresentamos a cidade A(0,1; 0,1) para a rede, e o neurônio vencedor é o 4. Com a vizinhança Gaussiana, usamos a quarta linha e a quarta coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -

O valor da rota com a atualização é de 3,7867. Apresentamos a cidade D(0,8; 0) para a rede, e o neurônio vencedor é o 6. Usamos a sexta linha e a sexta coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -
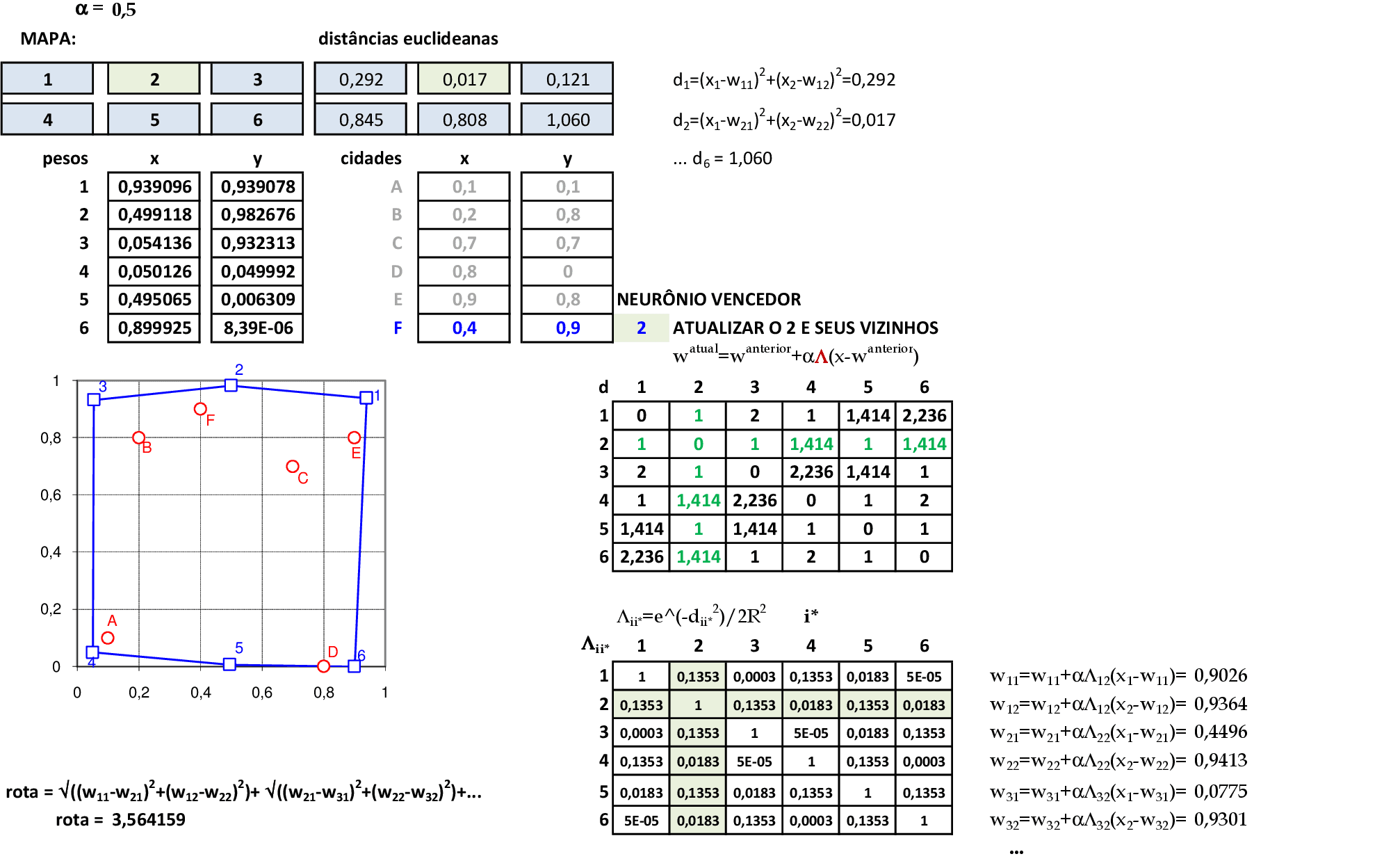
O valor da rota com a atualização é de 3,5641. Apresentamos a cidade F(0,4; 0,9) para a rede, e o neurônio vencedor é o 2. Usamos a segunda linha e a segunda coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -

O valor da rota com a atualização é de 3,4724. Apresentamos a cidade B(0,2; 0,8) para a rede, e o neurônio vencedor é o 3. Usamos a terceira linha e a terceira coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -
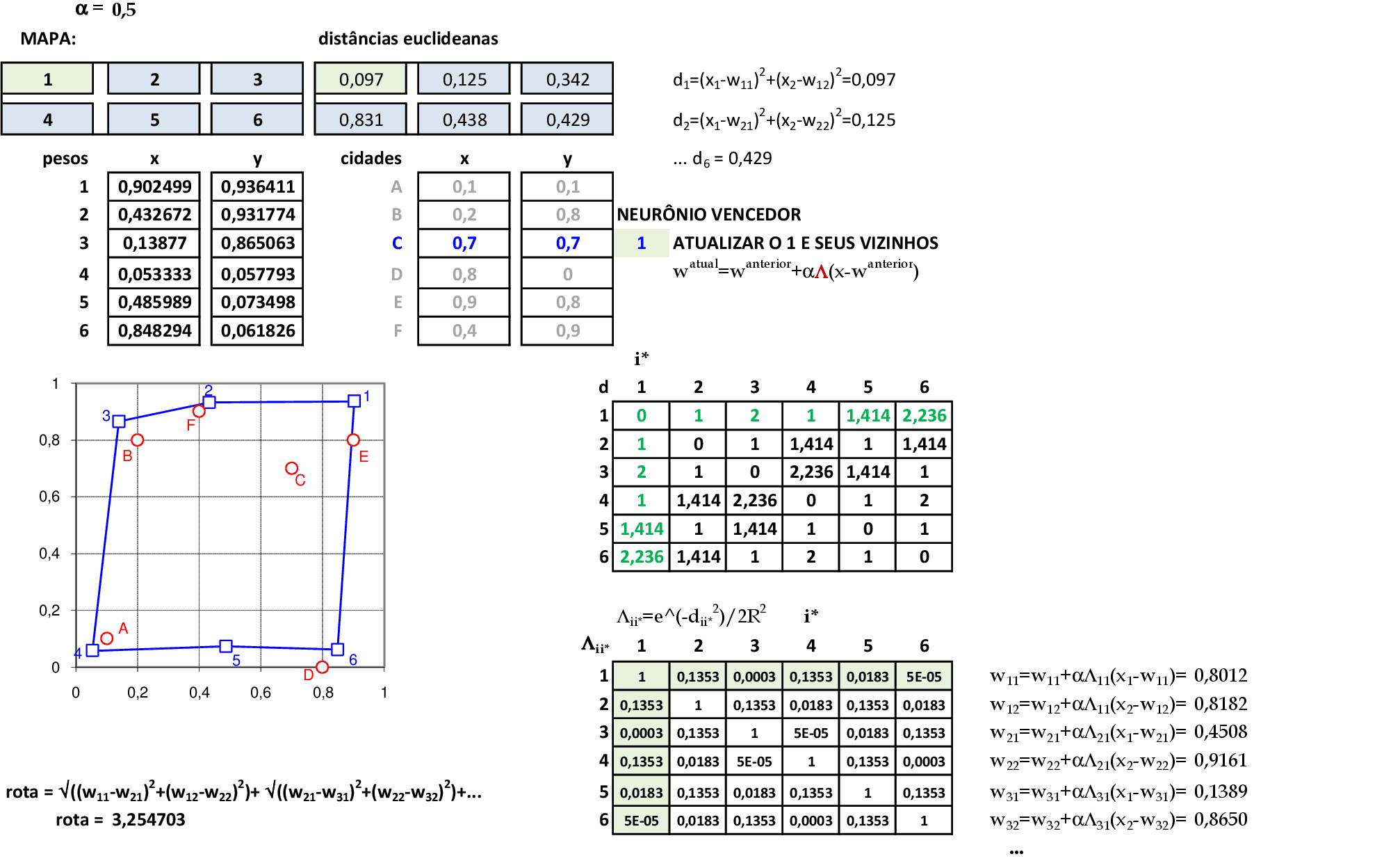
O valor da rota com a atualização é de 3,2547. Apresentamos a cidade C(0,7; 0,7) para a rede, e o neurônio vencedor é o 1. Usamos a primeira linha e a primeira coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -
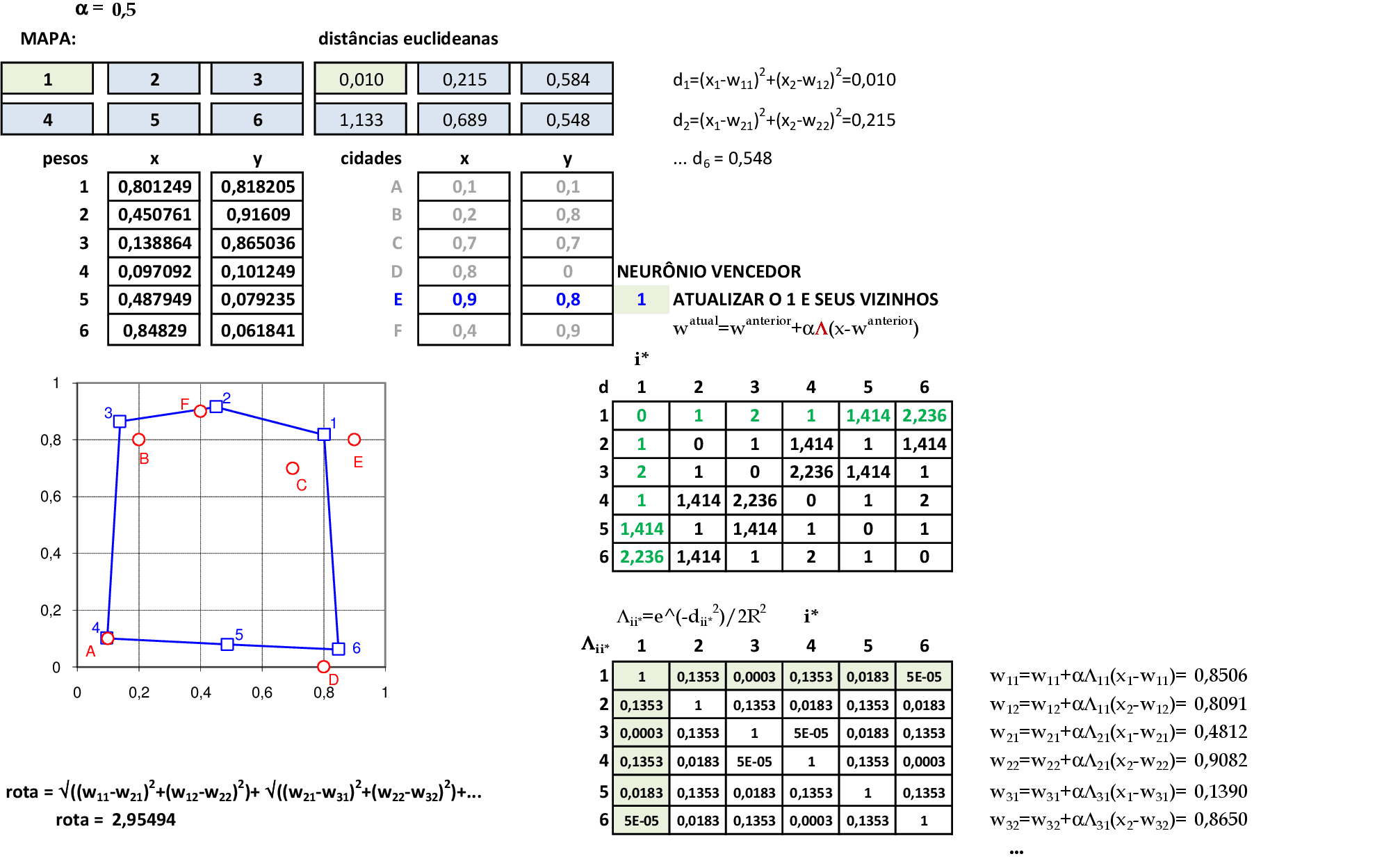
O valor da rota com a atualização é de 2,9549. Apresentamos a cidade E(0,9; 0,8) para a rede, e o neurônio vencedor é o 1. Usamos a primeira linha e a primeira coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -
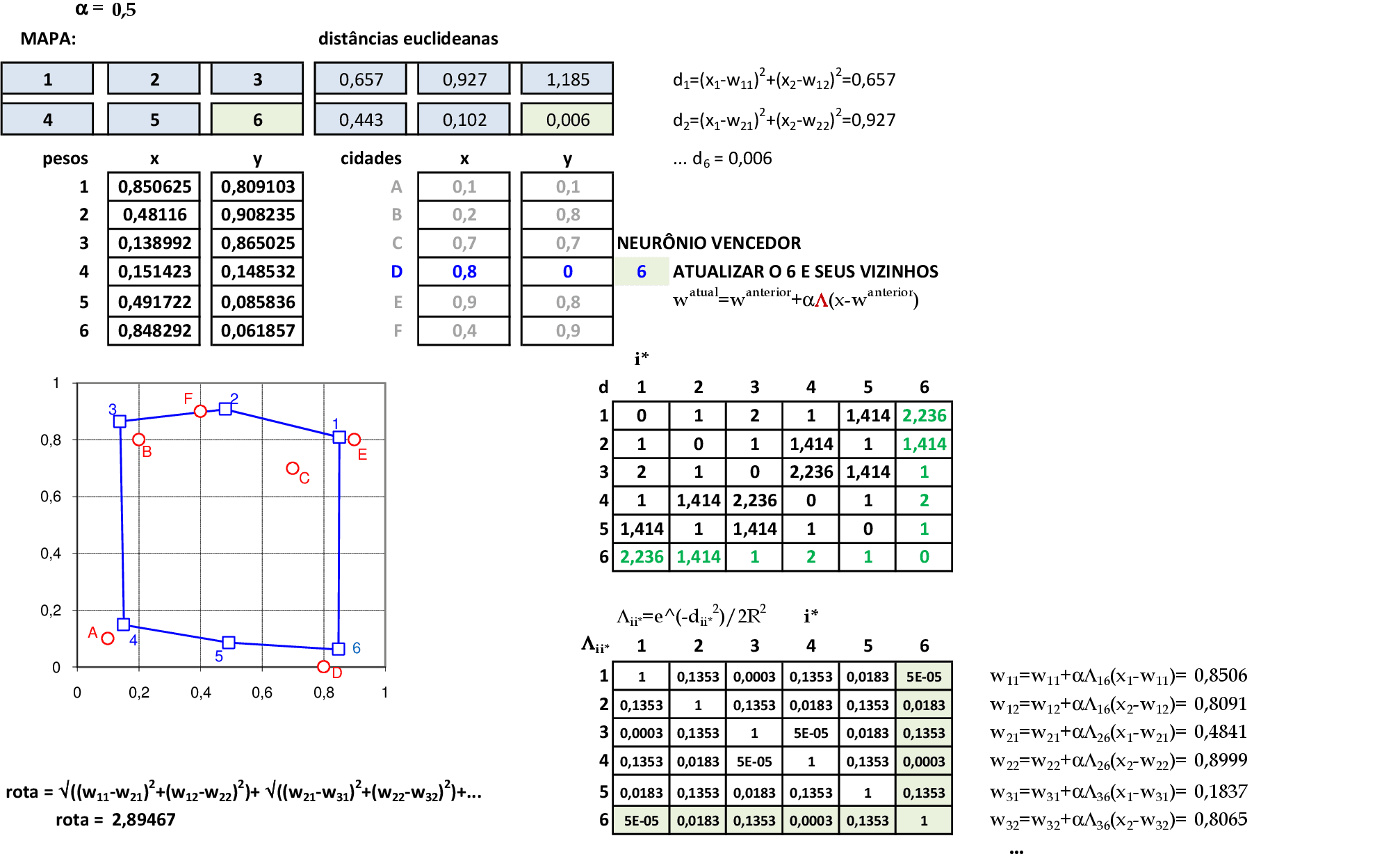
O valor da rota com a atualização é de 2,8946. Apresentamos a cidade D(0,8; 0) para a rede, e o neurônio vencedor é o 6. Usamos a sexta linha e a sexta coluna da matriz de distâncias Λii* para atualizar todos os pesos da rede. -
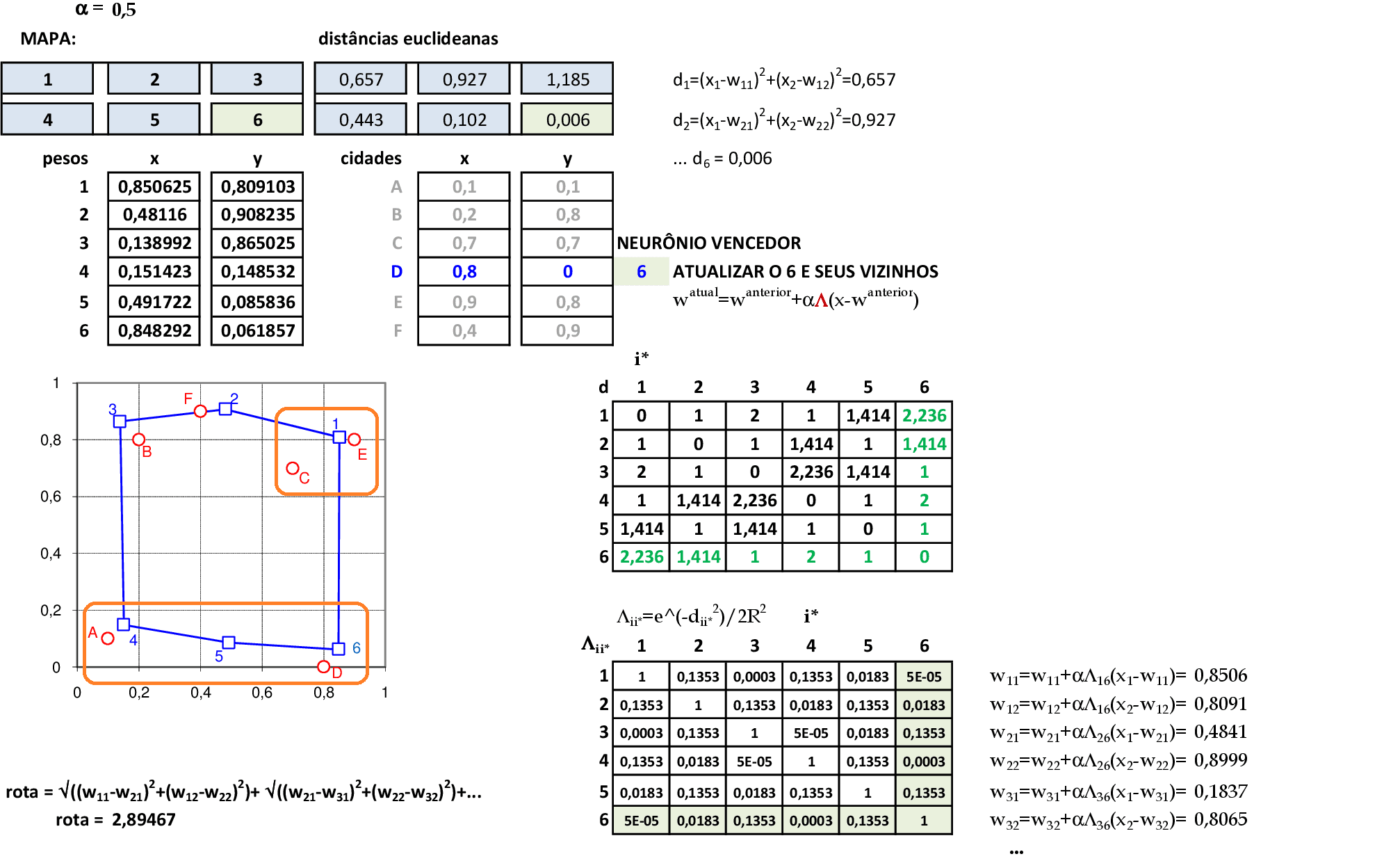
O valor da rota com a atualização é de 2,8585. O processo continua até que os pesos sofram poucas alterações. Note que o neurônio 5 não está sendo utilizado adequadamente, e as cidade C e E estão competindo pelo neurônio 1. Sugestão: colocar mais neurônios do que o número de cidades.

Usando o mesmo raciocínio do Exercício 1, resolva o problema burma14 do TSPLIB com o mapa auto-organizável SOM. Utilize mais do que 14 neurônios nesta rede neural. As coordenadas das cidades estão na tabela a seguir:
| cidade | x | y |
|---|---|---|
| 1 | 16.47 | 96.1 |
| 2 | 16.47 | 94.44 |
| 3 | 20.09 | 92.54 |
| 4 | 22.39 | 93.37 |
| 5 | 25.23 | 97.24 |
| 6 | 22 | 96.05 |
| 7 | 20.47 | 97.02 |
| 8 | 17.2 | 96.29 |
| 9 | 16.3 | 97.38 |
| 10 | 14.05 | 98.12 |
| 11 | 16.53 | 97.38 |
| 12 | 21.52 | 95.59 |
| 13 | 19.41 | 97.13 |
| 14 | 20.09 | 94.55 |

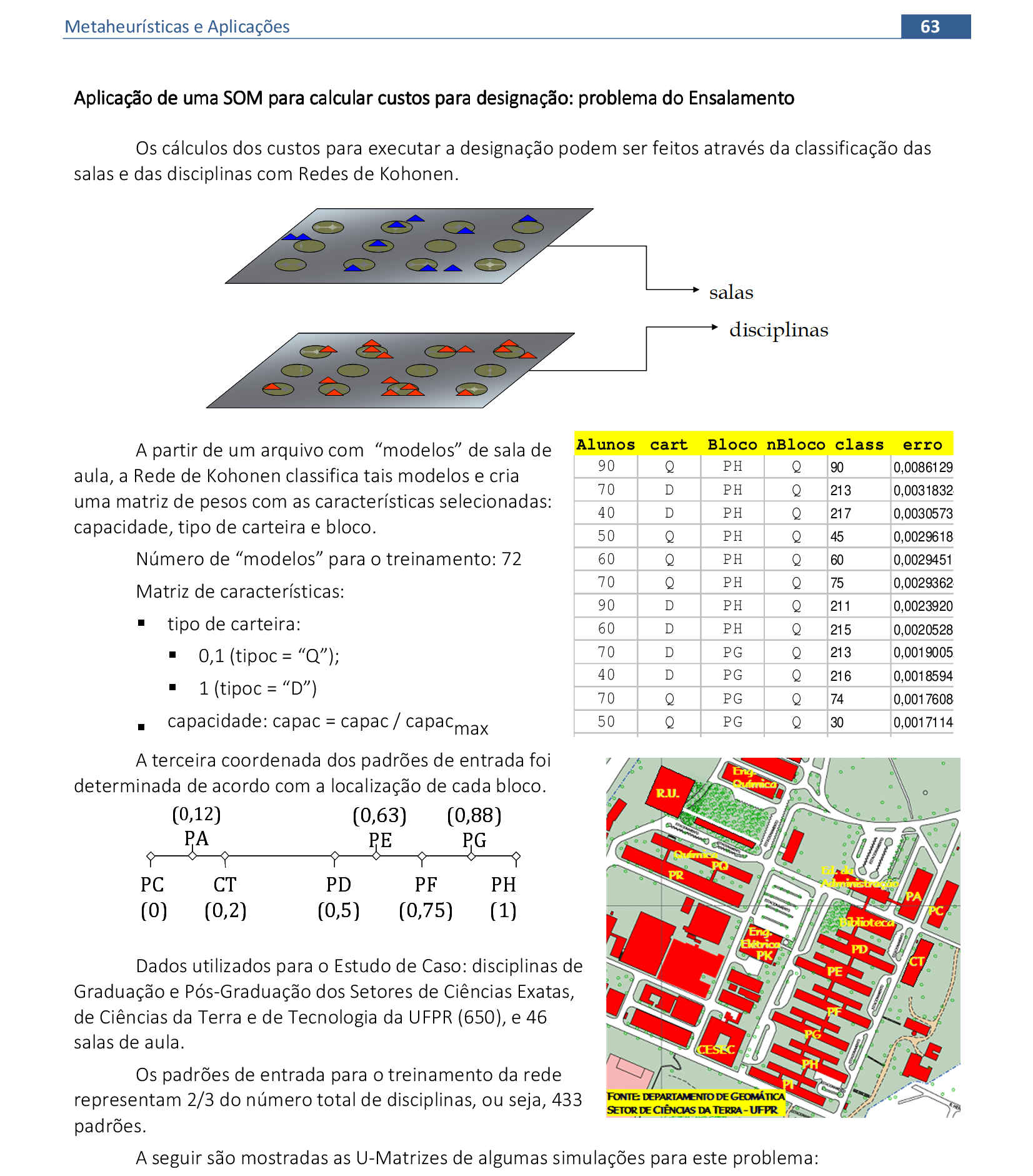

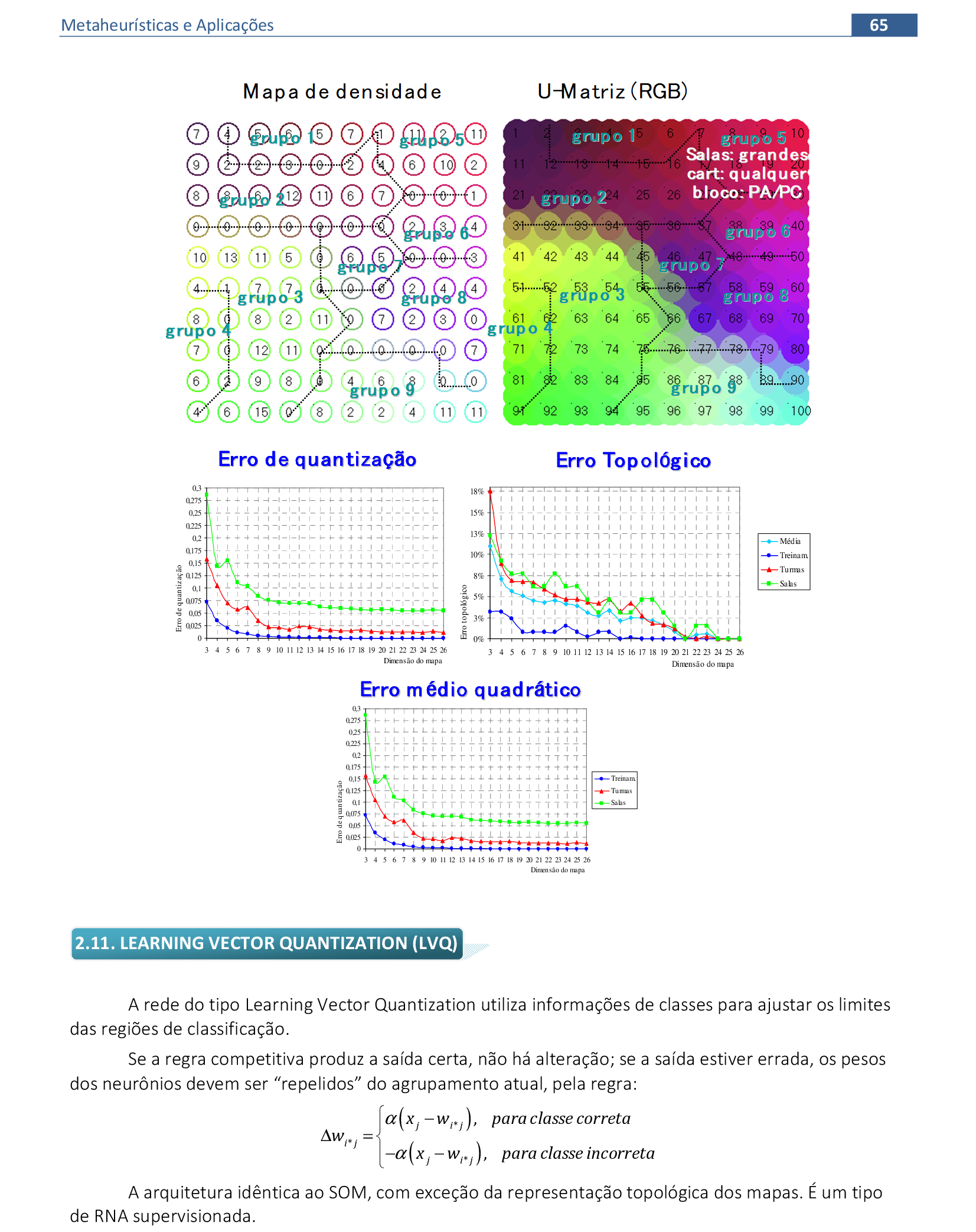

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de classificação de padrões usando uma Rede LVQ, com α = 0,1. Temos 3 neurônios que representam 2 classes.
-

Apresentamos o padrão x1 = (0, 0, 1, 1) para a rede, e o neurônio vencedor é o 2, que representa a classe 1. Como o padrão x1 pertence à classe 2, a atualização é feita como Δw2j = − α(xj − w2j). -
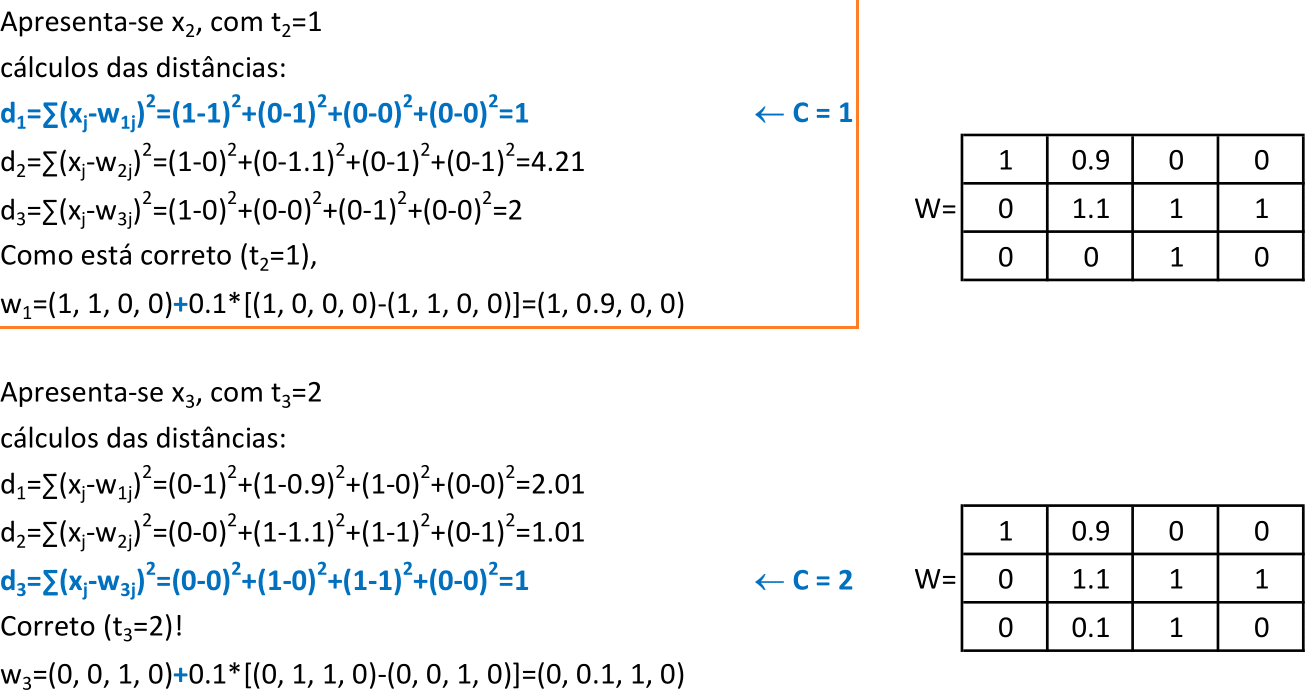
Apresentamos o padrão x2 = (1, 0, 0, 0) para a rede, e o neurônio vencedor é o 1, que representa a classe 1. Como o padrão x2 pertence à classe 1, a atualização é feita como Δw1j = + α(xj − w1j). -
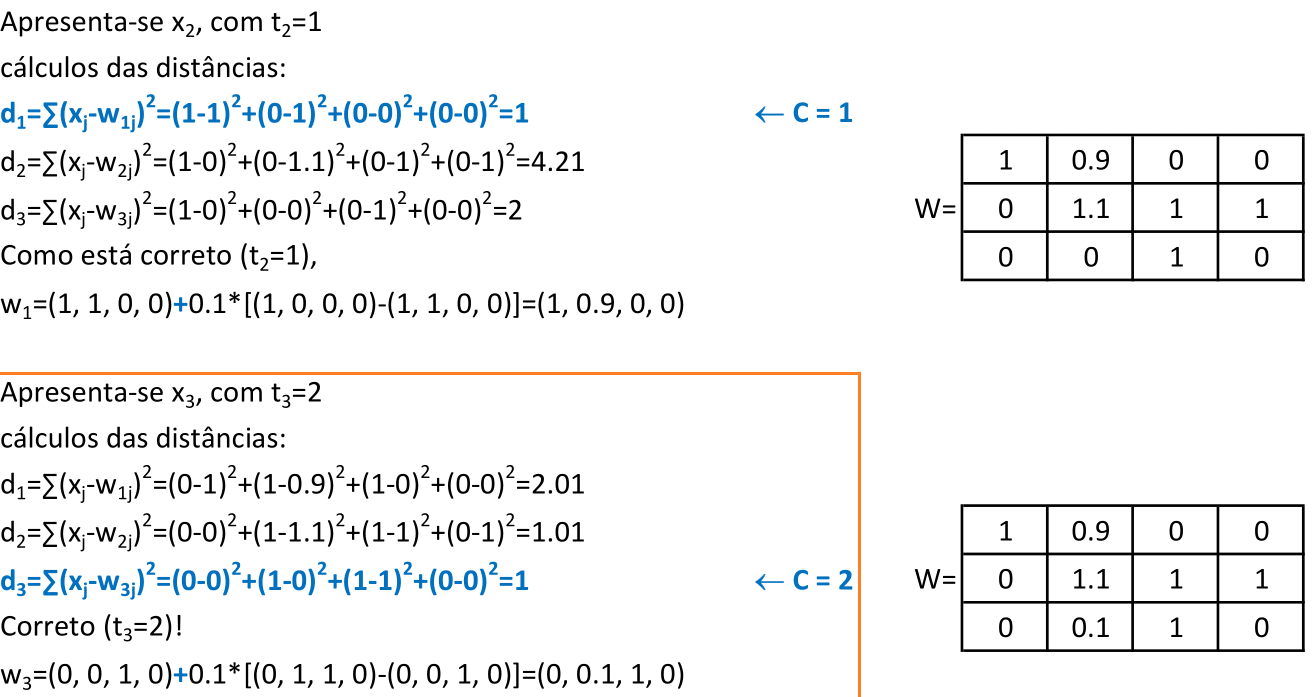
Apresentamos o padrão x3 = (0, 1, 1, 0) para a rede, e o neurônio vencedor é o 3, que representa a classe 2. Como o padrão x3 pertence à classe 2, a atualização é feita como Δw3j = + α(xj − w3j). -

Apresentamos o padrão x4 = (1, 1, 1, 0) para a rede, e o neurônio vencedor é o 1, que representa a classe 1. Como o padrão x4 pertence à classe 1, a atualização é feita como Δw1j = + α(xj − w1j). -

No fim da 1ª iteração, temos a matriz de pesos apresentada. Reduzimos o valor de α e continuamos os cálculos até que a rede tenha uma convergência: poucas alterações de pesos de uma iteração para a outra. -

Apresentando os padrões para a rede, temos os pesos reforçados de cada neurônio. -

No fim da 2ª iteração, temos a matriz de pesos apresentada. Reduzimos o valor de α e continuamos os cálculos até que a rede tenha uma convergência: poucas alterações de pesos de uma iteração para a outra.

7. Redes Neurais Temporais
Material das páginas 66 até 75.

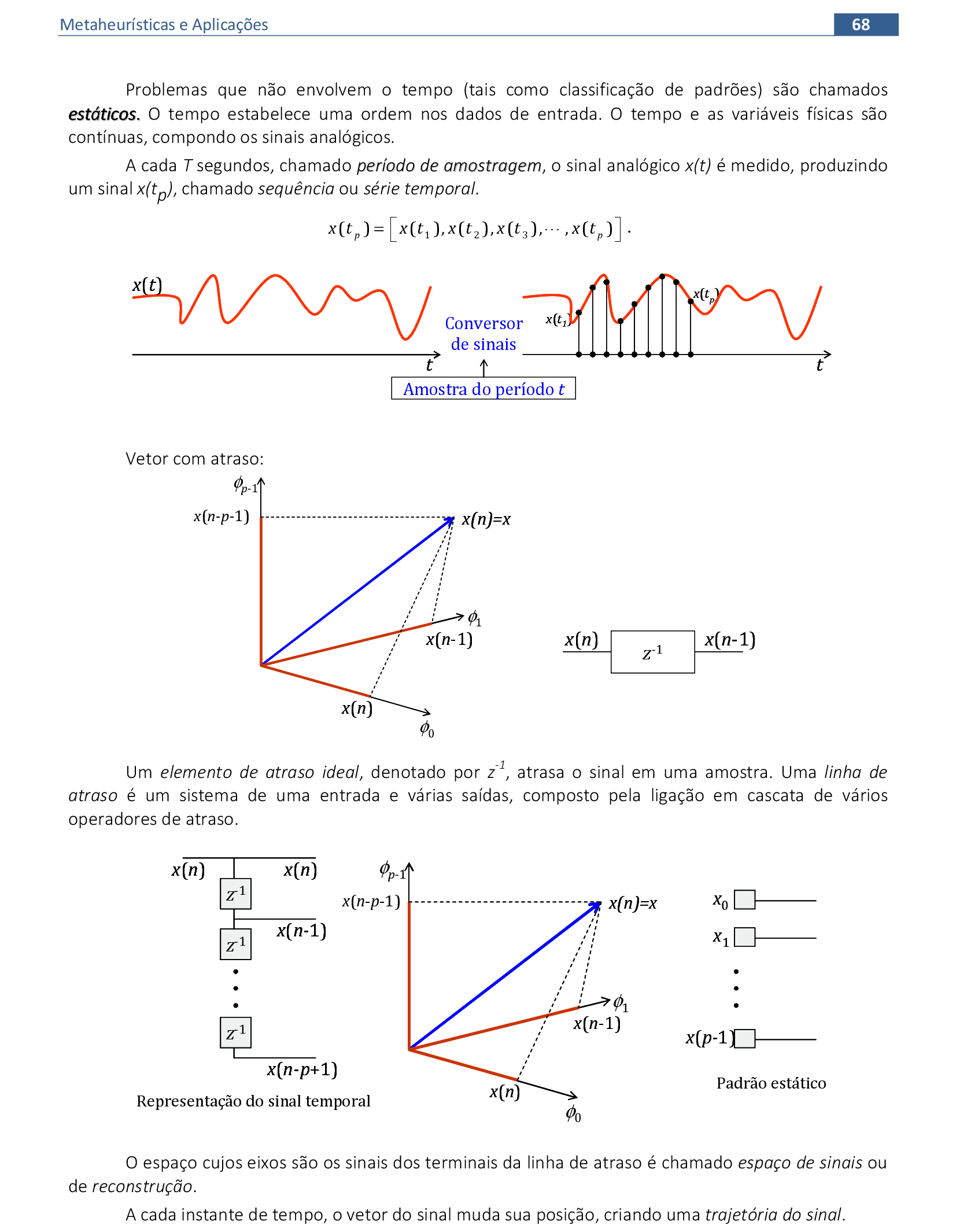


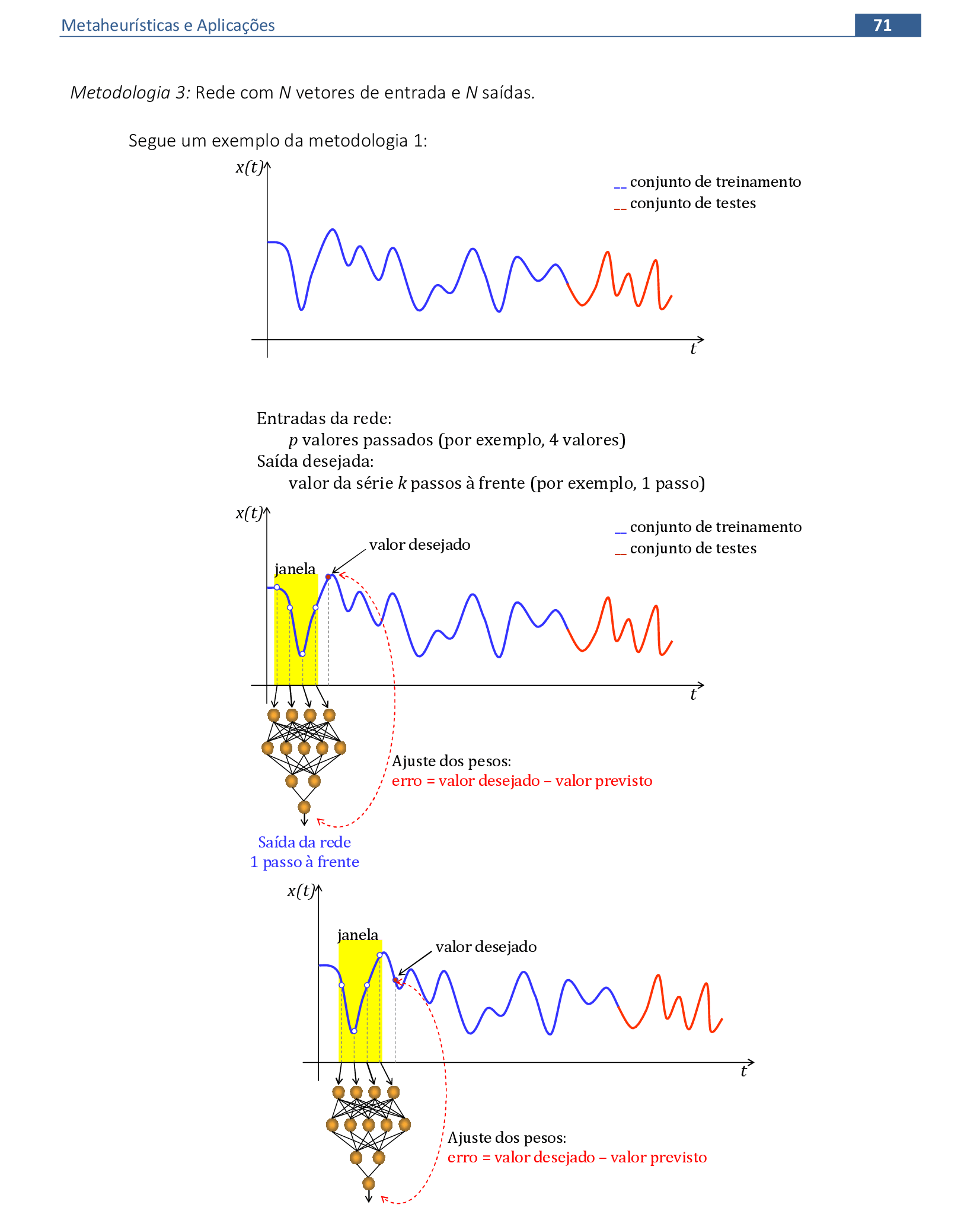
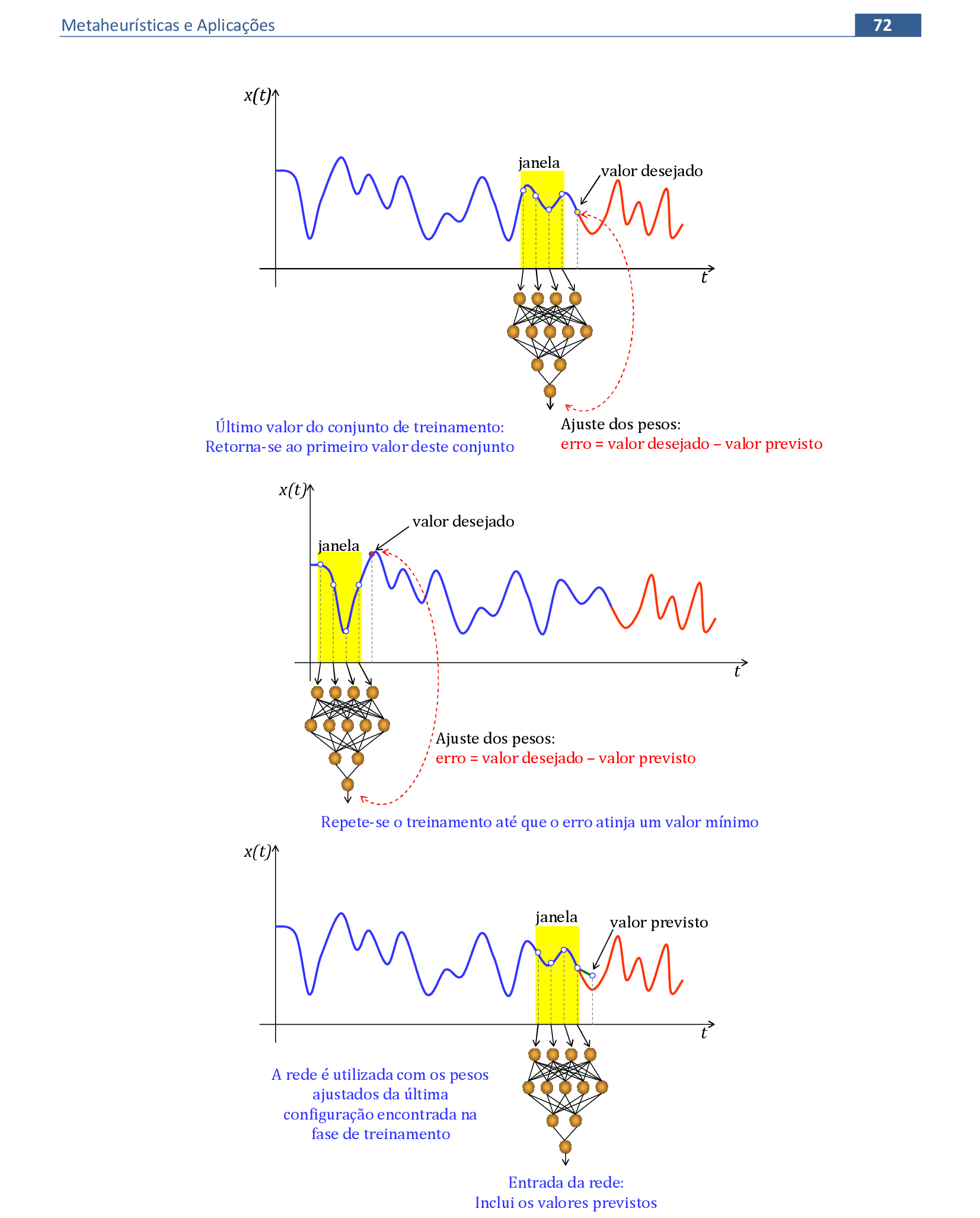
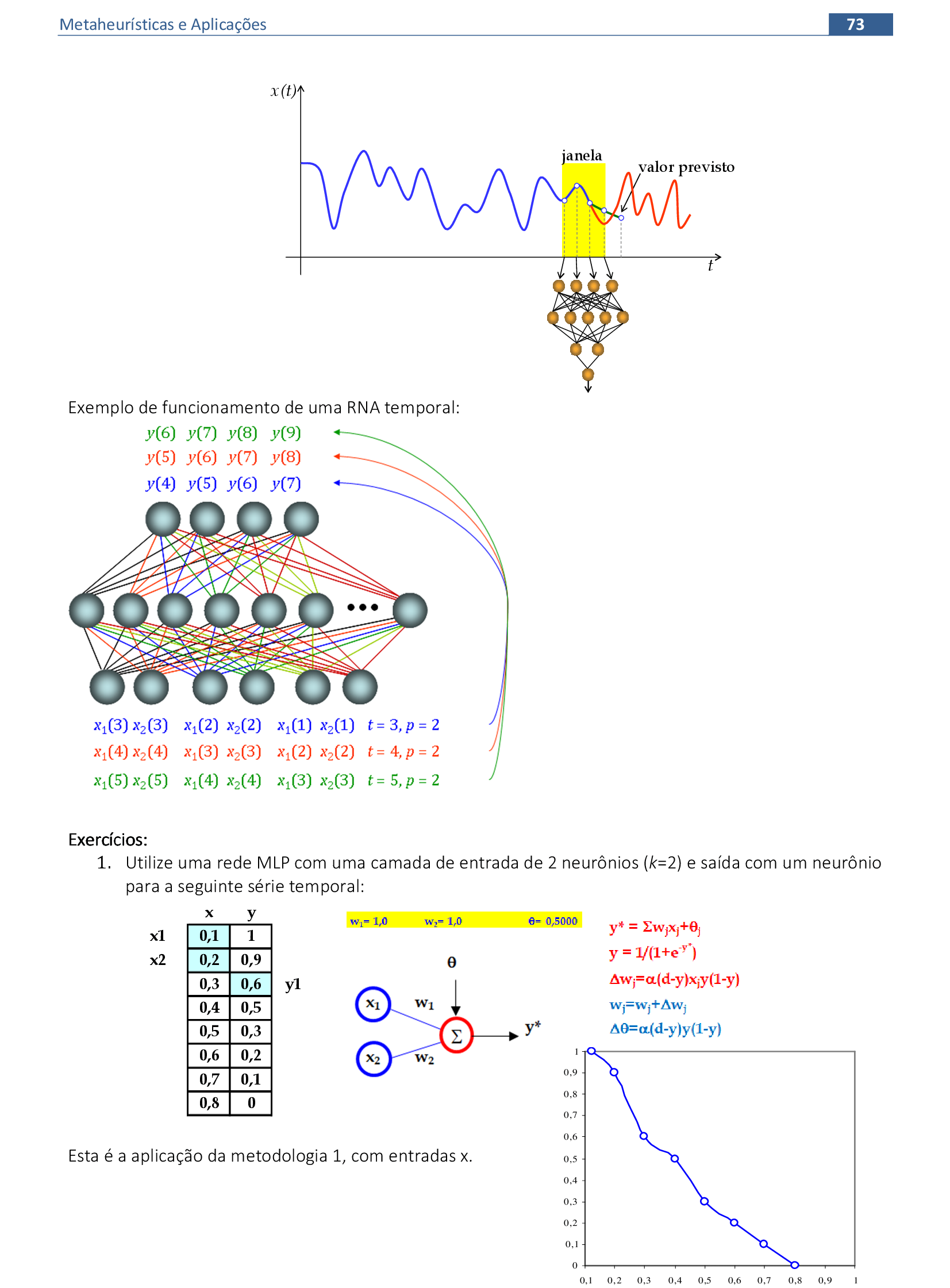
📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, sem camada escondida.
-
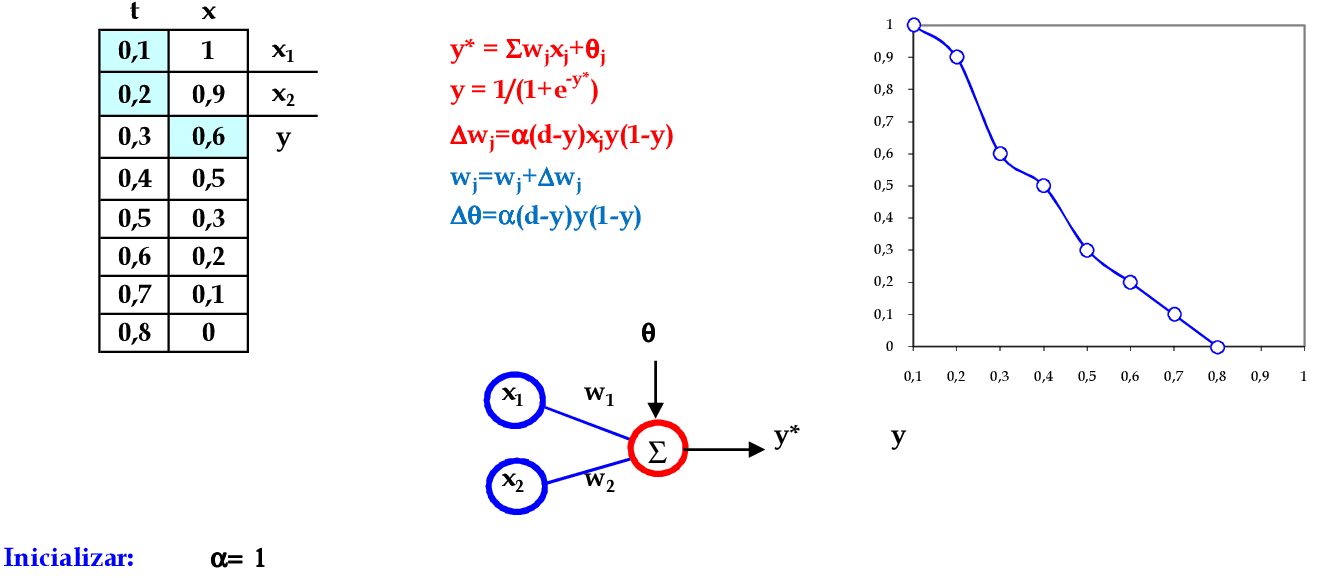
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.6; (0.9, 0.6) para prever 0.5; e assim sucessivamente. -

Apresentamos o primeiro padrão de entrada para a rede: (1, 0.9). -

Apresentamos o padrão de entrada (0.9, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.2) para a rede. -

Apresentamos o último padrão de entrada da rede: (0.2, 0.1). -

No final da 1ª iteração, temos o erro quadrático E = 0,521. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -
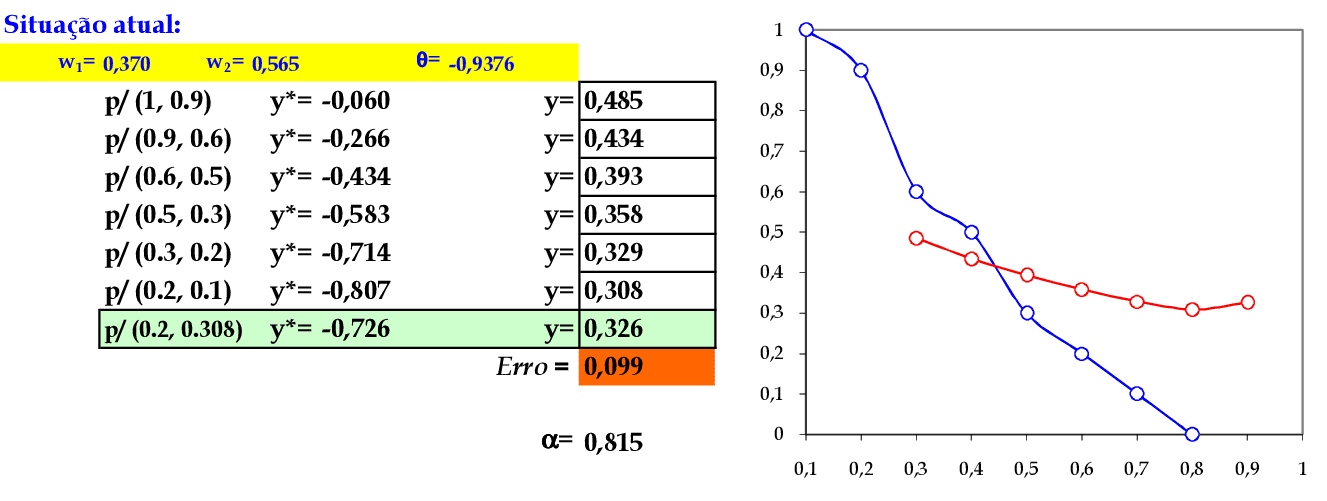
No final da 4ª iteração, temos o erro quadrático E = 0,099.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, sem camada escondida.
-
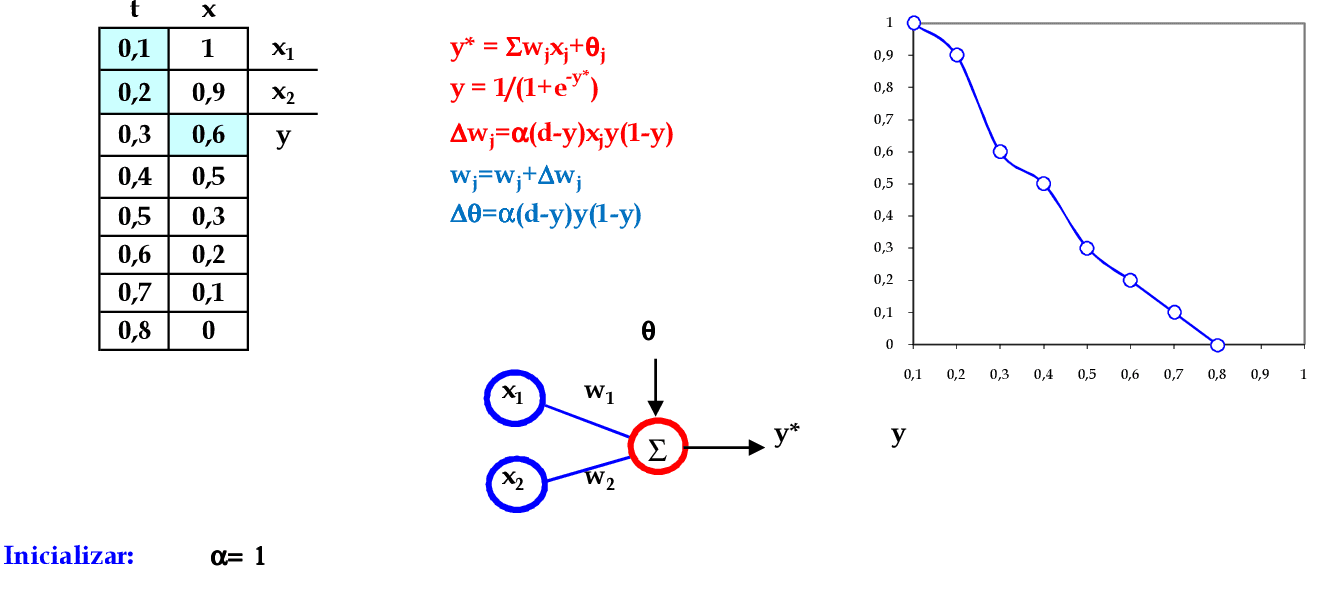
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (0.1, 0.2) para prever 0.6; (0.2, 0.3) para prever 0.5; e assim sucessivamente. -

Apresentamos o primeiro padrão de entrada para a rede: (0.1, 0.2). -

Apresentamos o padrão de entrada (0.2, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.4) para a rede. -

Apresentamos o padrão de entrada (0.4, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.6) para a rede. -

Apresentamos o último padrão de entrada da rede: (0.6, 0.7). -
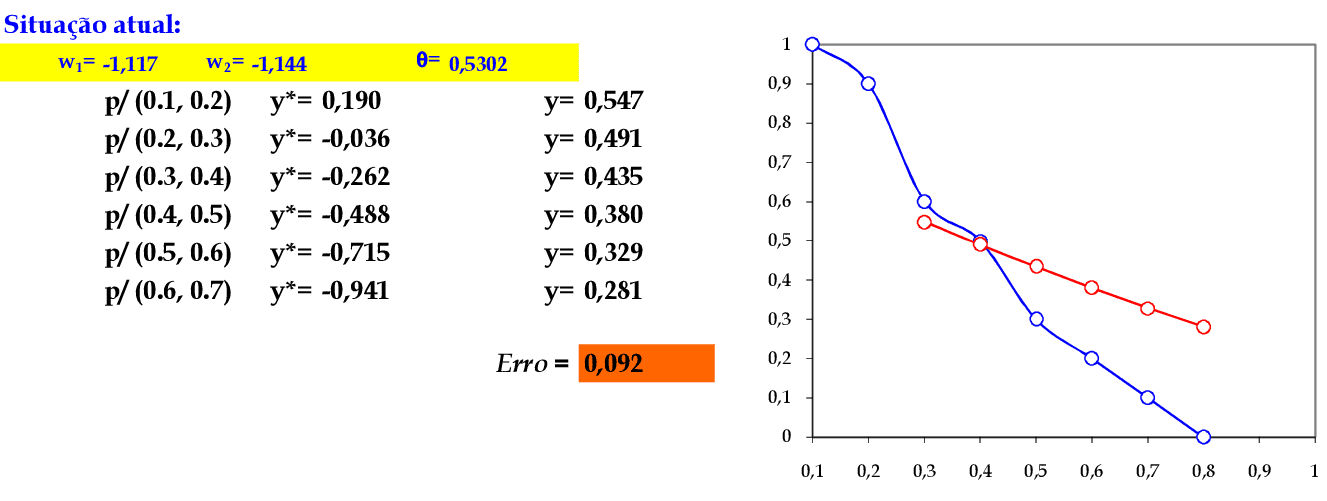
No final da 1ª iteração, temos o erro quadrático E = 0,092. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -

No final da 4ª iteração, temos o erro quadrático E = 0,046.

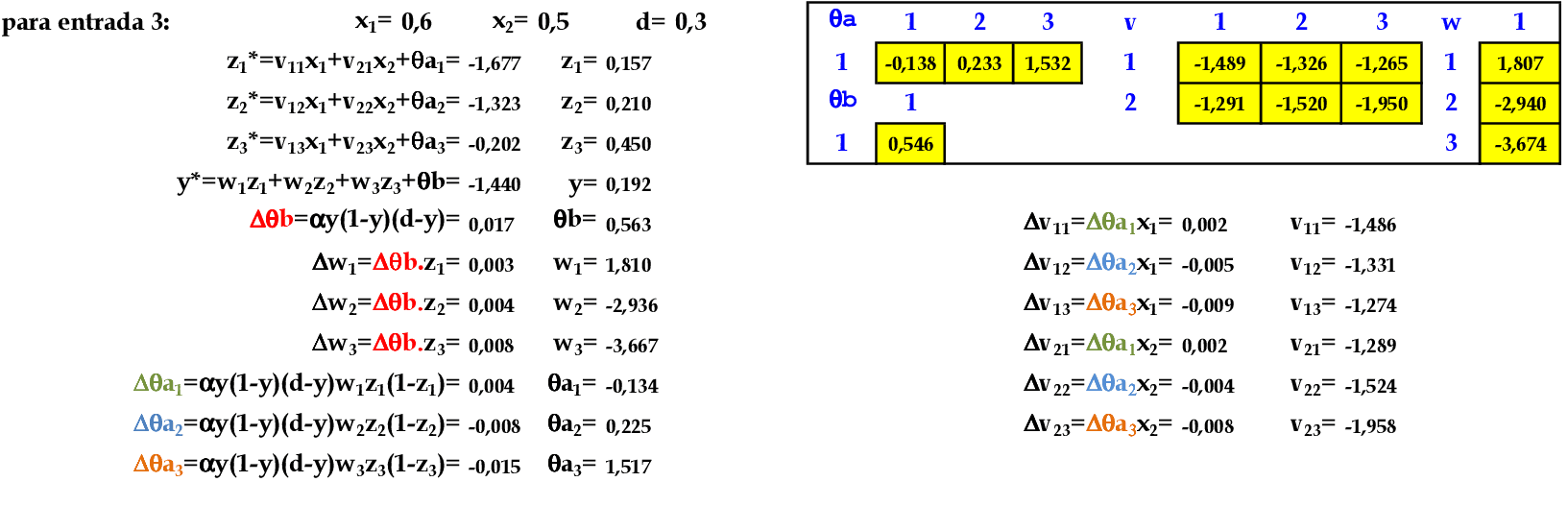
📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, com uma camada escondida com função sigmoidal.
-
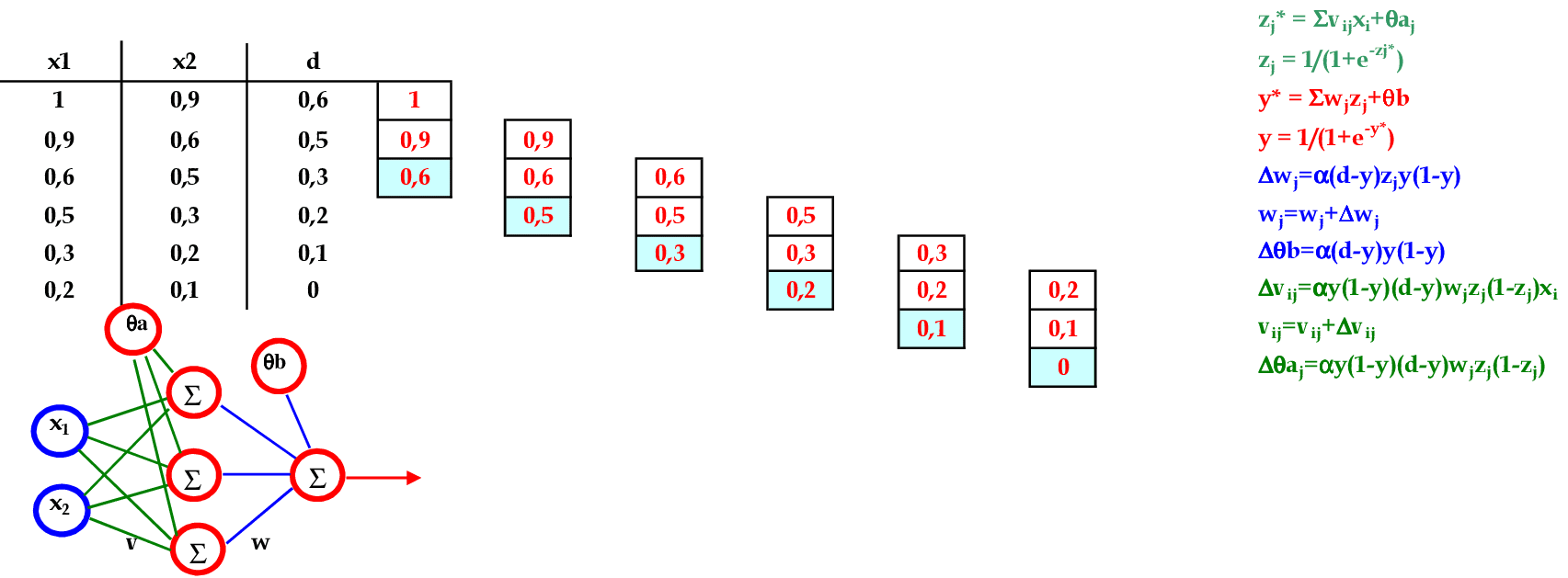
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.6; (0.9, 0.6) para prever 0.5; e assim sucessivamente. -

Apresentamos o primeiro padrão de entrada para a rede: (1, 0.9). -

Apresentamos o padrão de entrada (0.9, 0.6) para a rede. -
Apresentamos o padrão de entrada (0.6, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.2) para a rede. -

Apresentamos o padrão de entrada (0.2, 0.1) para a rede. -
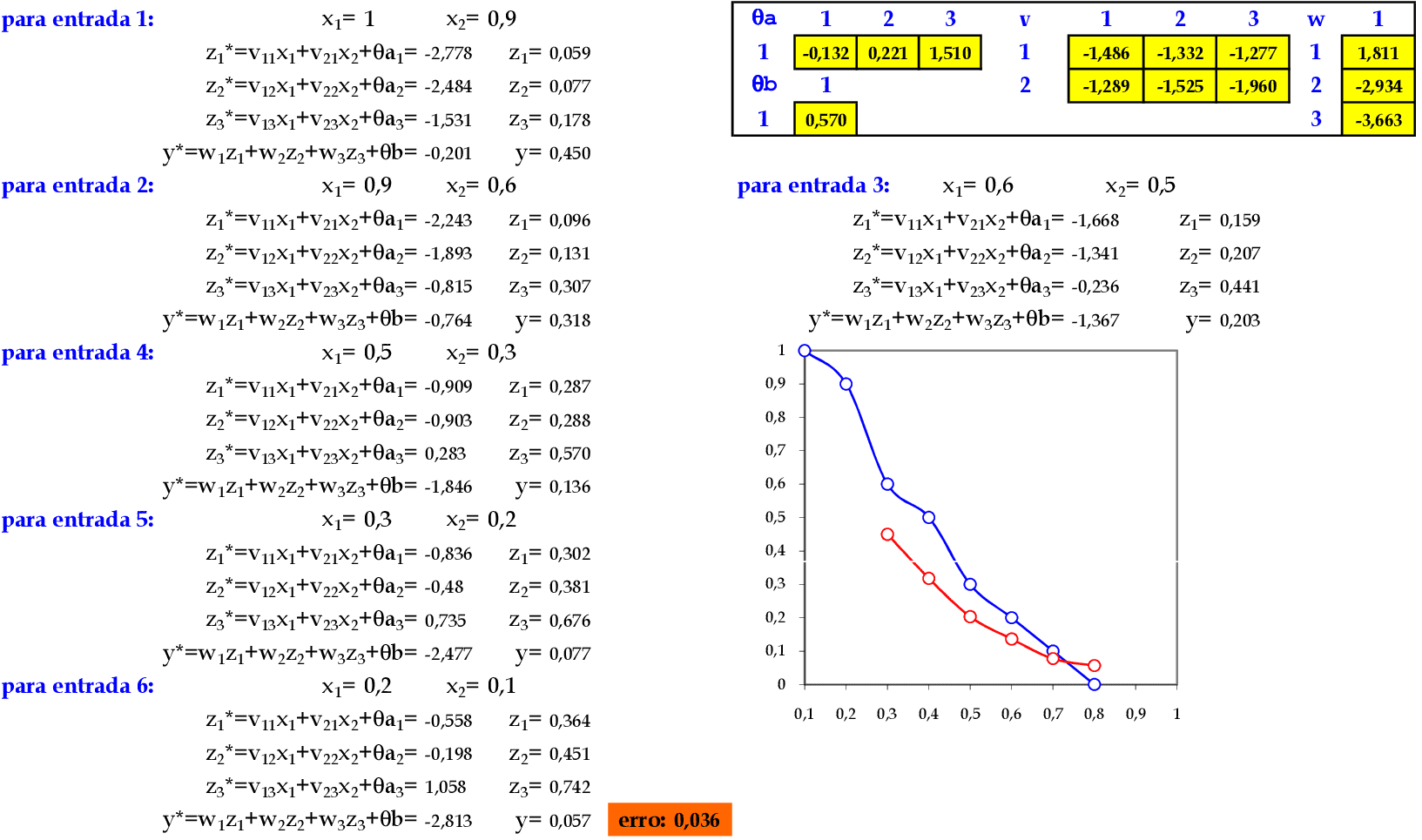
No final da 1ª iteração, temos o erro quadrático E = 0,036. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -

No final da 4ª iteração, temos o erro quadrático E = 0,008.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, com uma camada escondida com função sigmoidal.
-
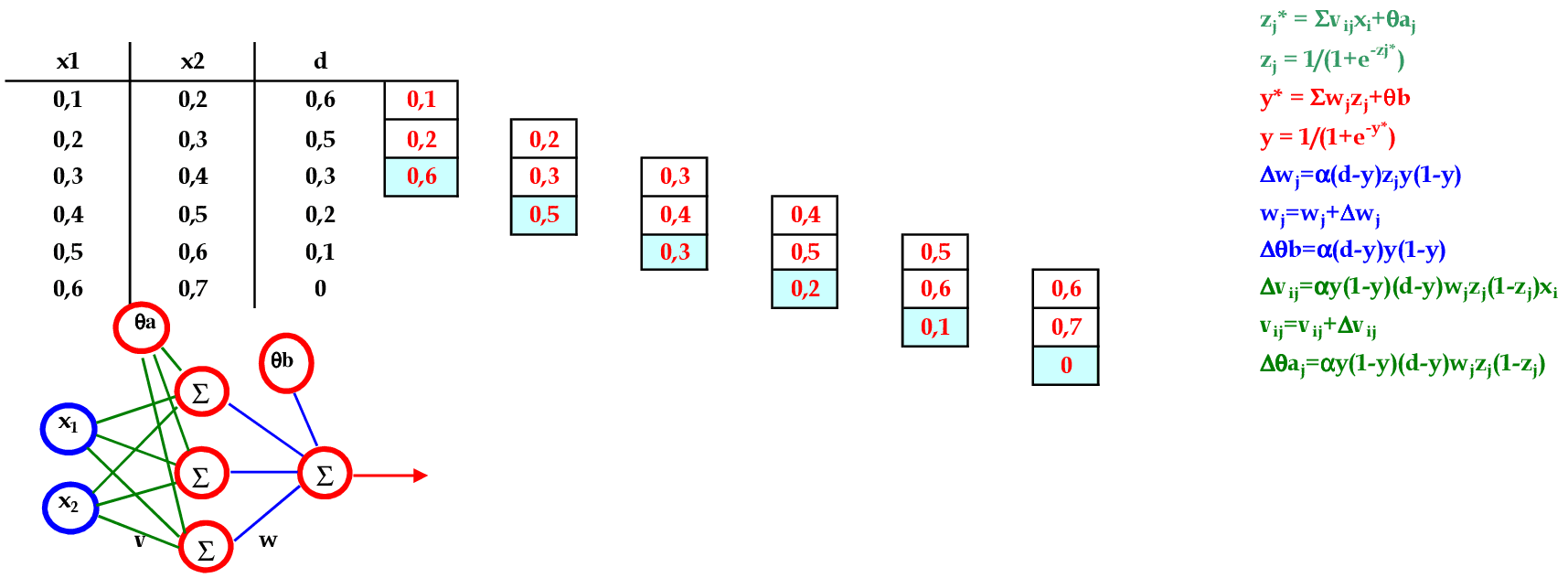
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (0.1, 0.2) para prever 0.6; (0.2, 0.3) para prever 0.5; e assim sucessivamente. -

Apresentamos o primeiro padrão de entrada para a rede: (0.1, 0.2). -

Apresentamos o padrão de entrada (0.2, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.4) para a rede. -

Apresentamos o padrão de entrada (0.4, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.7) para a rede. -

No final da 1ª iteração, temos o erro quadrático E = 0,050. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -
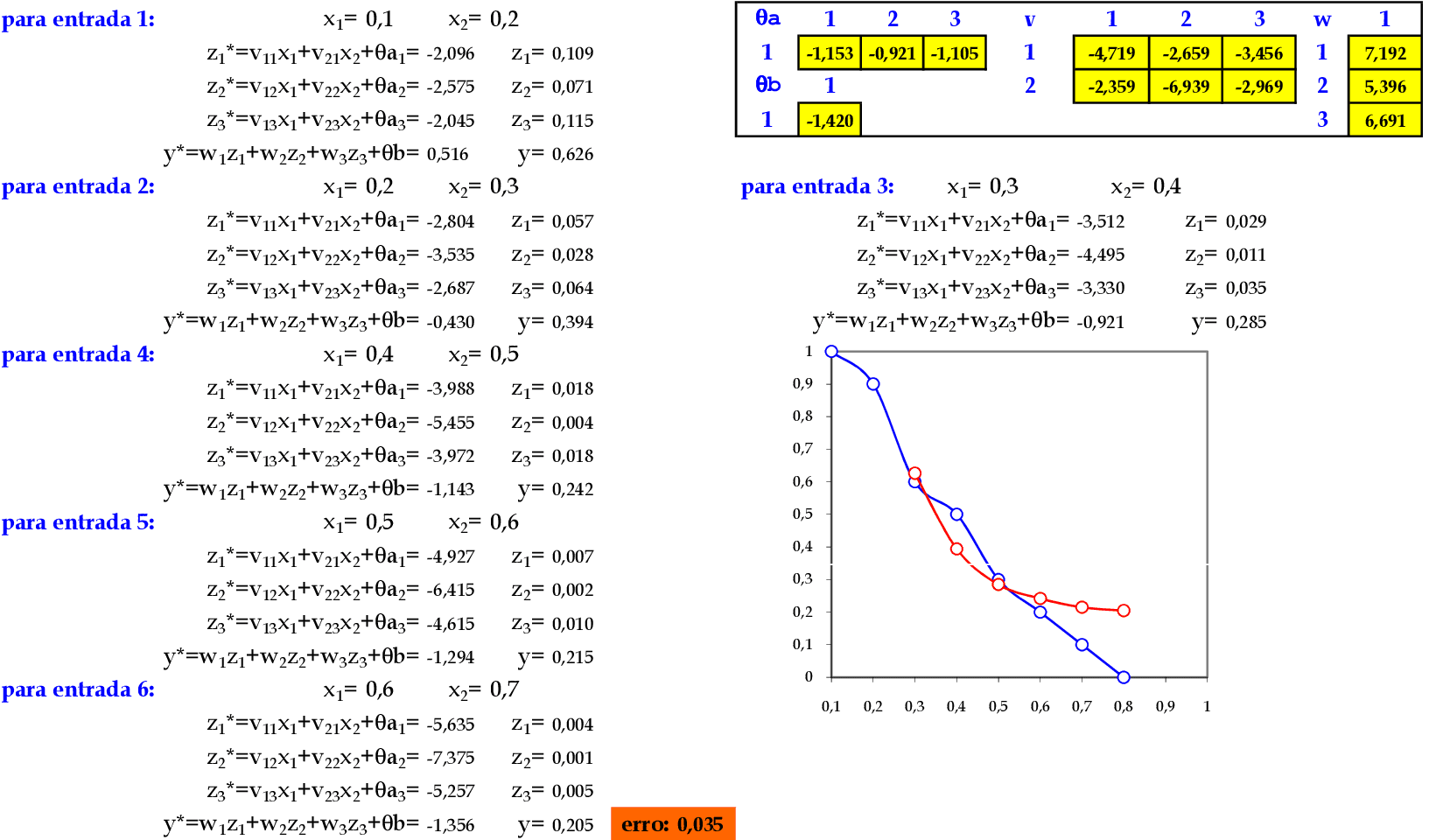
No final da 4ª iteração, temos o erro quadrático E = 0,035.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, com uma camada escondida com função tangente hiperbólica.
-
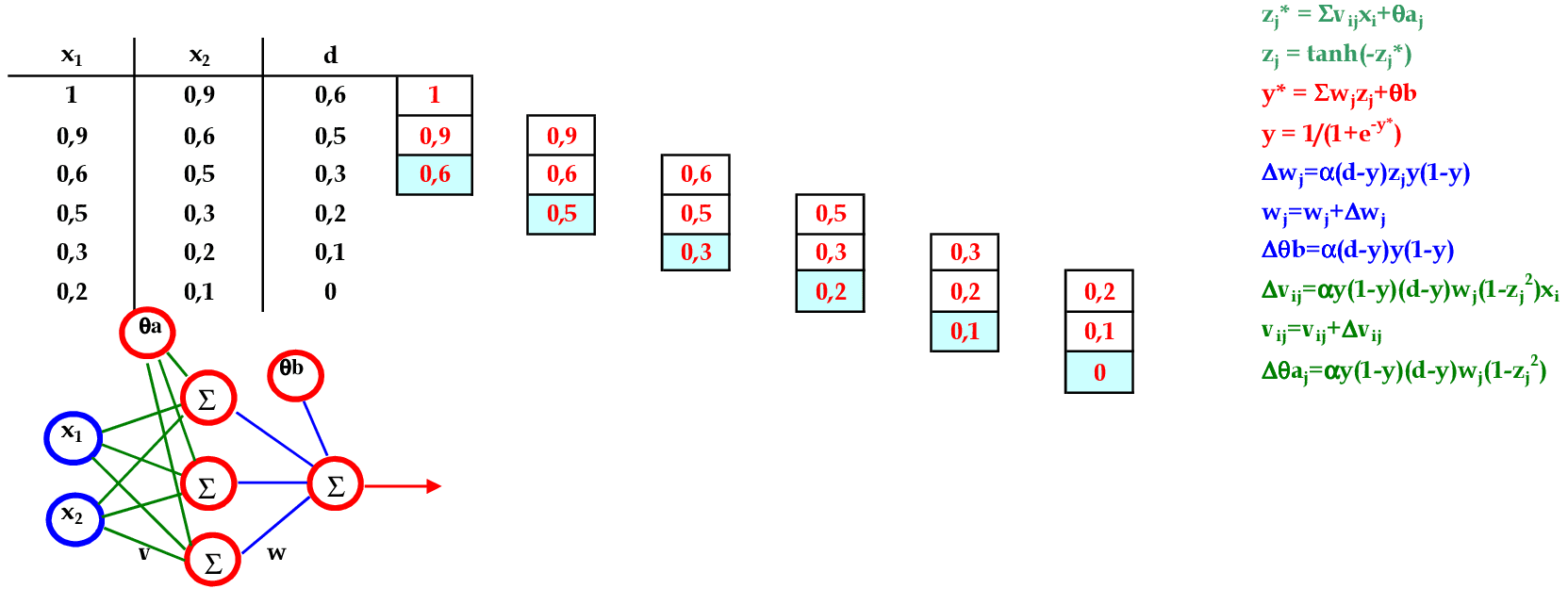
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.6; (0.9, 0.6) para prever 0.5; e assim sucessivamente. -

Apresentamos o primeiro padrão de entrada para a rede: (1, 0.9). -

Apresentamos o padrão de entrada (0.9, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.2) para a rede. -

Apresentamos o padrão de entrada (0.2, 0.1) para a rede. -
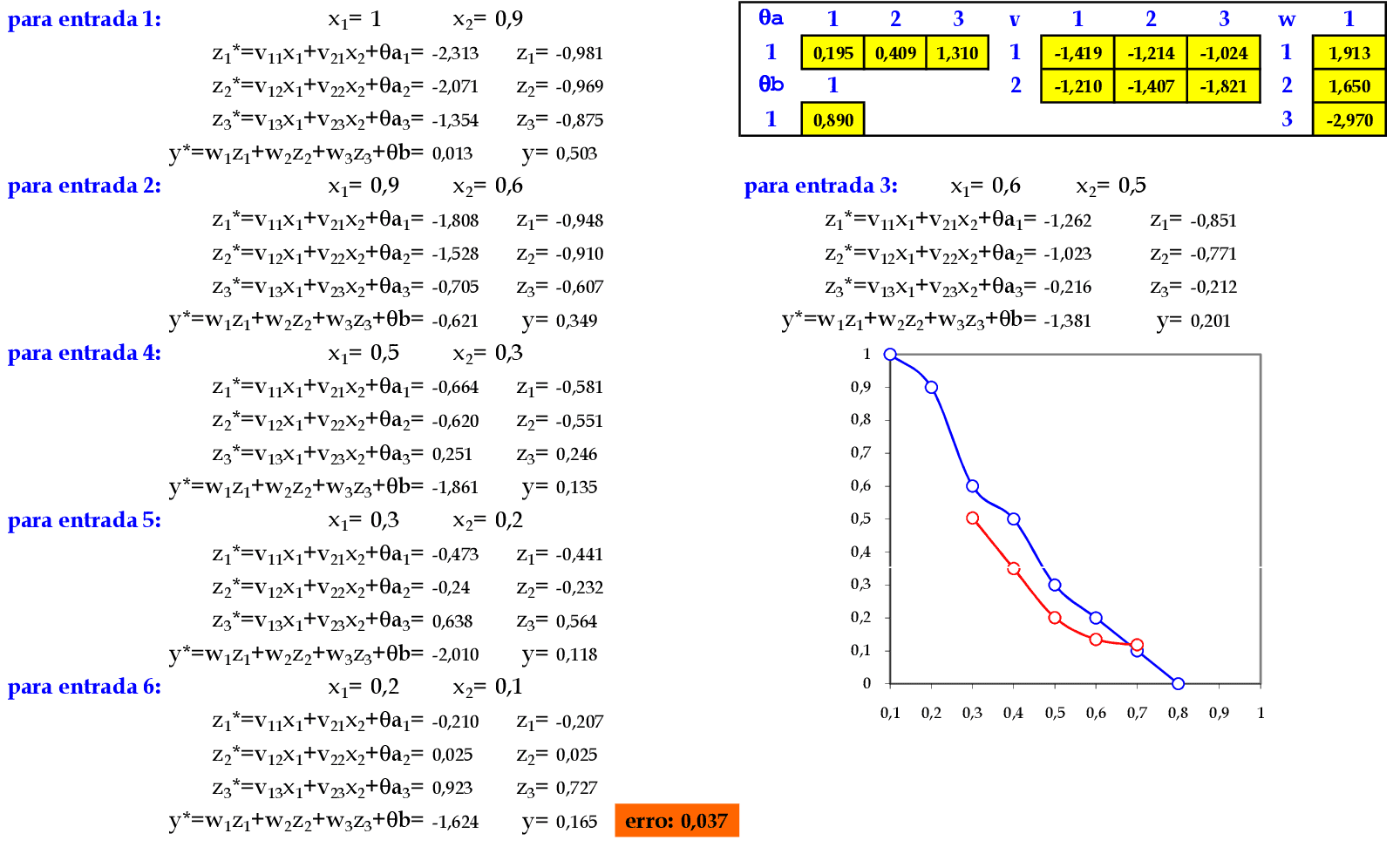
No final da 1ª iteração, temos o erro quadrático E = 0,037. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -
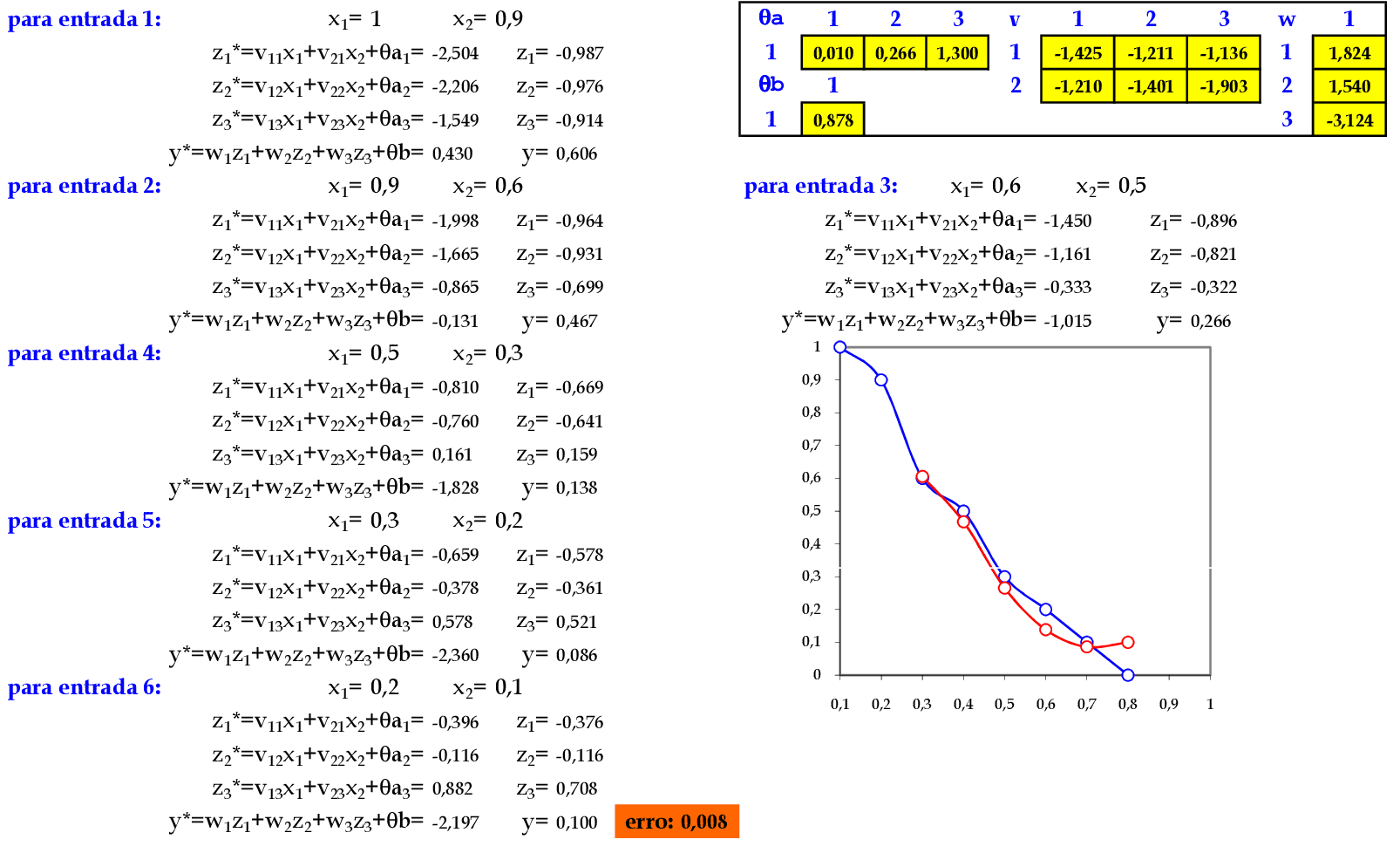
No final da 4ª iteração, temos o erro quadrático E = 0,008.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal MLP, com α = 1, com uma camada escondida com função tangente hiperbólica.
-
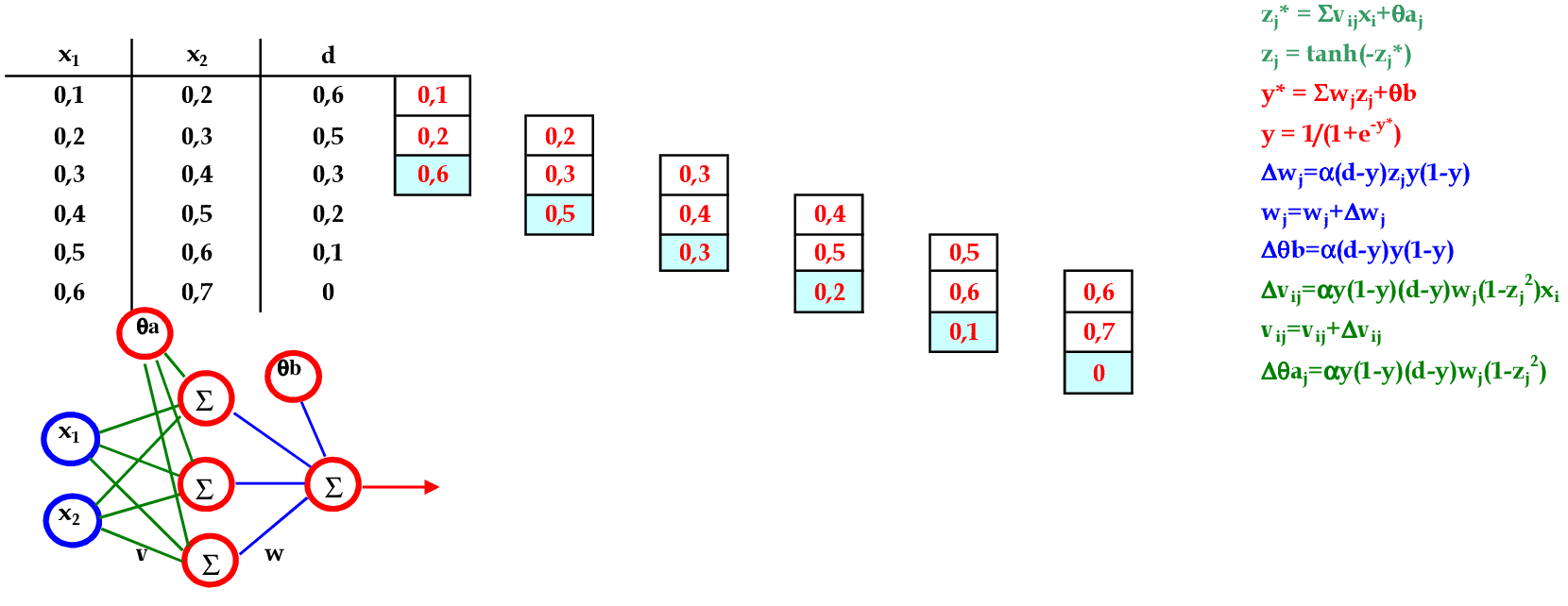
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (0.1, 0.2) para prever 0.6; (0.2, 0.3) para prever 0.5; e assim sucessivamente. -
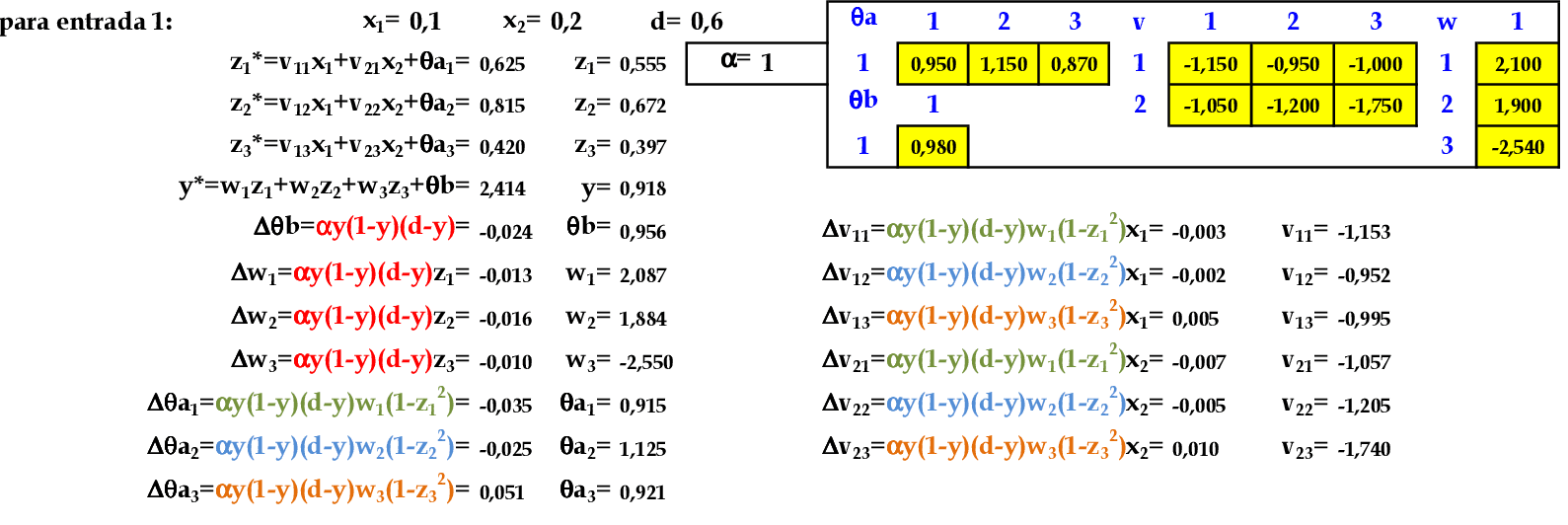
Apresentamos o primeiro padrão de entrada para a rede: (0.1, 0.2). -
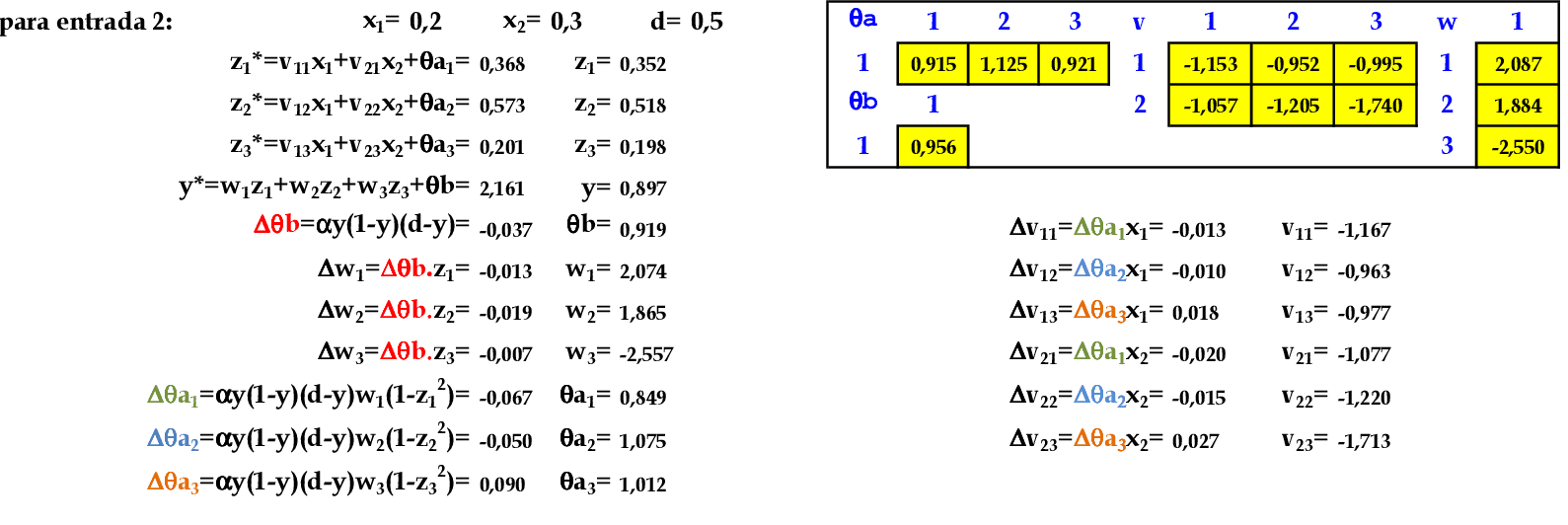
Apresentamos o padrão de entrada (0.2, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.4) para a rede. -

Apresentamos o padrão de entrada (0.4, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.7) para a rede. -

No final da 1ª iteração, temos o erro quadrático E = 0,050. -

Iniciamos a 2ª iteração com a atualização da taxa de aprendizagem, com os cálculos na sequência de apresentação da Série Temporal. -

No final da 4ª iteração, temos o erro quadrático E = 0,030.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal RBF, com 2 centros: (1, 0.9) e (0.6, 0.4).
-
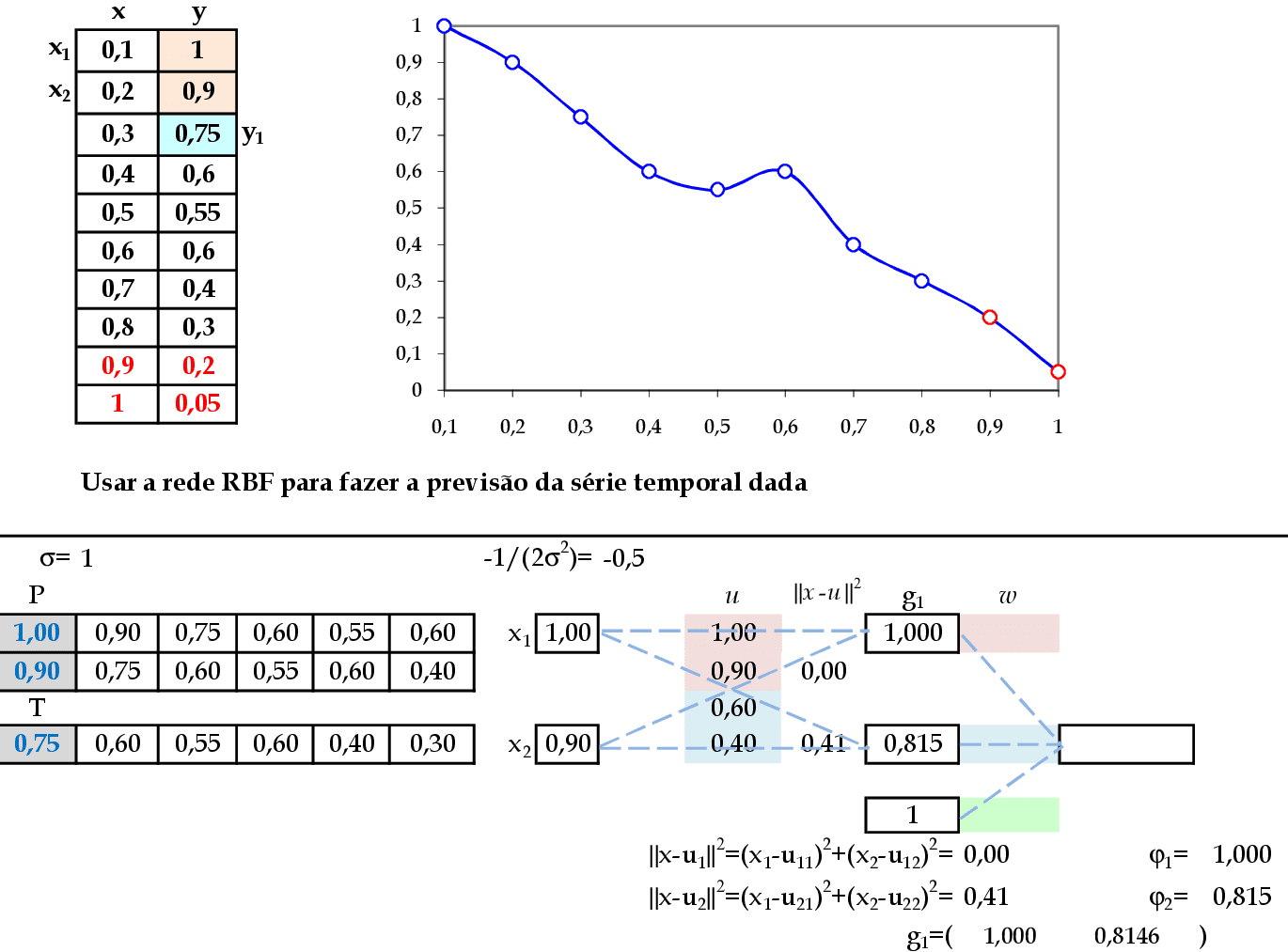
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.75; (0.9, 0.75) para prever 0.6; e assim sucessivamente. Apresentamos o primeiro padrão de entrada para a rede: (1, 0.9). -
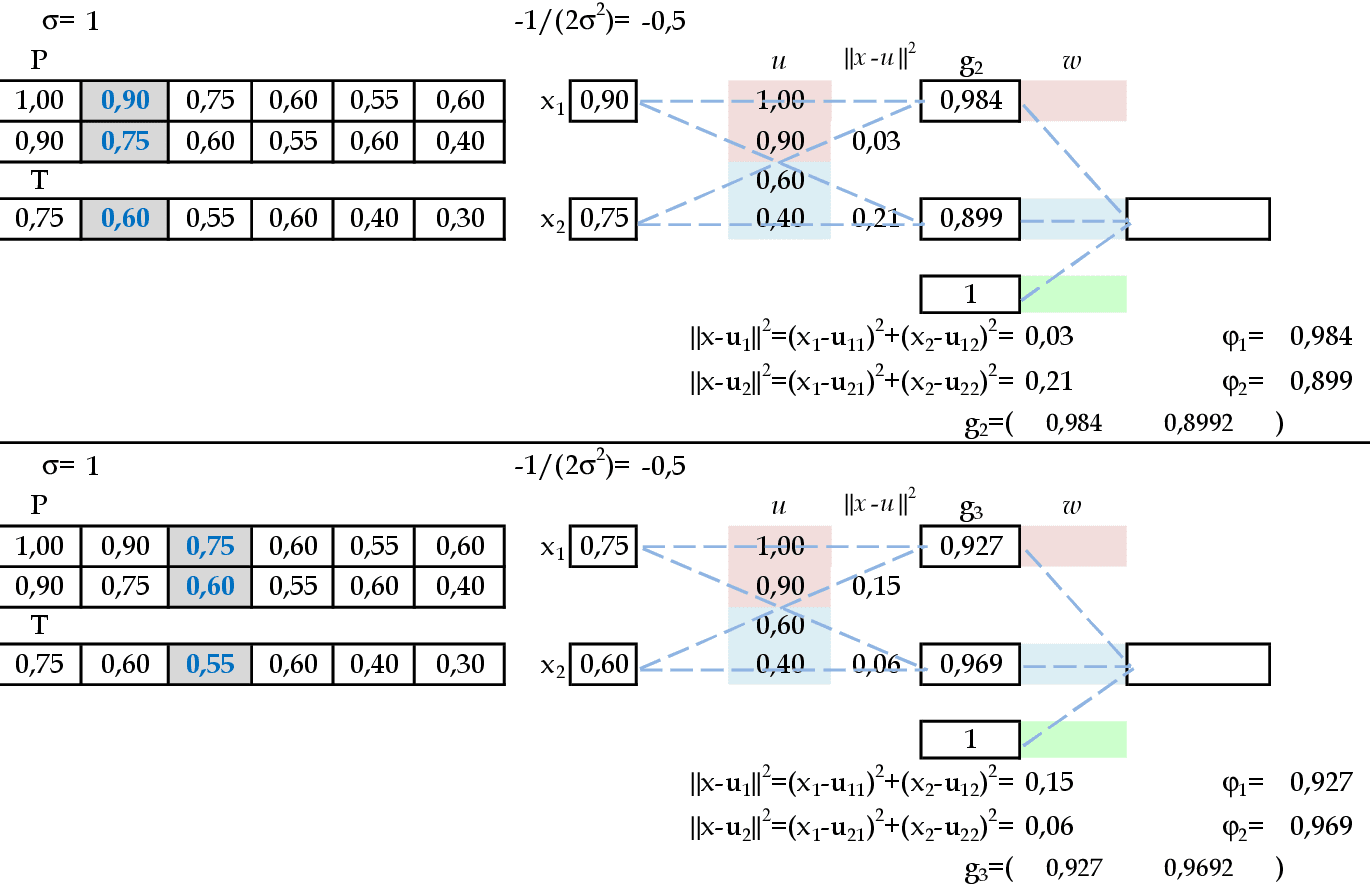
Apresentamos os padrões de entrada (0.9, 0.75) e (0.75, 0,6) para a rede. -

Apresentamos os padrões de entrada (0.6, 0.55) e (0.55, 0,6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.4) para a rede e podemos calcular os pesos. -

Utilizando as 6 linhas da matriz G, calculamos os pesos para a Rede RBF. -
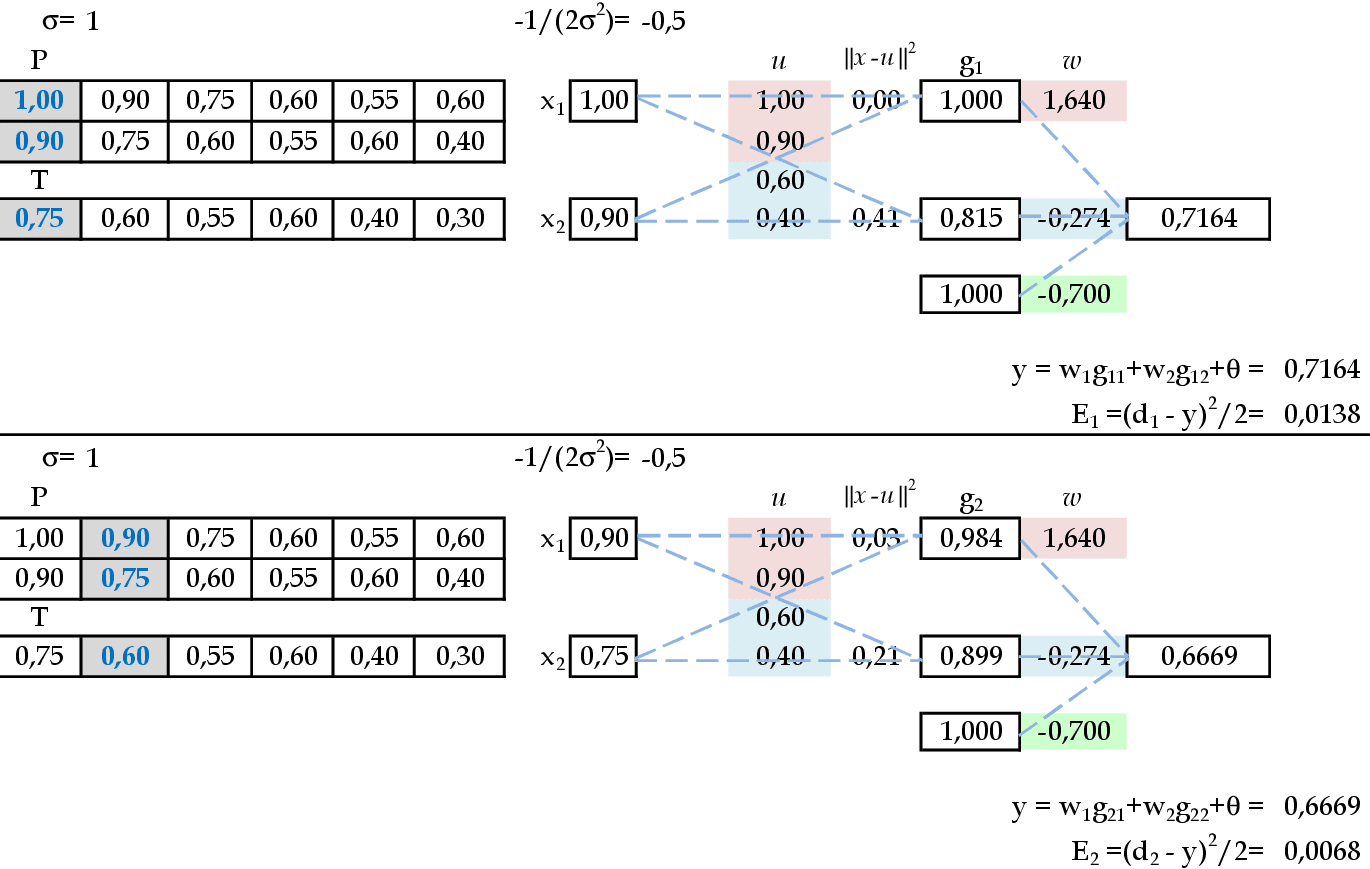
Apresentamos os padrões de entrada (1, 0.9) e (0.9, 0.75) para a rede. -
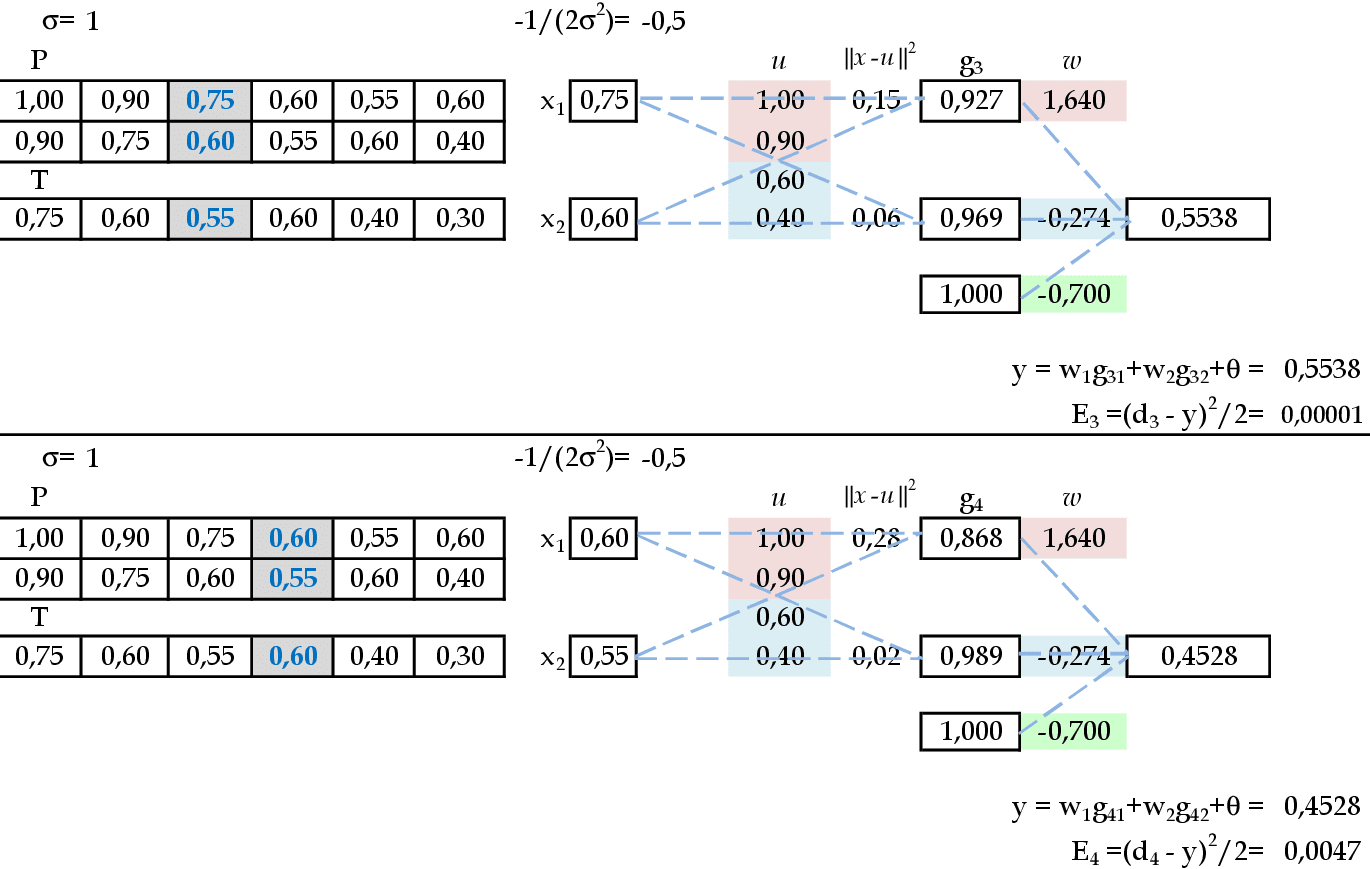
Apresentamos os padrões de entrada (0.75, 0.6) e (0.6, 0.55) para a rede. -
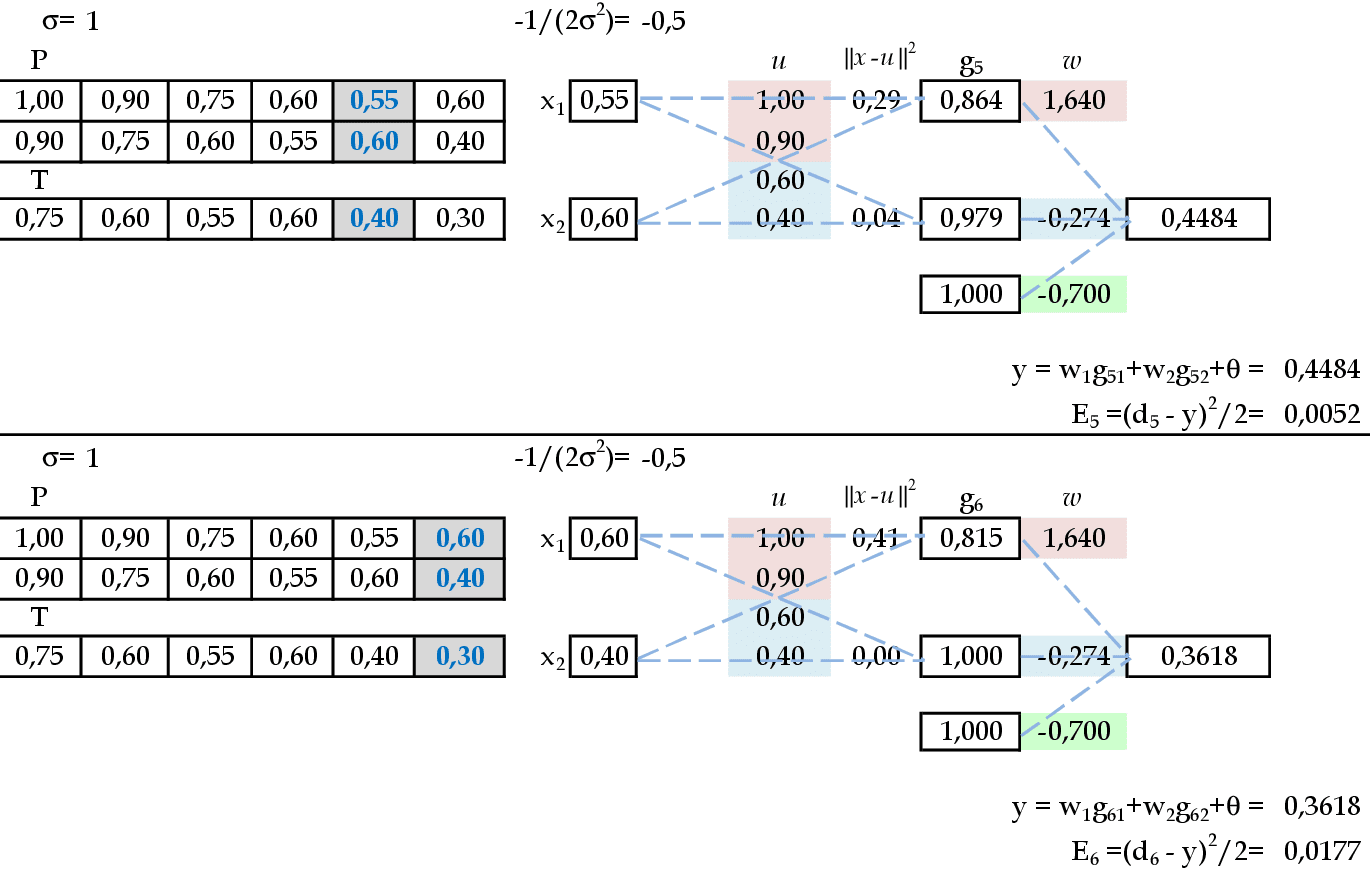
Apresentamos os padrões de entrada (0.55, 0.6) e (0.6, 0.4) para a rede. -

Apresentamos os padrões do conjunto de testes: (0.4, 0.3) e (0.3, 0.2) para a rede. -
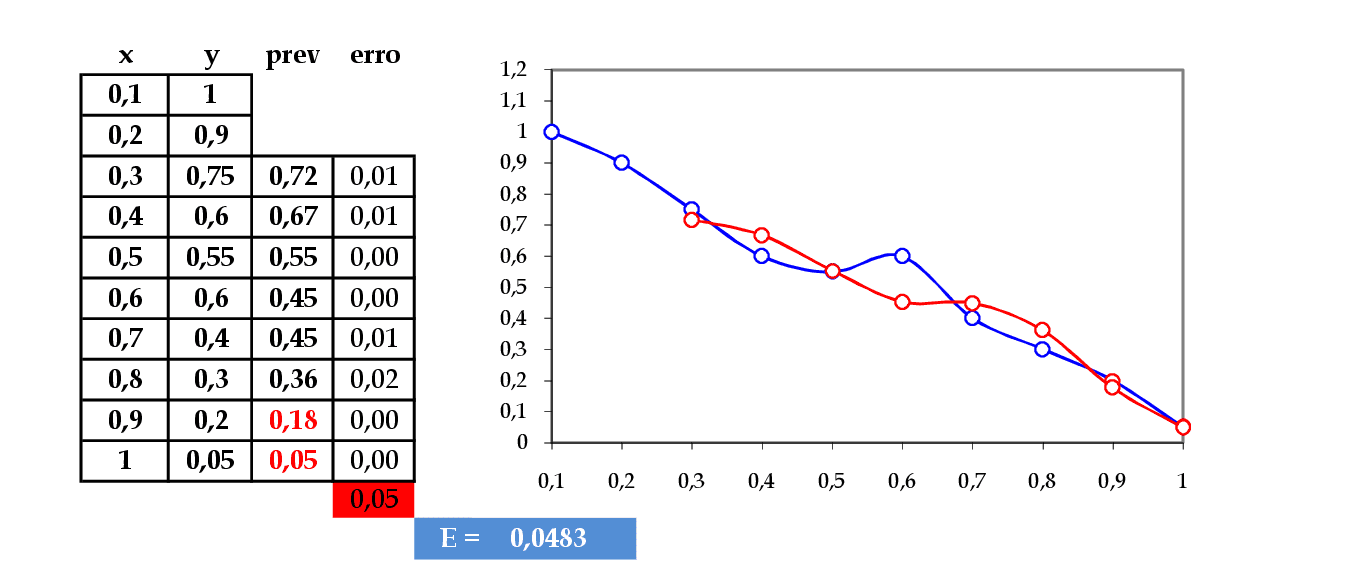
Temos o erro quadrático desta rede E = 0,0483.
Resolva o problema de classificação do Exercício 7 usando uma rede RBF com 3 centros.

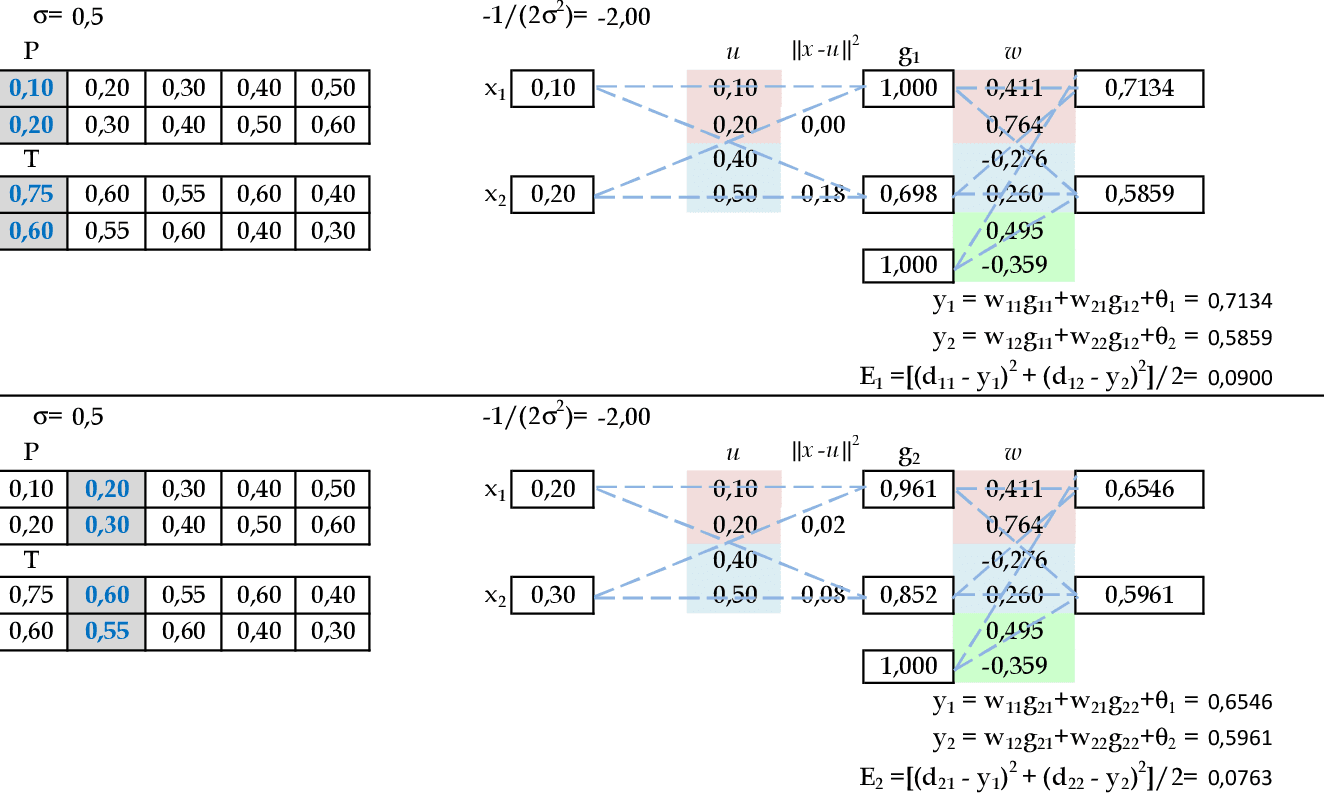
📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal RBF, com 2 centros: (0.2, 0.3) e (0.5, 0.6).
-
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (0.1, 0.2) para prever 0.75; (0.2, 0.3) para prever 0.6; e assim sucessivamente. Apresentamos o primeiro padrão de entrada para a rede: (0.1, 0.2). -
Apresentamos os padrões de entrada (0.2, 0.3) e (0.3, 0.4) para a rede. -
Apresentamos os padrões de entrada (0.4, 0.5) e (0.5, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.7) para a rede e podemos calcular os pesos. -

Utilizando as 6 linhas da matriz G, calculamos os pesos para a Rede RBF. -
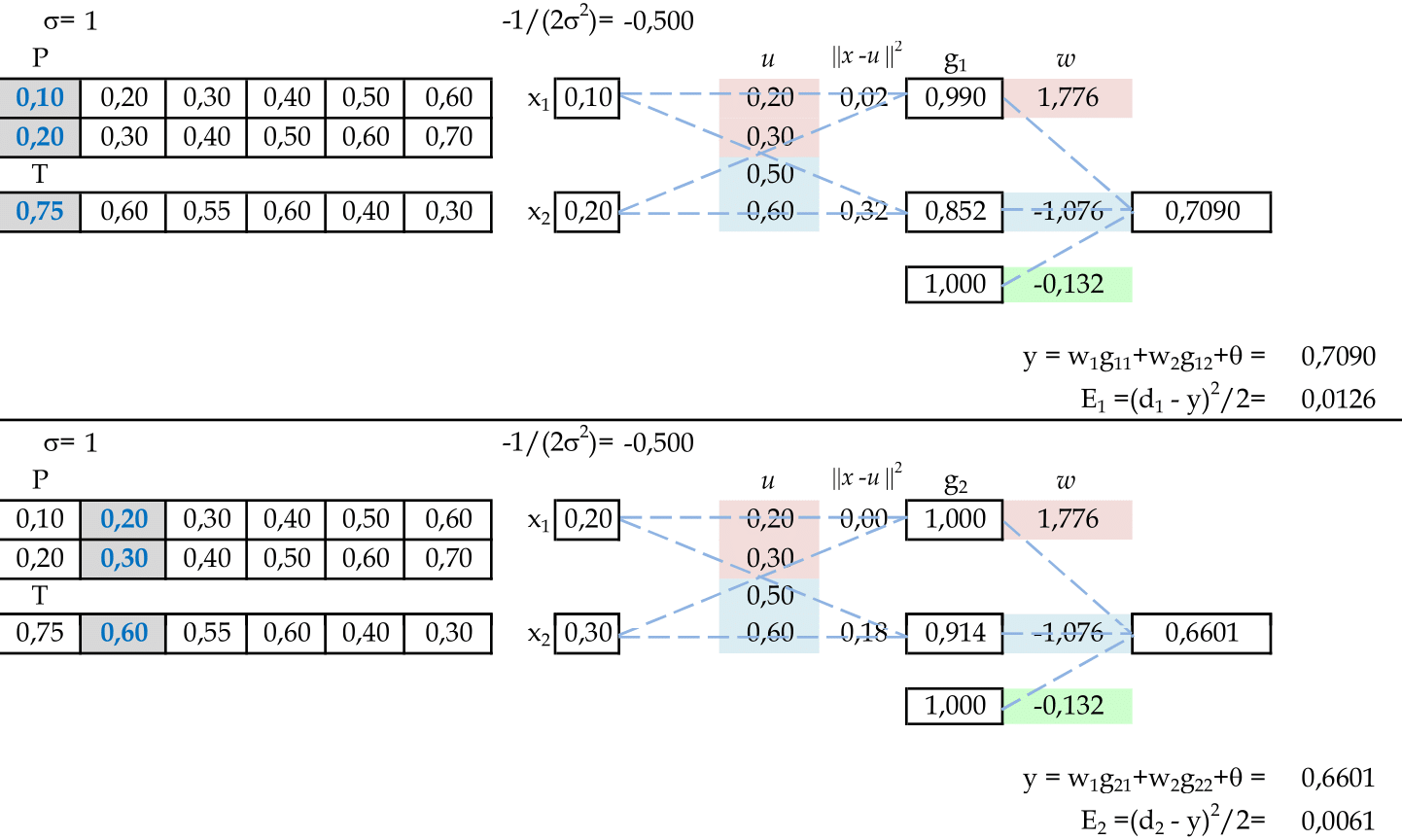
Apresentamos os padrões de entrada (0.1, 0.2) e (0.2, 0.3) para a rede. -
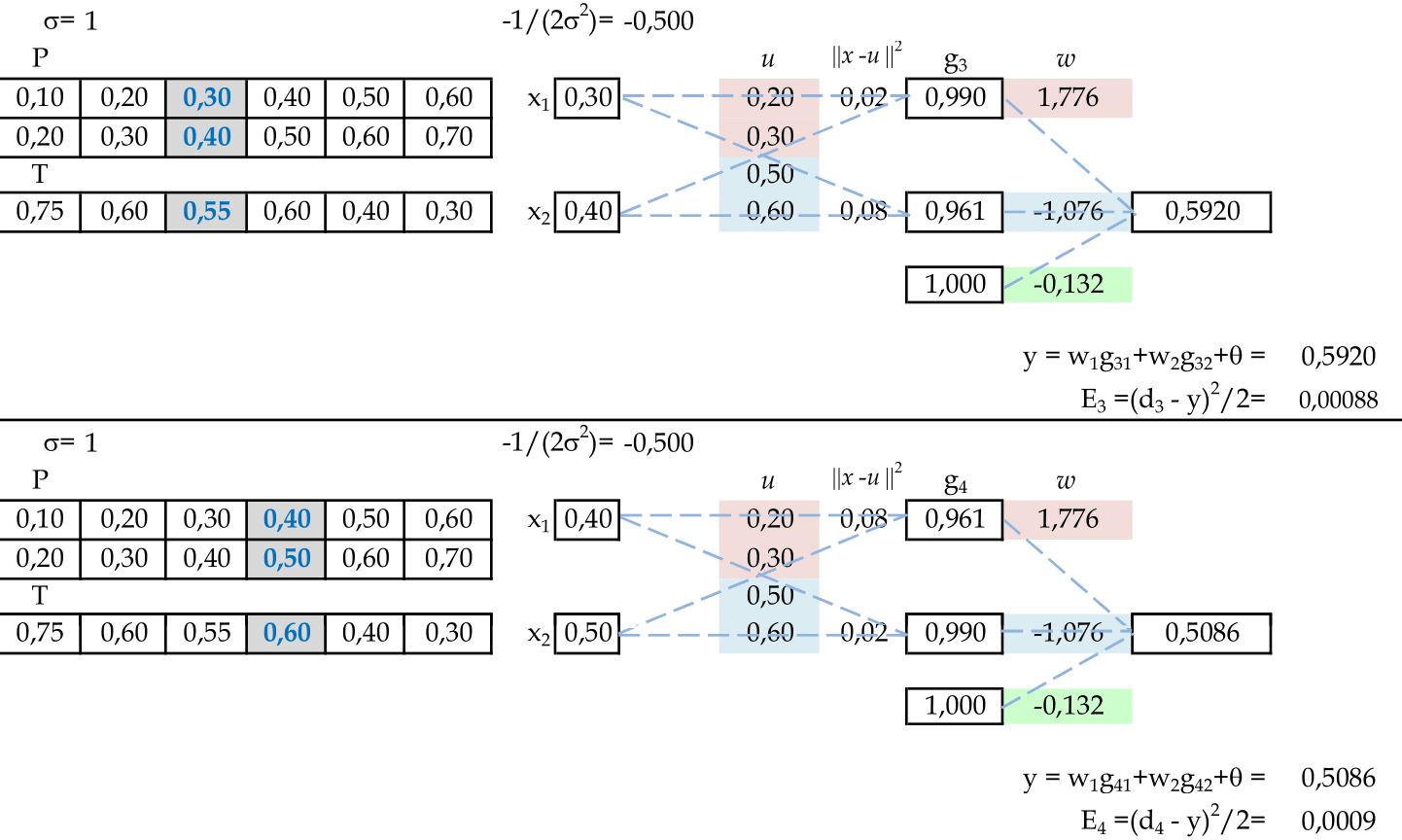
Apresentamos os padrões de entrada (0.3, 0.4) e (0.4, 0.5) para a rede. -
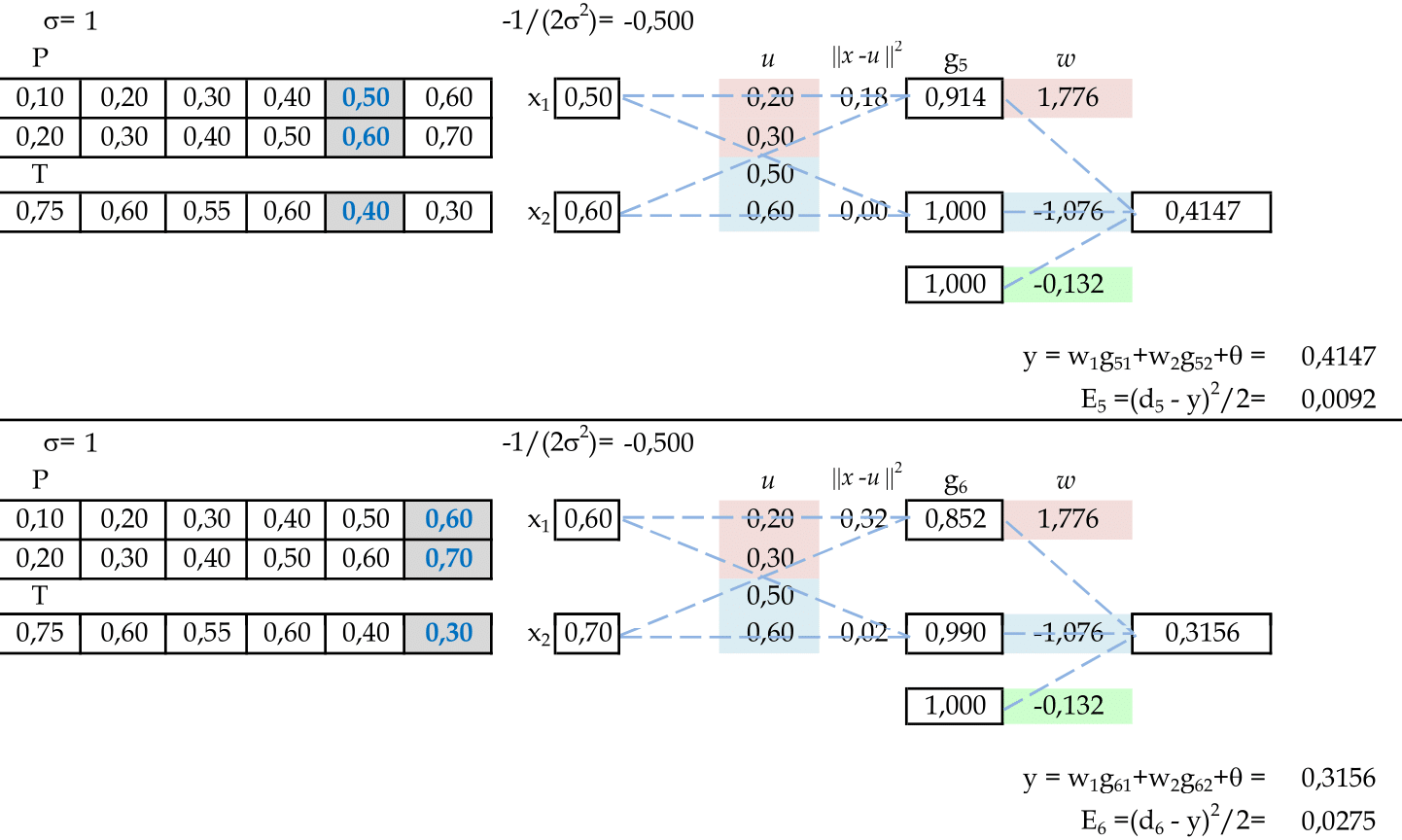
Apresentamos os padrões de entrada (0.5, 0.6) e (0.6, 0.7) para a rede. -

Apresentamos os padrões do conjunto de testes: (0.7, 0.8) e (0.8, 0.9) para a rede. -
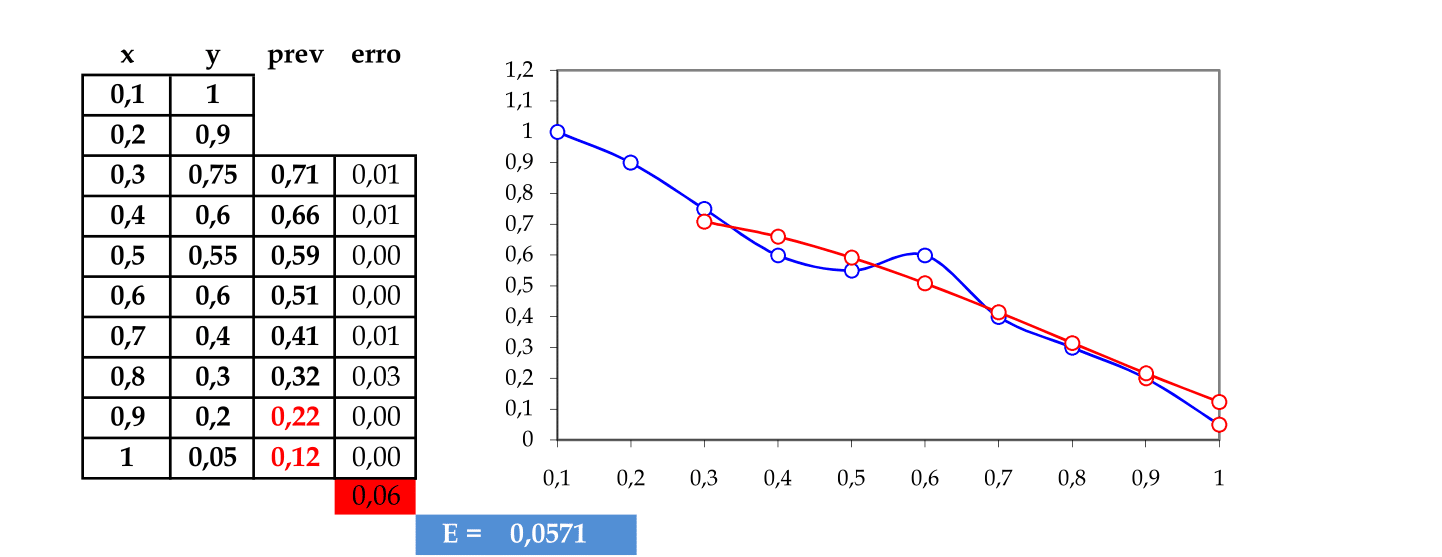
Temos o erro quadrático desta rede E = 0,0574.
Resolva o problema de classificação do Exercício 8 usando uma rede RBF com 3 centros.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal RBF, com 2 centros: (1, 0.9) e (0.55, 0.6).
-
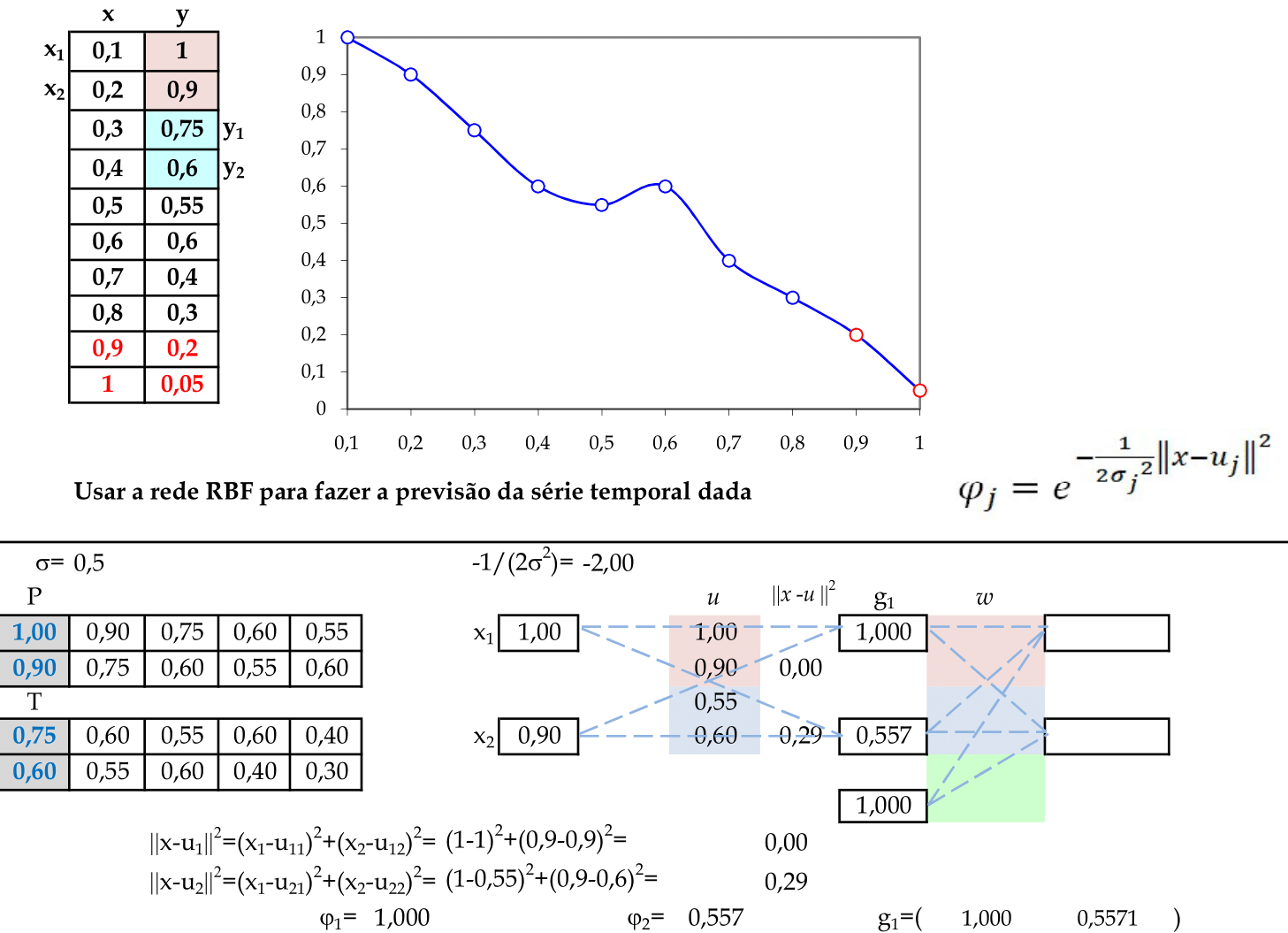
Vamos utilizar os padrões de entrada x para prever 2 passos à frente: (1, 0.9) para prever (0.75, 0.6); (0.75, 0.6) para prever (0.6, 0.55); e assim sucessivamente. Apresentamos o primeiro padrão de entrada para a rede: (1, 0.9). -

Apresentamos os padrões de entrada (0.9, 0.75) e (0.75, 0.6) para a rede. -

Apresentamos os padrões de entrada (0.6, 0.55) e (0.55, 0.6) para a rede. -

Utilizando as 6 linhas da matriz G, calculamos os pesos para a Rede RBF. -

Apresentamos os padrões de entrada (1, 0.9) e (0.9, 0.75) para a rede. -

Apresentamos os padrões de entrada (0.75, 0.6) e (0.6, 0.55) para a rede. -

Apresentamos o padrão de entrada (0.55, 0.6) para a rede, finalizando o conjunto de treinamento. -

Apresentamos os padrões do conjunto de testes: (0.6, 0.5) e (0.5, 0.4). -

A rede RBF fica com um erro quadrático E = 0,2205.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede temporal RBF, com 2 centros: (0.1, 0.2) e (0.4, 0.5).
-
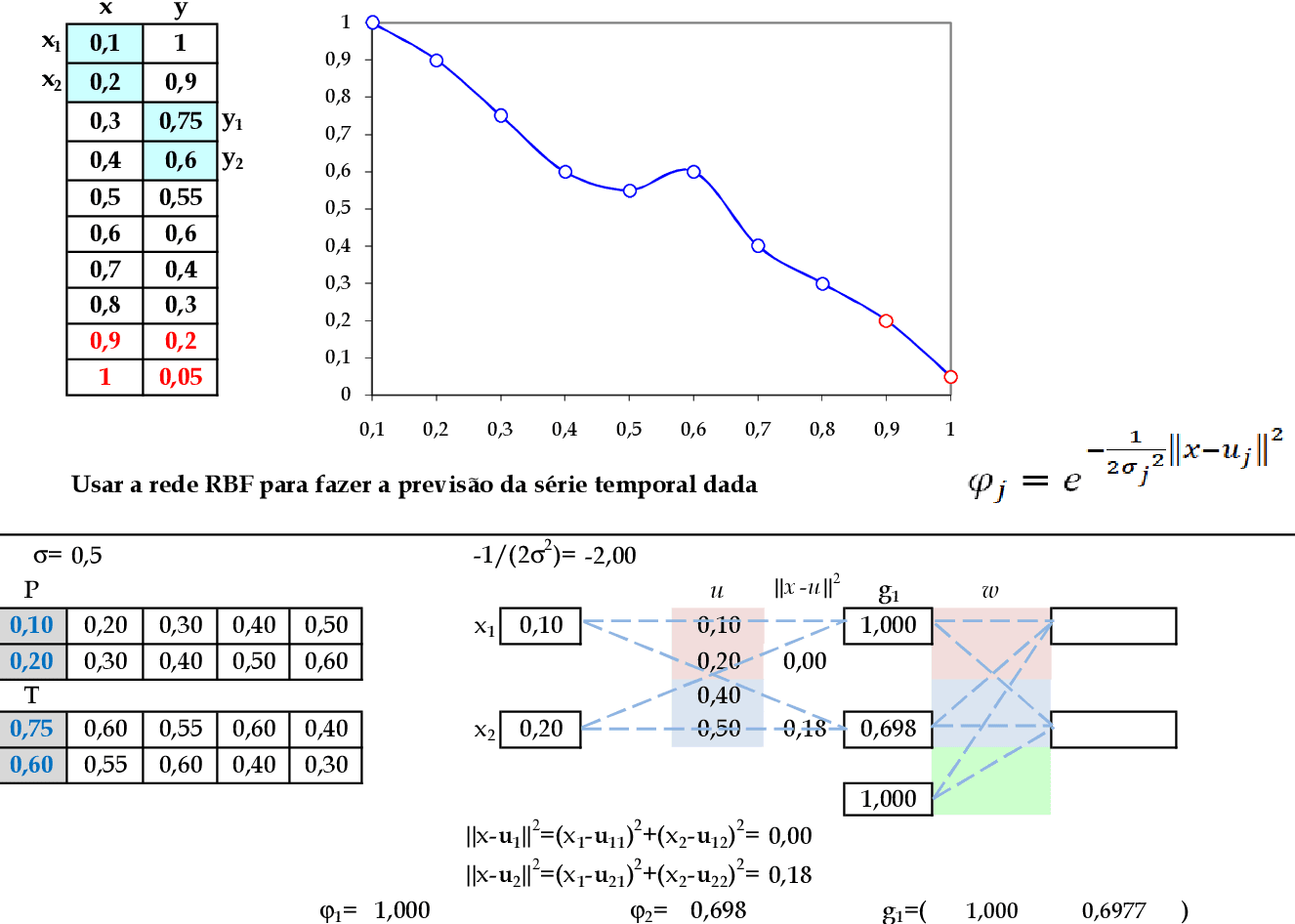
Vamos utilizar os padrões de entrada t para prever 2 passos à frente: (0.1, 0.2) para prever (0.75, 0.6); (0.2, 0.3) para prever (0.6, 0.55); e assim sucessivamente. Apresentamos o primeiro padrão de entrada para a rede: (0.1, 0.2). -
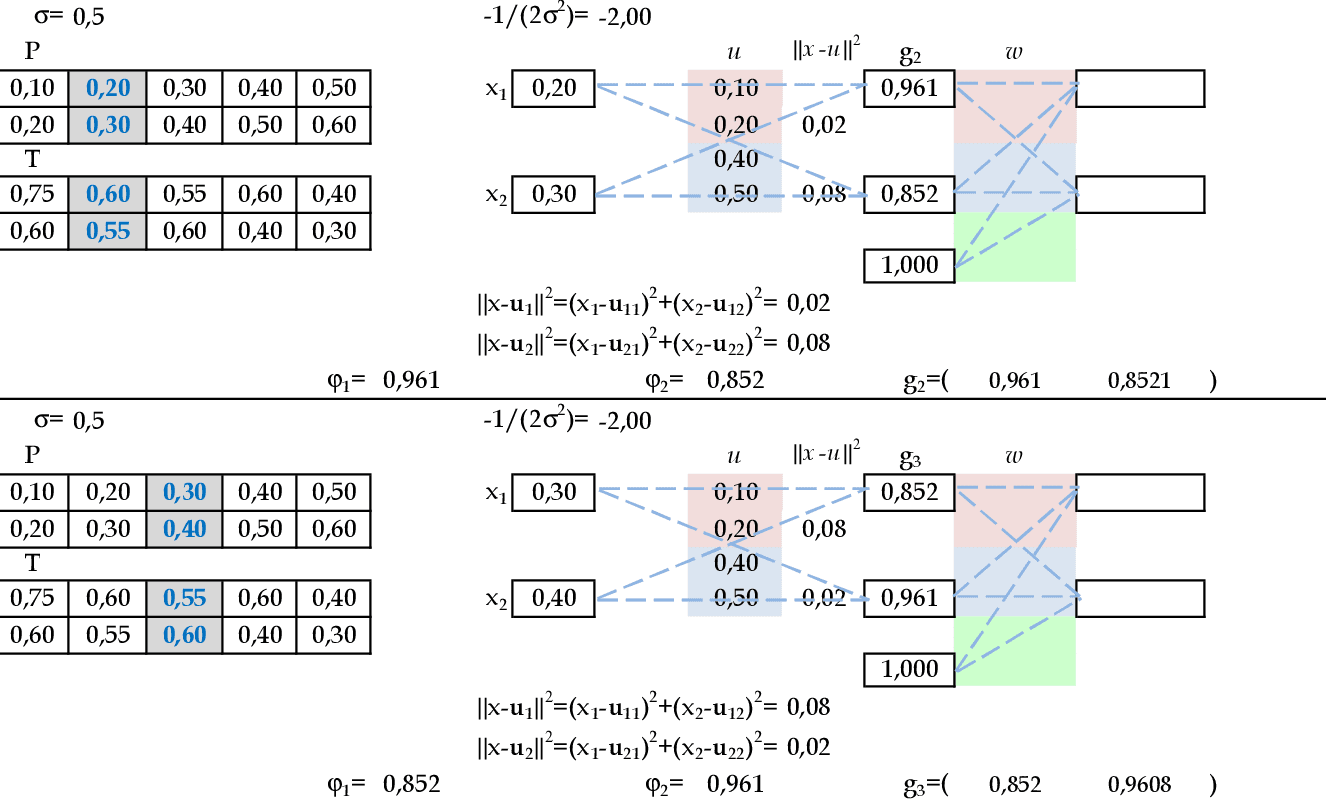
Apresentamos os padrões de entrada (0.2, 0.3) e (0.3, 0.4) para a rede. -

Apresentamos os padrões de entrada (0.4, 0.5) e (0.5, 0.6) para a rede. -
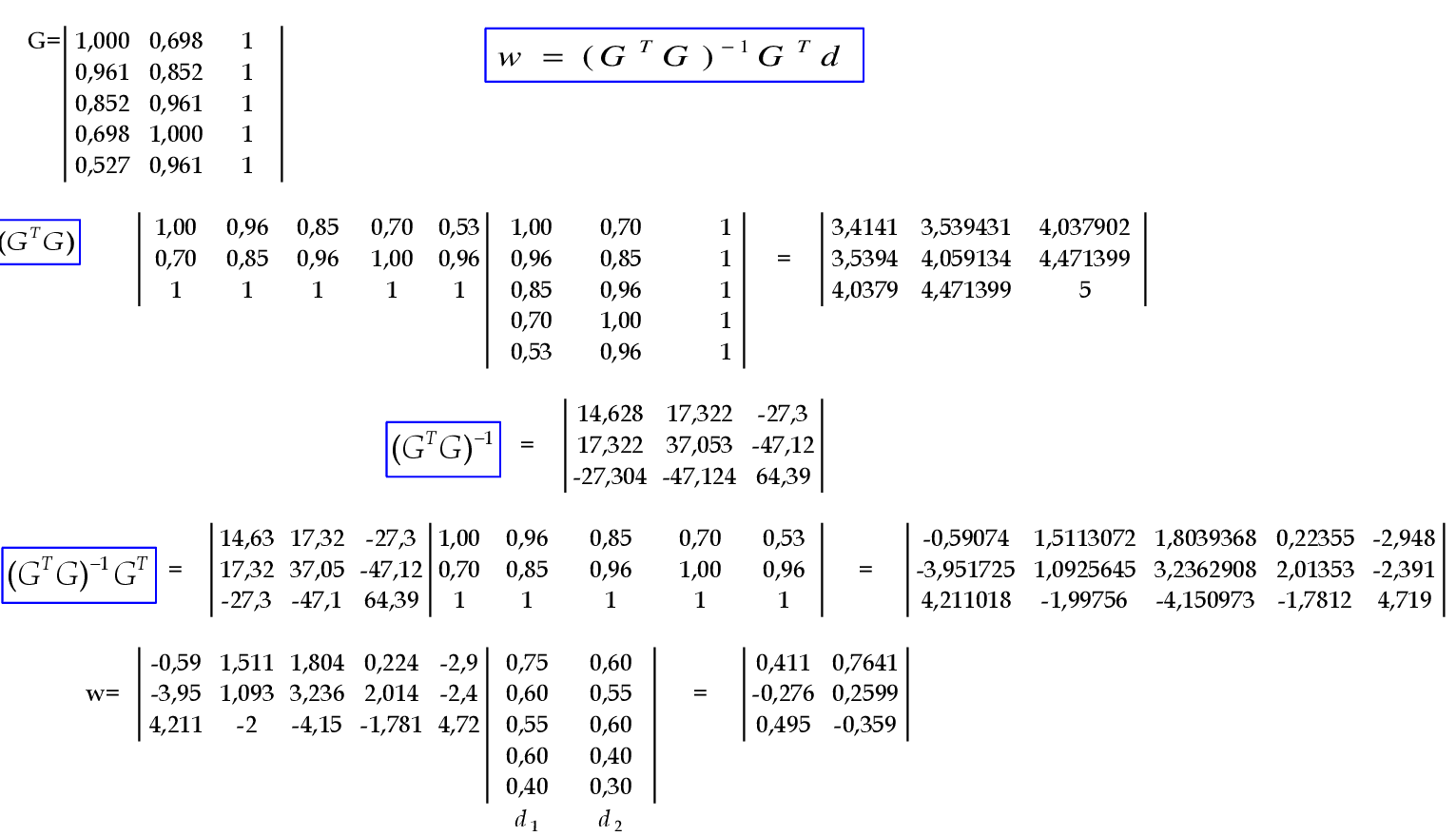
Utilizando as 6 linhas da matriz G, calculamos os pesos para a Rede RBF. -
Apresentamos os padrões de entrada (0.1, 0.2) e (0.2, 0.3) para a rede. -

Apresentamos os padrões de entrada (0.3, 0.4) e (0.4, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.6) para a rede, finalizando o conjunto de treinamento. -

Apresentamos os padrões do conjunto de testes: (0.6, 0.7) e (0.7, 0.8). -
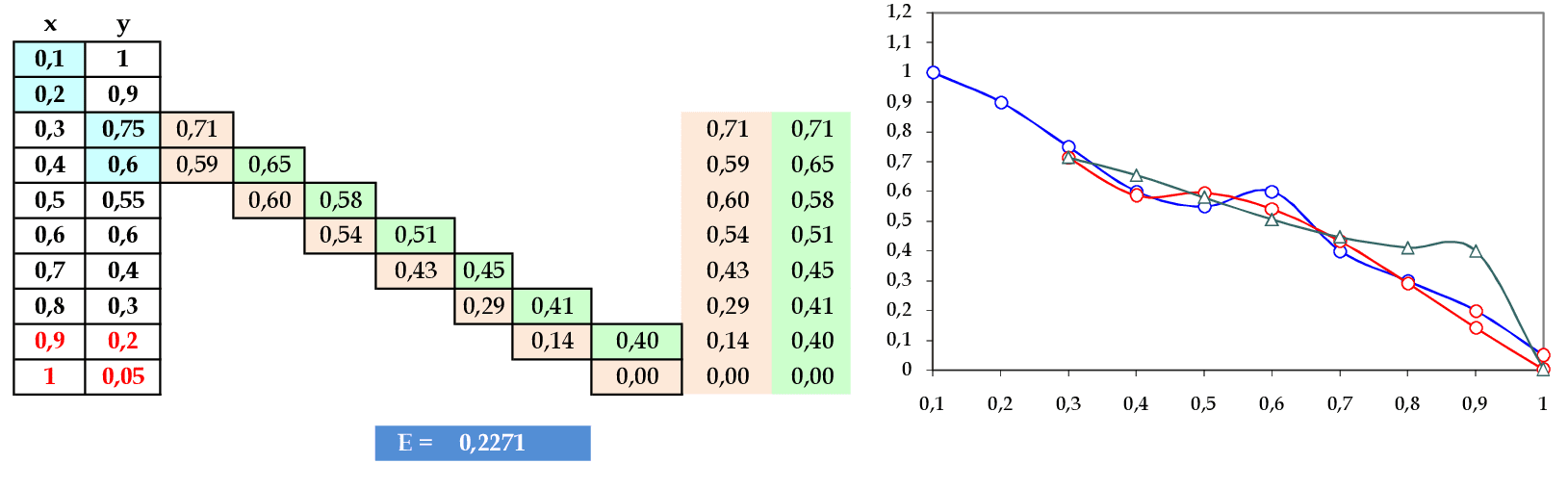
A rede RBF fica com um erro quadrático E = 0,2271.
8. Redes Neurais Recorrentes
Material das páginas 75 até 80.



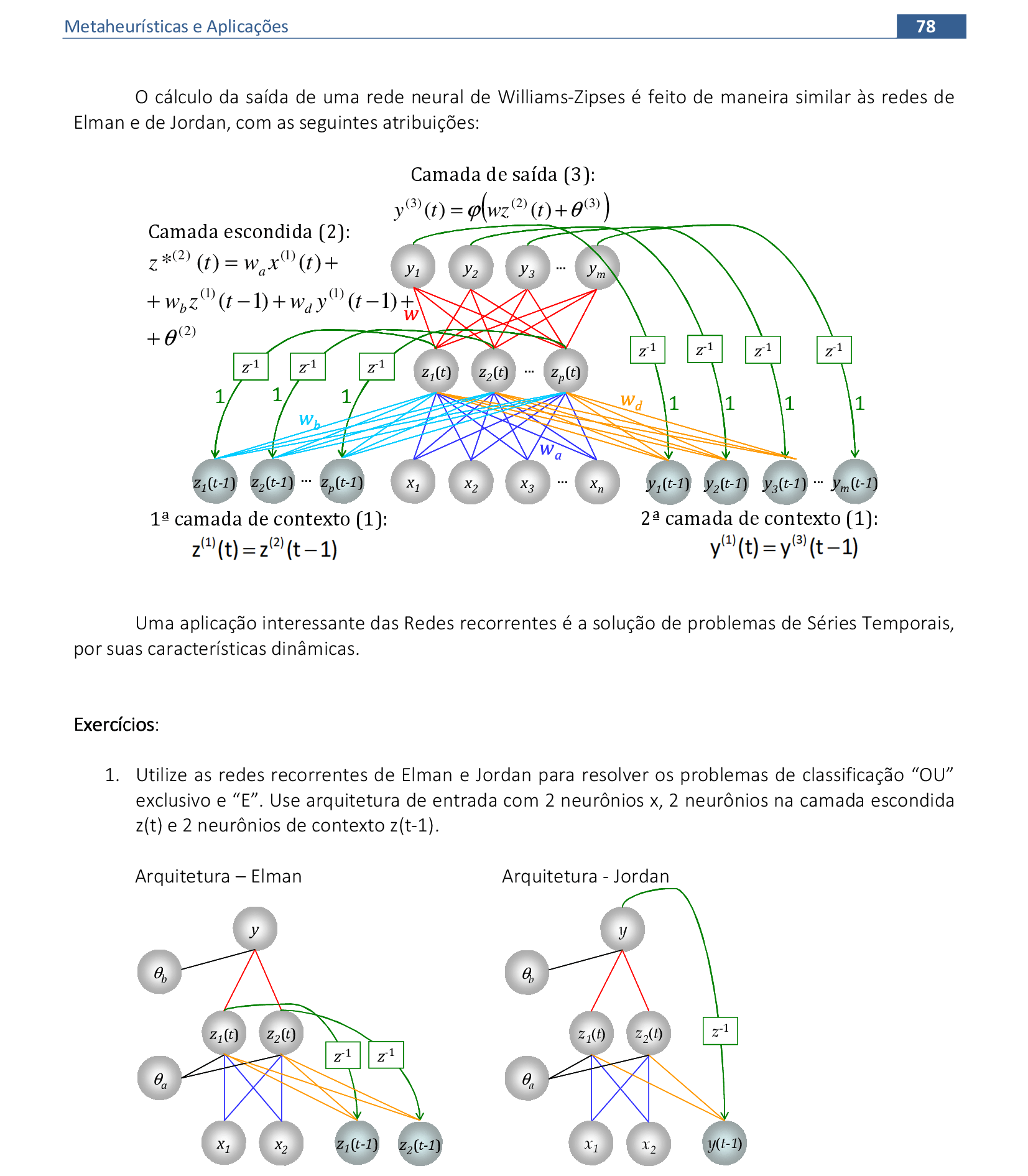

📃 Resolução
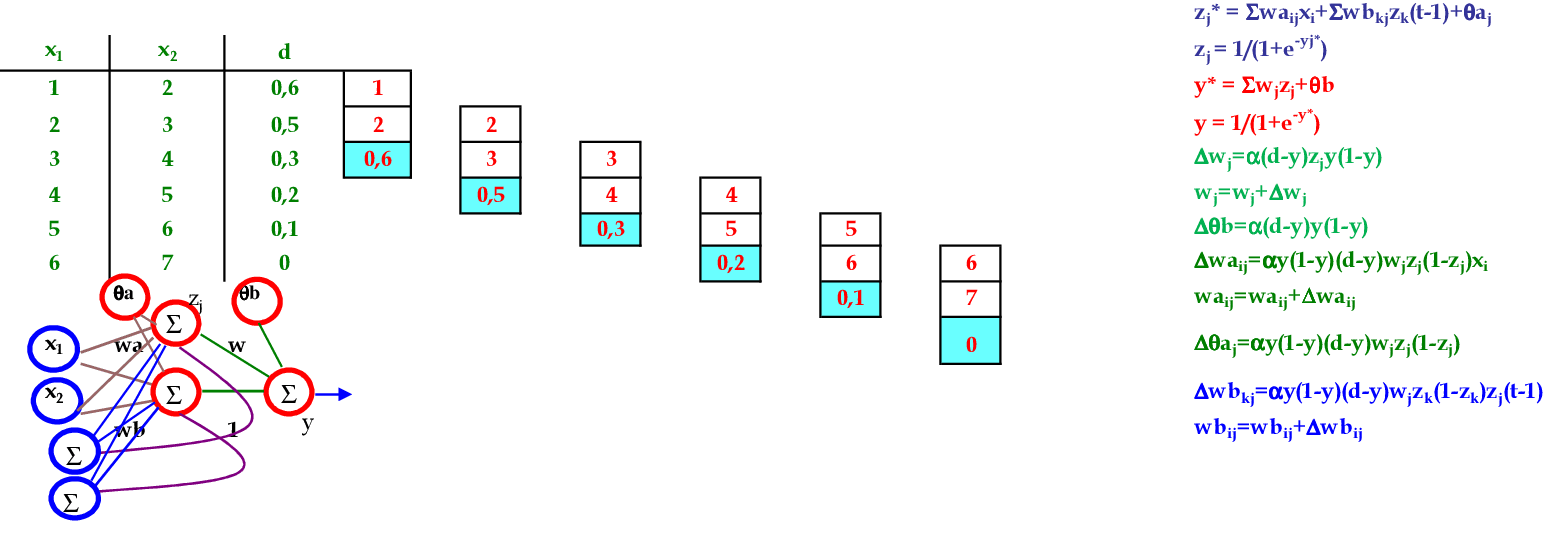
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede recorrente de Elman, com 2 neurônios na camada escondida.
-
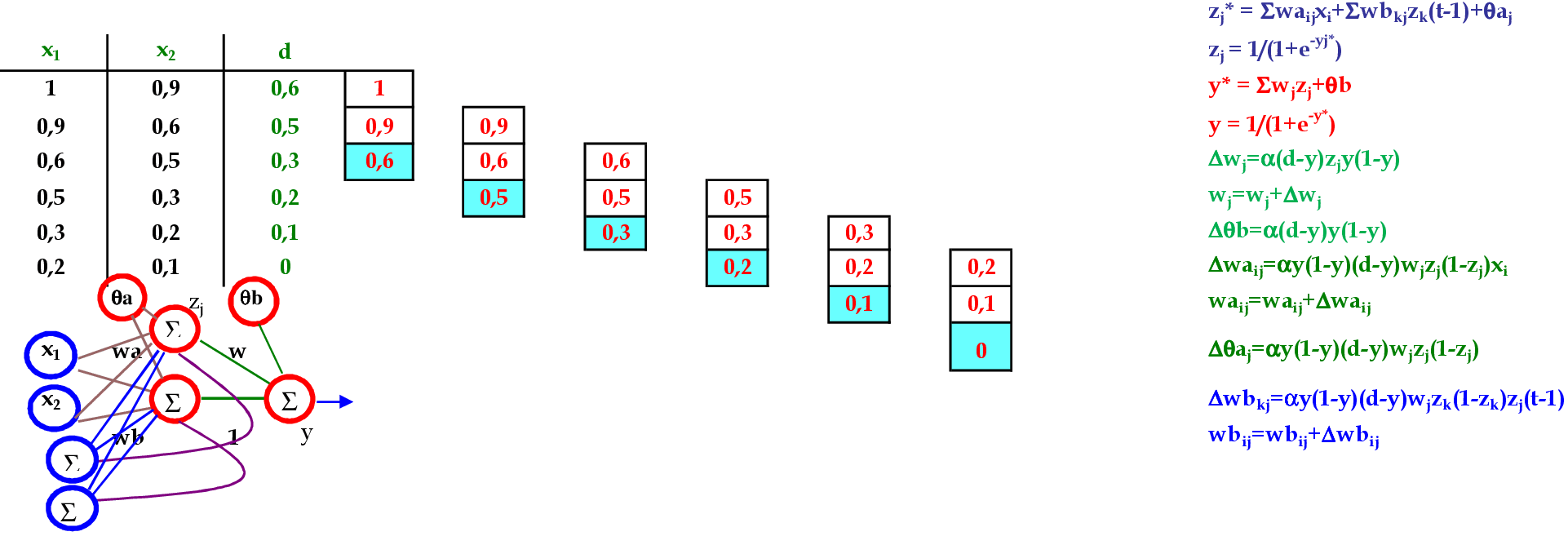
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.6; (0.9, 0.6) para prever 0.5; e assim sucessivamente. -

Apresentamos o padrão de entrada (1, 0.9) para a rede. O peso inicial dos neurônios recorrentes z1(t−1) e z2(t−1) começa com valor 1. -

Apresentamos o padrão de entrada (0.9, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.2) para a rede. -

Apresentamos o padrão de entrada (0.2, 0.1) para a rede. -
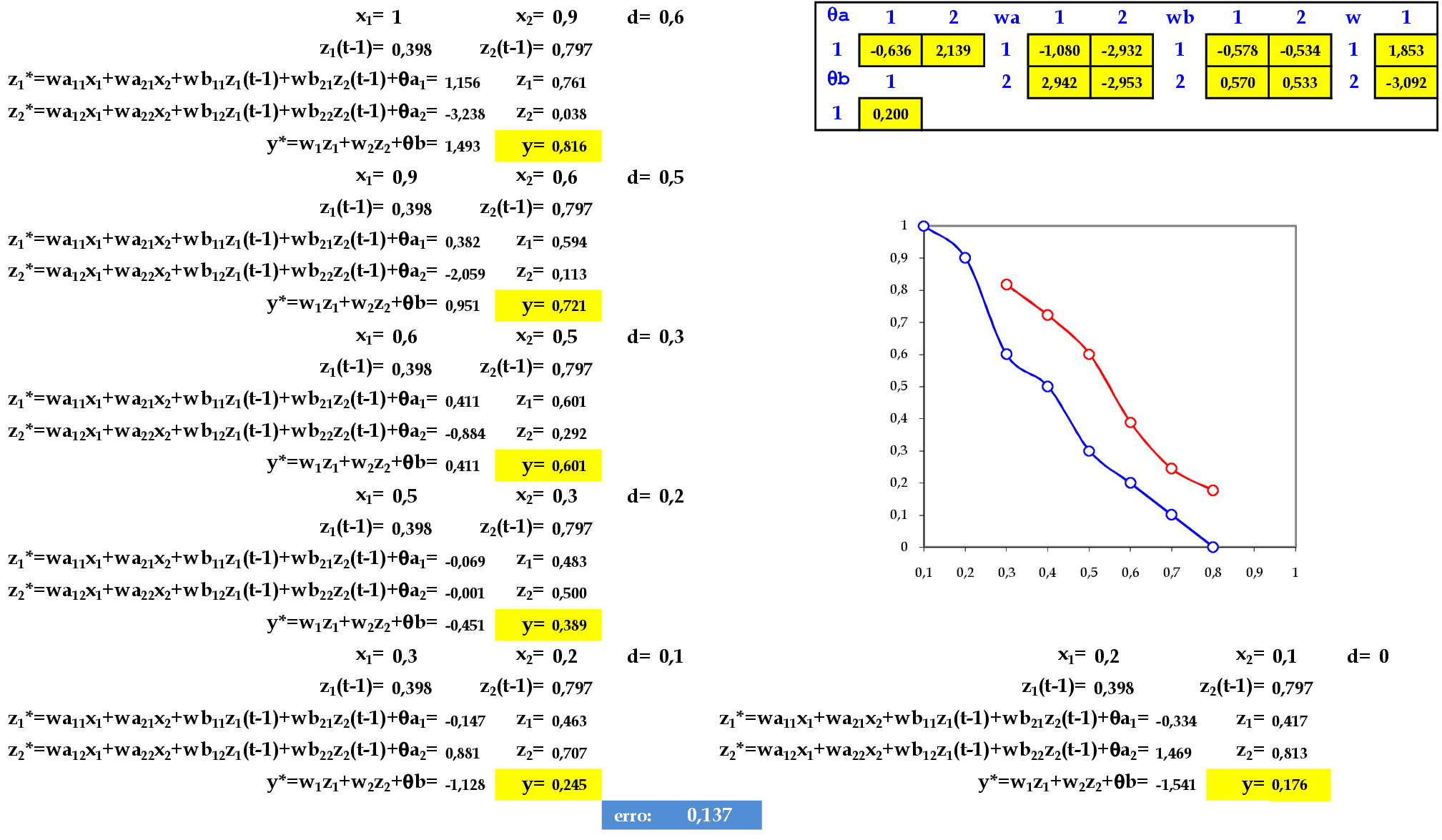
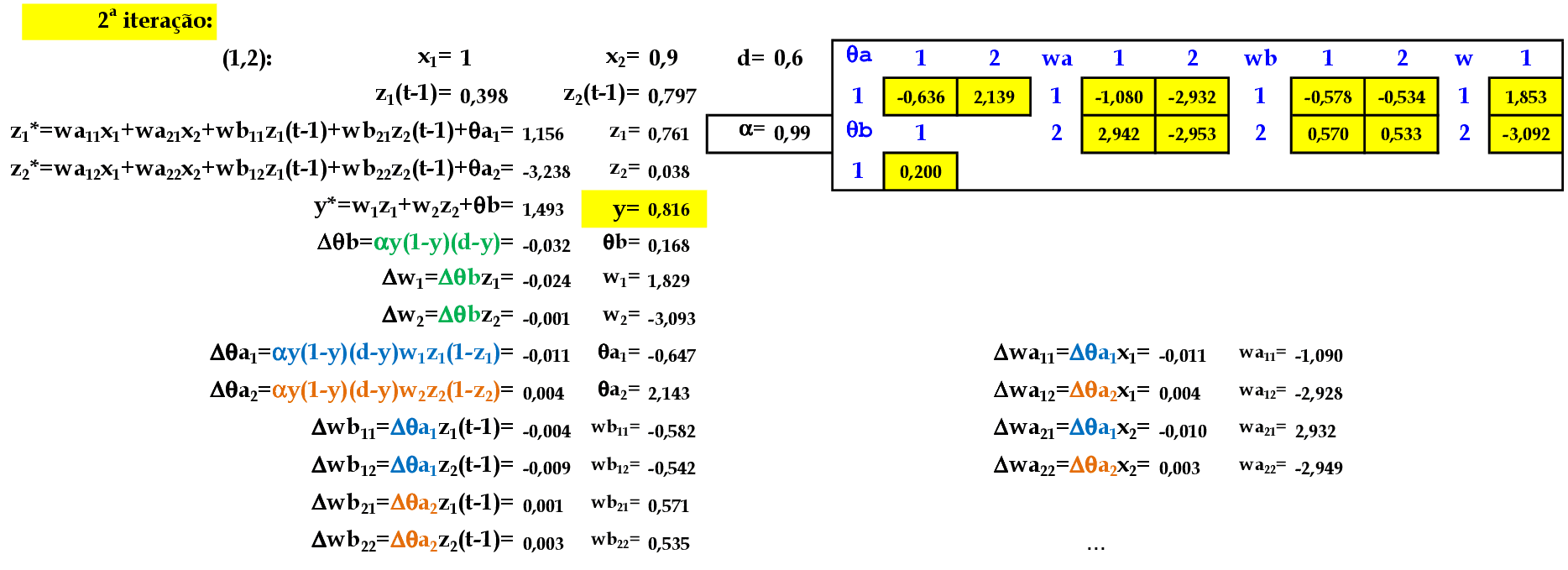
No final da 1ª iteração, temos o erro médio E = 0,137. -
Iniciamos a 2ª iteração com a apresentação do padrão (1, 0.9) para a rede. -
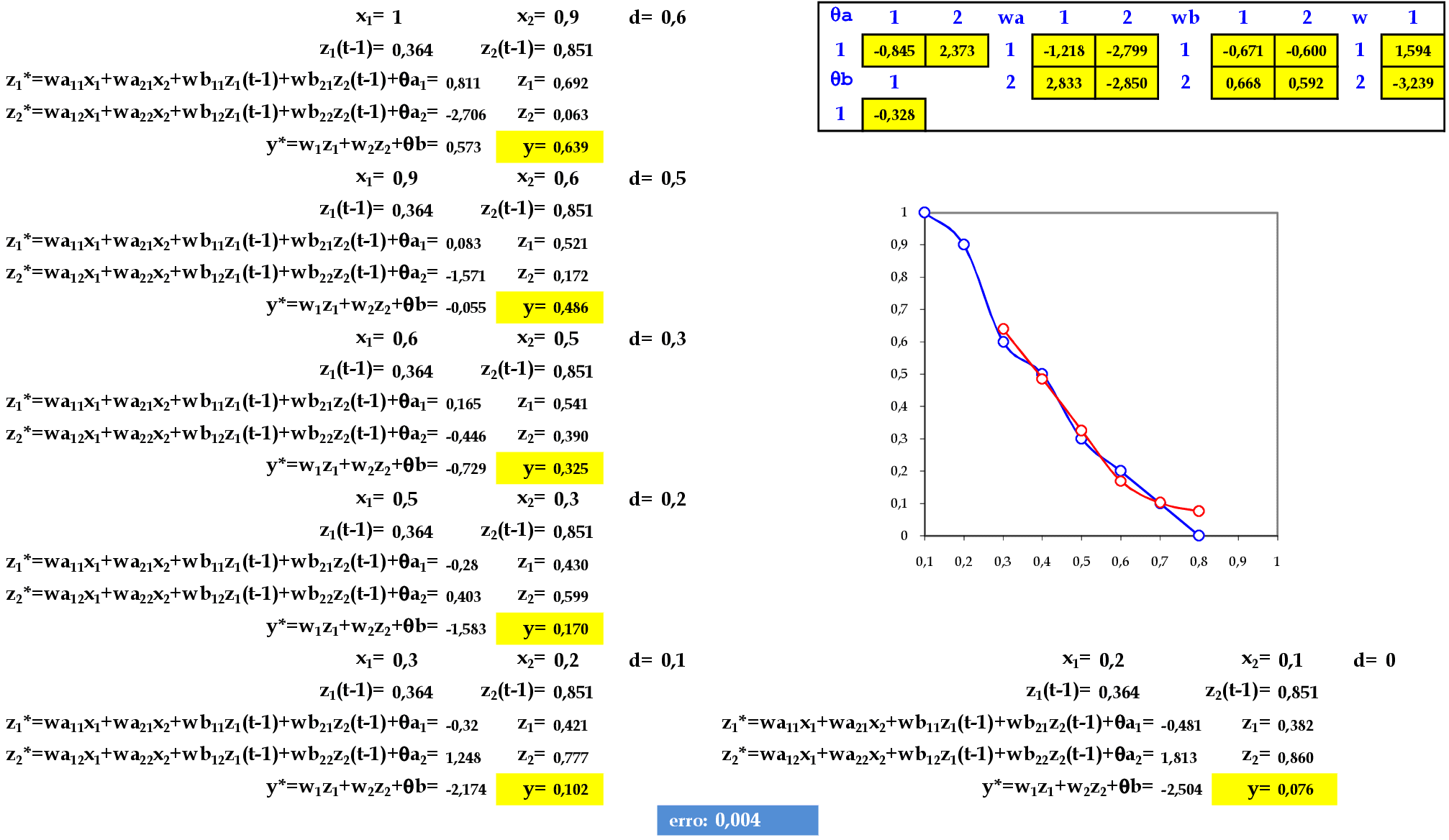
No final da 7ª iteração, temos o erro médio E = 0,004.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede recorrente de Elman, com 2 neurônios na camada escondida.
-
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (1, 2) para prever 0.6; (2, 3) para prever 0.5; e assim sucessivamente. -
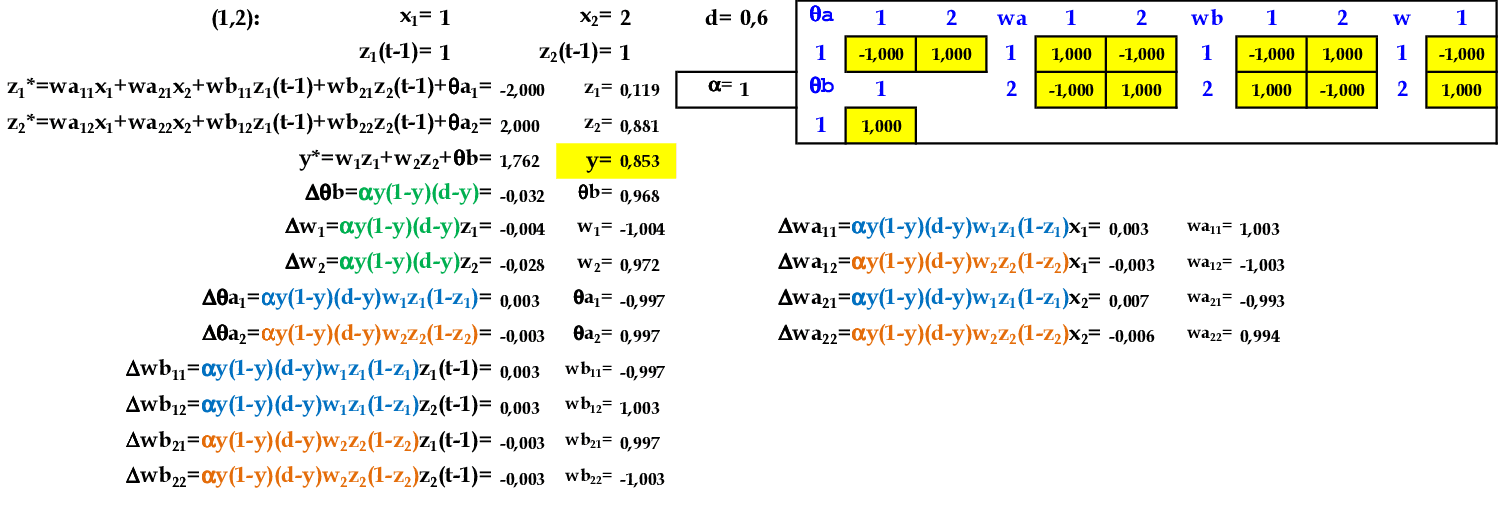
Apresentamos o padrão de entrada (1, 2) para a rede. O peso inicial dos neurônios recorrentes z1(t−1) e z2(t−1) começa com valor 1. -

Apresentamos o padrão de entrada (2, 3) para a rede. -

Apresentamos o padrão de entrada (3, 4) para a rede. -

Apresentamos o padrão de entrada (4, 5) para a rede. -

Apresentamos o padrão de entrada (5, 6) para a rede. -
Apresentamos o padrão de entrada (6, 7) para a rede. -

No final da 1ª iteração, temos o erro médio E = 0,198. -

Iniciamos a 2ª iteração com a apresentação do padrão (1, 2) para a rede. -
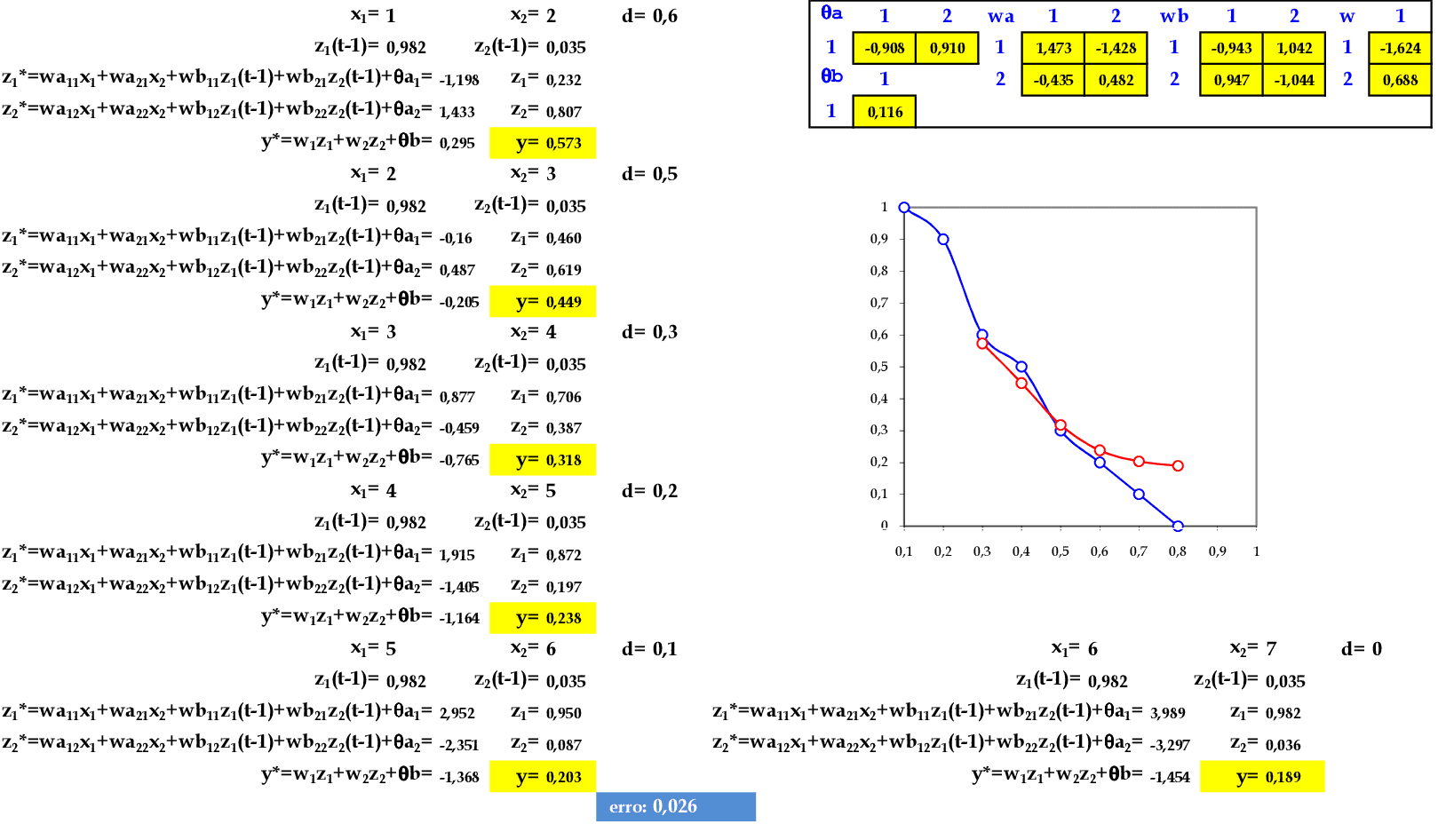
No final da 7ª iteração, temos o erro médio E = 0,026.

📃 Resolução
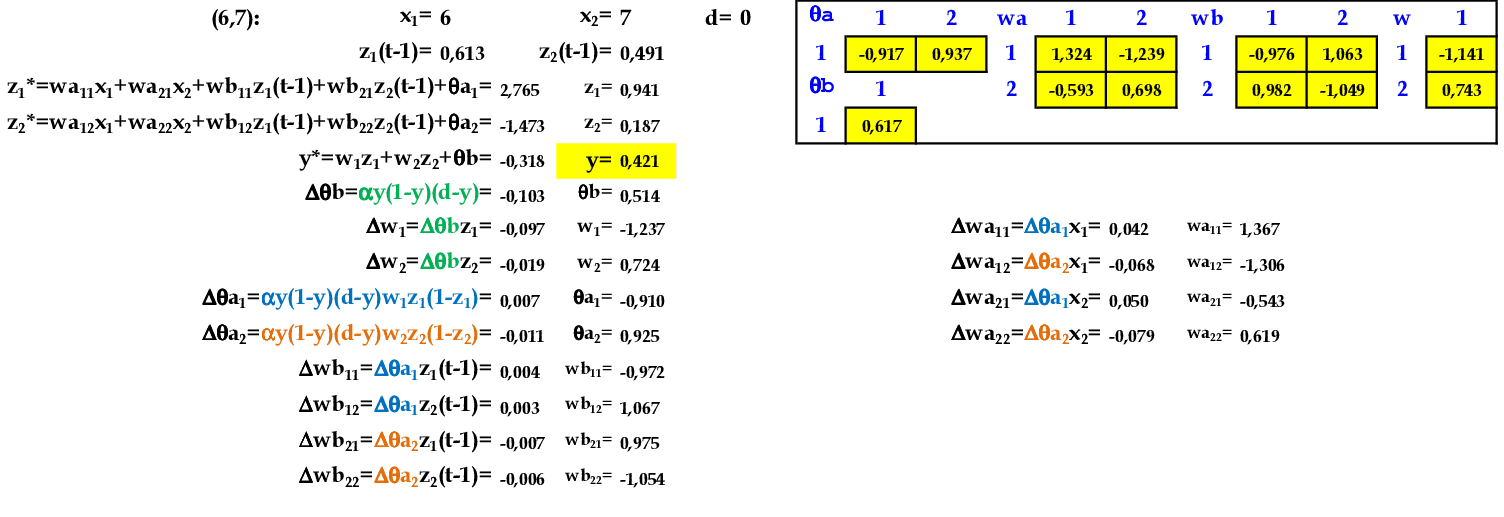
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede recorrente de Jordan, com 2 neurônios na camada escondida.
-
Vamos utilizar os padrões de entrada x para prever 1 passo à frente: (1, 0.9) para prever 0.6; (0.9, 0.6) para prever 0.5; e assim sucessivamente. -

Apresentamos o padrão de entrada (1, 0.9) para a rede. O peso inicial do neurônio recorrente y(t−1) começa com valor 1. -

Apresentamos o padrão de entrada (0.9, 0.6) para a rede. -

Apresentamos o padrão de entrada (0.6, 0.5) para a rede. -

Apresentamos o padrão de entrada (0.5, 0.3) para a rede. -

Apresentamos o padrão de entrada (0.3, 0.2) para a rede. -
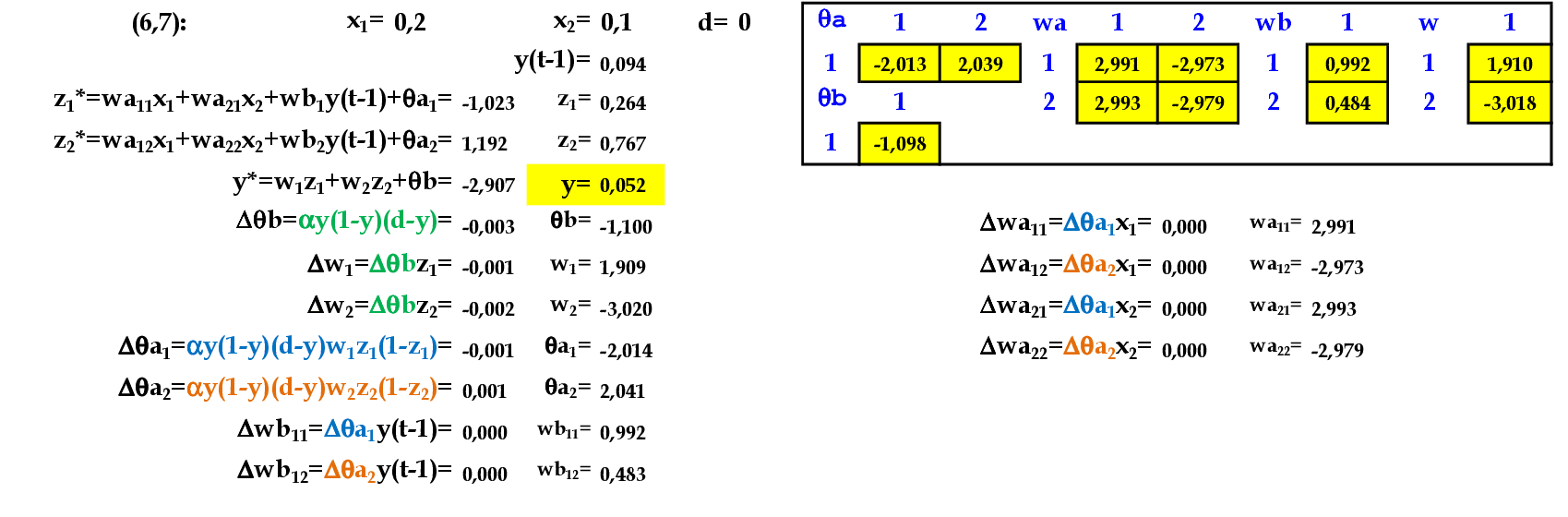
Apresentamos o padrão de entrada (0.2, 0.1) para a rede. -

No final da 1ª iteração, temos o erro médio E = 0,017. -

Iniciamos a 2ª iteração com a apresentação do padrão (1, 0.9) para a rede. -

No final da 7ª iteração, temos o erro médio E = 0,003.

📃 Resolução
Vamos acompanhar os cálculos deste exercício de treinamento de uma rede recorrente de Jordan, com 2 neurônios na camada escondida.
-
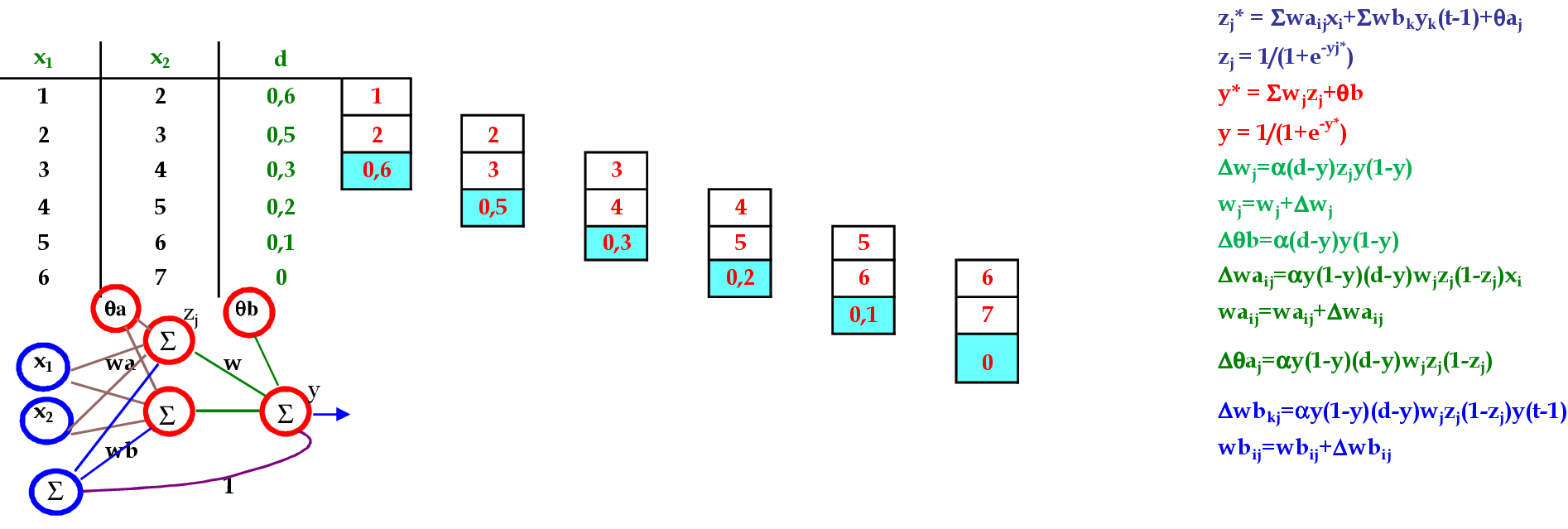
Vamos utilizar os padrões de entrada t para prever 1 passo à frente: (1, 2) para prever 0.6; (2, 3) para prever 0.5; e assim sucessivamente. -

Apresentamos o padrão de entrada (1, 2) para a rede. O peso inicial do neurônio recorrente y(t−1) começa com valor 1. -
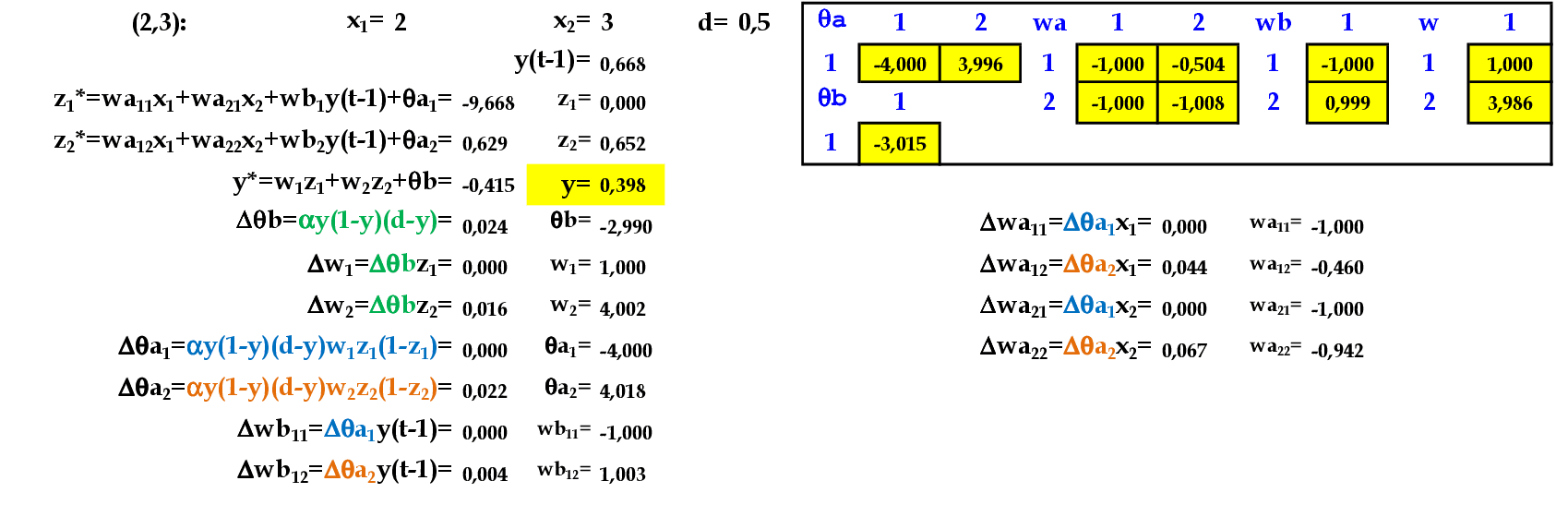
Apresentamos o padrão de entrada (2, 3) para a rede. -

Apresentamos o padrão de entrada (3, 4) para a rede. -

Apresentamos o padrão de entrada (4, 5) para a rede. -

Apresentamos o padrão de entrada (5, 6) para a rede. -

Apresentamos o padrão de entrada (6, 7) para a rede. -

No final da 1ª iteração, temos o erro médio E = 0,017. -

Iniciamos a 2ª iteração com a apresentação do padrão (1, 2) para a rede. -
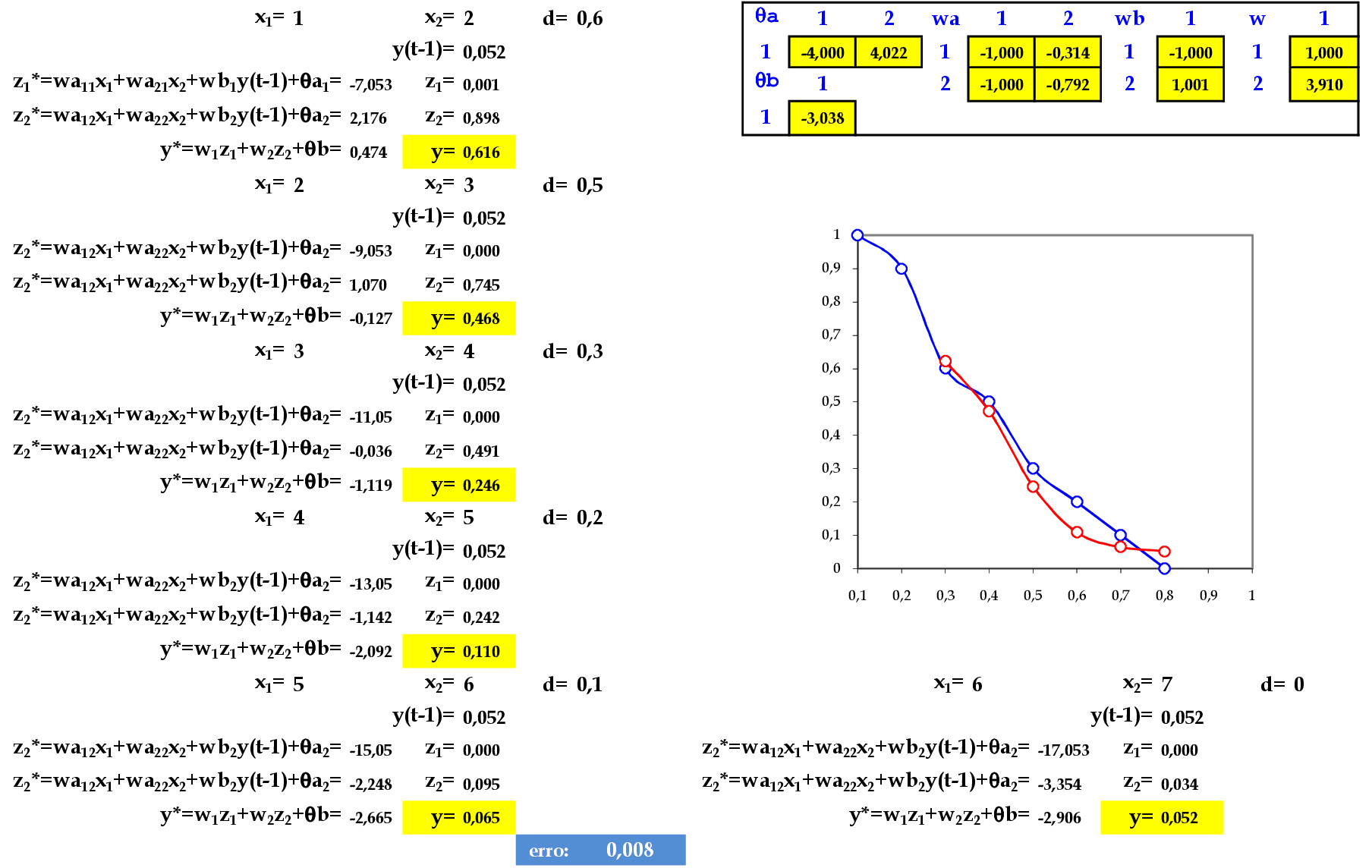
No final da 7ª iteração, temos o erro médio E = 0,008.
Resolva o problema de classificação do Exercício 1 da página 27 usando uma rede de Elman ou de Jordan.

Outras Metaheurísticas
9. Busca Tabu
Material das páginas 82 até 84.


📃 Algoritmo comentado
Faça i = 1 e crie aleatoriamente uma solução Si.
Enquanto iteração_atual ≤ max_iterações, faça:
iteração_atual = iteração_atual + 1.
Crie uma lista de movimentos M = {m1, m2, ..., mk}.
Calcule a função objetivo do problema Si considerando a aplicação de cada movimento mj ∈ M.
Verifique se o critério de aspiração será usado (solução na lista tabu pode ser aceita?).
Escolha mj ∈ M que produz a melhor solução Si+1, tal que tabu(mj) = 0.
Se f(Si+1) ≤ f(Si), então
Si = Si+1
tabu(mj) = 3
i = i + 1
Fim
Atualize a lista tabu: tabu(mq) = tabu(mq) – 1, onde tabu(mq) > 0.
Fim
Fim
📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Busca Tabu para encontrar uma rota para o problema do Caixeiro Viajante. Vamos utilizar k = 3, ou seja, 3 movimentos para cada iteração.
-
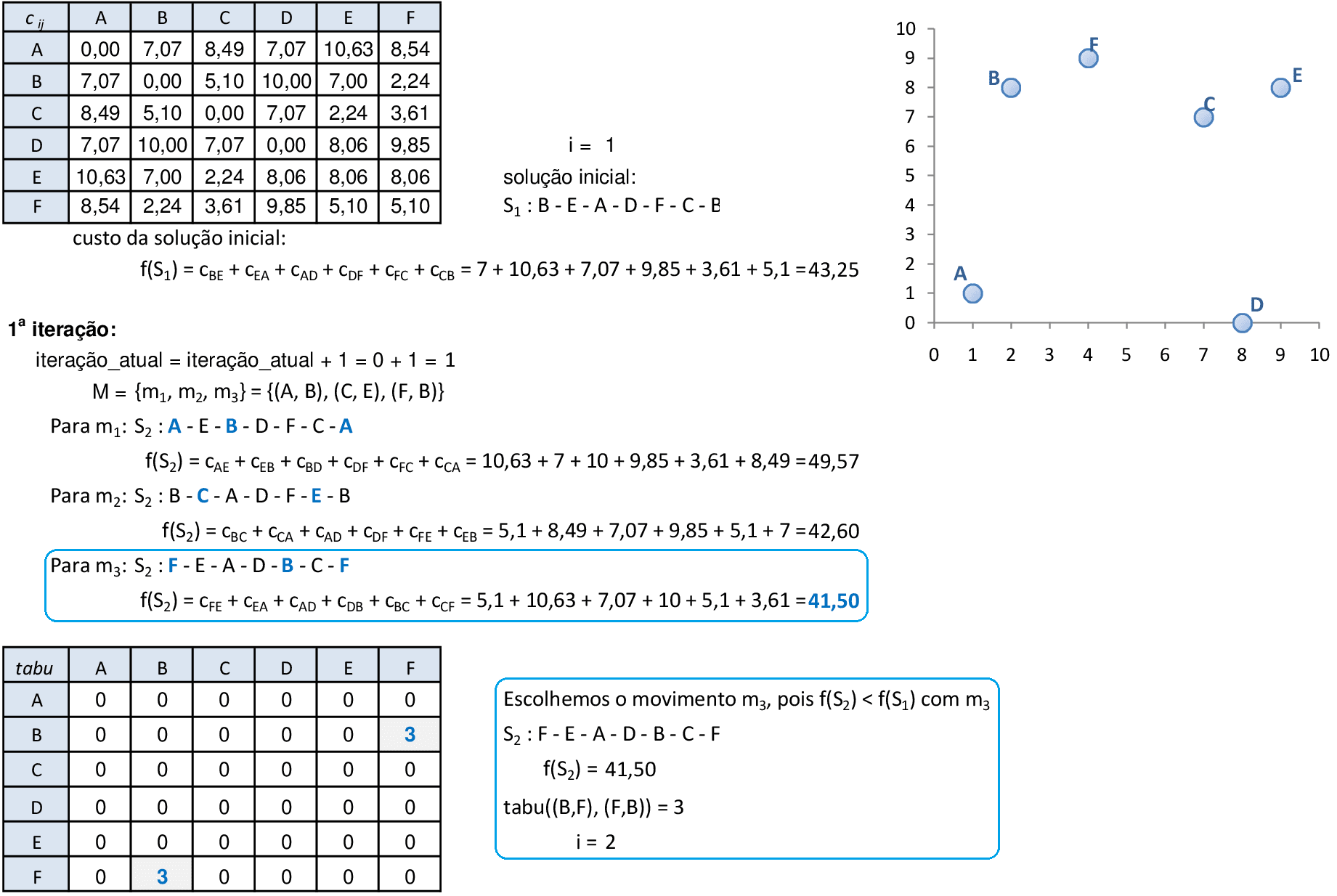
Com a solução aleatória S1, aplicamos 3 movimentos da lista M: o melhor movimento é m3, que será colocado na lista tabu por 3 iterações. -

Com a solução modificada S2, aplicamos 3 movimentos da nova lista M: o melhor movimento é m2, que será colocado na lista tabu por 3 iterações. O movimento m1 está na lista tabu, e não foi considerado nesta iteração. -

Com a solução modificada S3, aplicamos 3 movimentos da nova lista M: nenhum dos movimentos melhora a solução. O movimento m3 está na lista tabu, e não foi considerado nesta iteração. -

Com a solução S3, aplicamos 3 movimentos da nova lista M: o melhor movimento é m3, que será colocado na lista tabu por 3 iterações. O movimento m2 está na lista tabu, e não foi considerado nesta iteração. Continuamos os cálculos até alcançar o número máximo de iterações.

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Busca Tabu para encontrar uma solução do problema da Mochila. Vamos utilizar k = 3, ou seja, 3 movimentos para cada iteração.
-

Com a solução aleatória S1, aplicamos 3 movimentos da lista M: o melhor movimento é m3, que será colocado na lista tabu por 3 iterações. -

Com a solução modificada S2, aplicamos 3 movimentos da nova lista M: o melhor movimento é m3, que será colocado na lista tabu por 3 iterações. O movimento m2 está na lista tabu, e não foi considerado nesta iteração. -

Com a solução modificada S3, aplicamos 3 movimentos da nova lista M: o melhor movimento é m1, que será colocado na lista tabu por 3 iterações. O movimento m2 está na lista tabu, e não foi considerado nesta iteração. -

Com a solução S4, aplicamos 3 movimentos da nova lista M: nenhum dos movimentos melhora a solução. O movimento m2 está na lista tabu, e não foi considerado nesta iteração. Continuamos os cálculos até alcançar o número máximo de iterações.

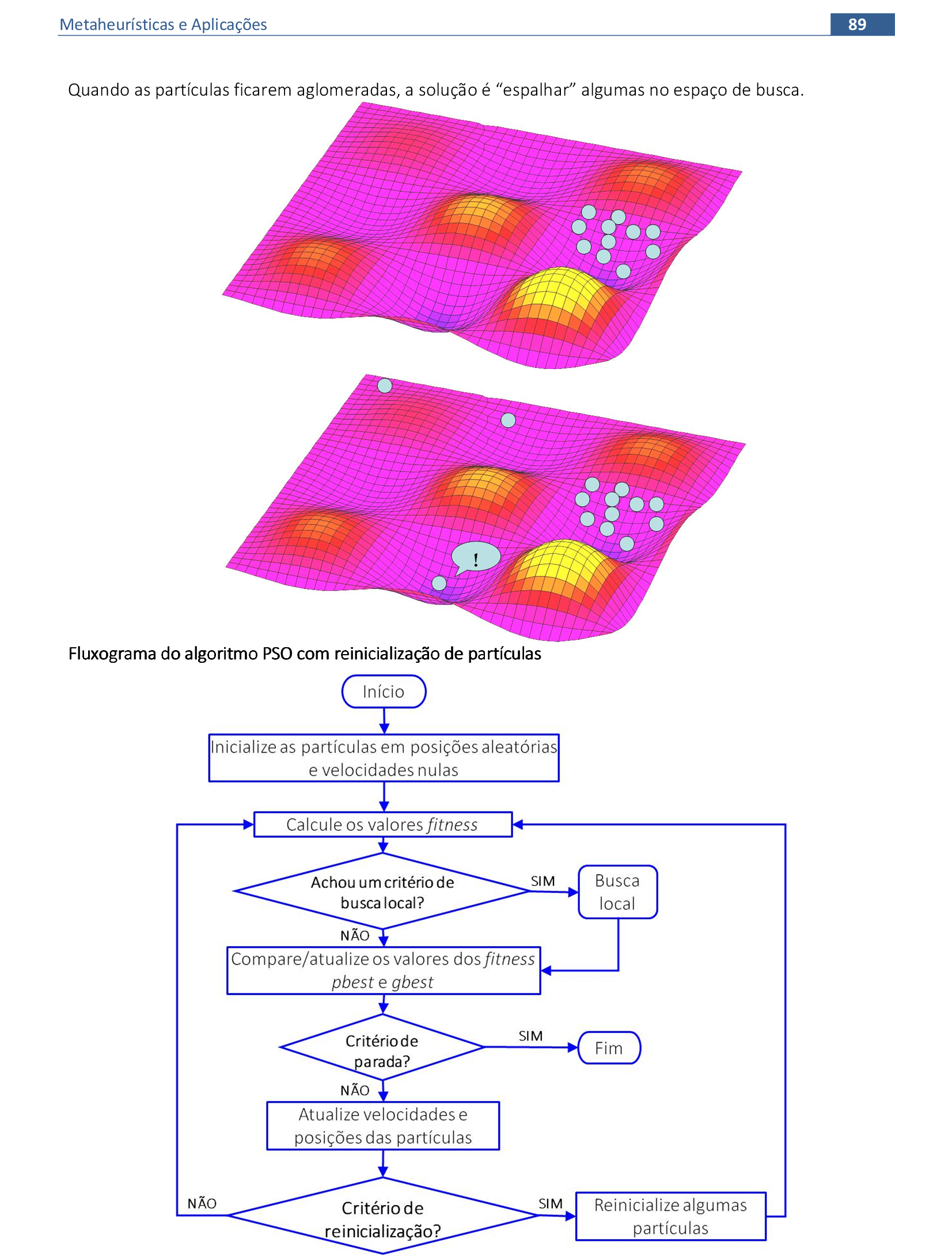
10. Nuvem de Partículas
Material das páginas 85 até 93.



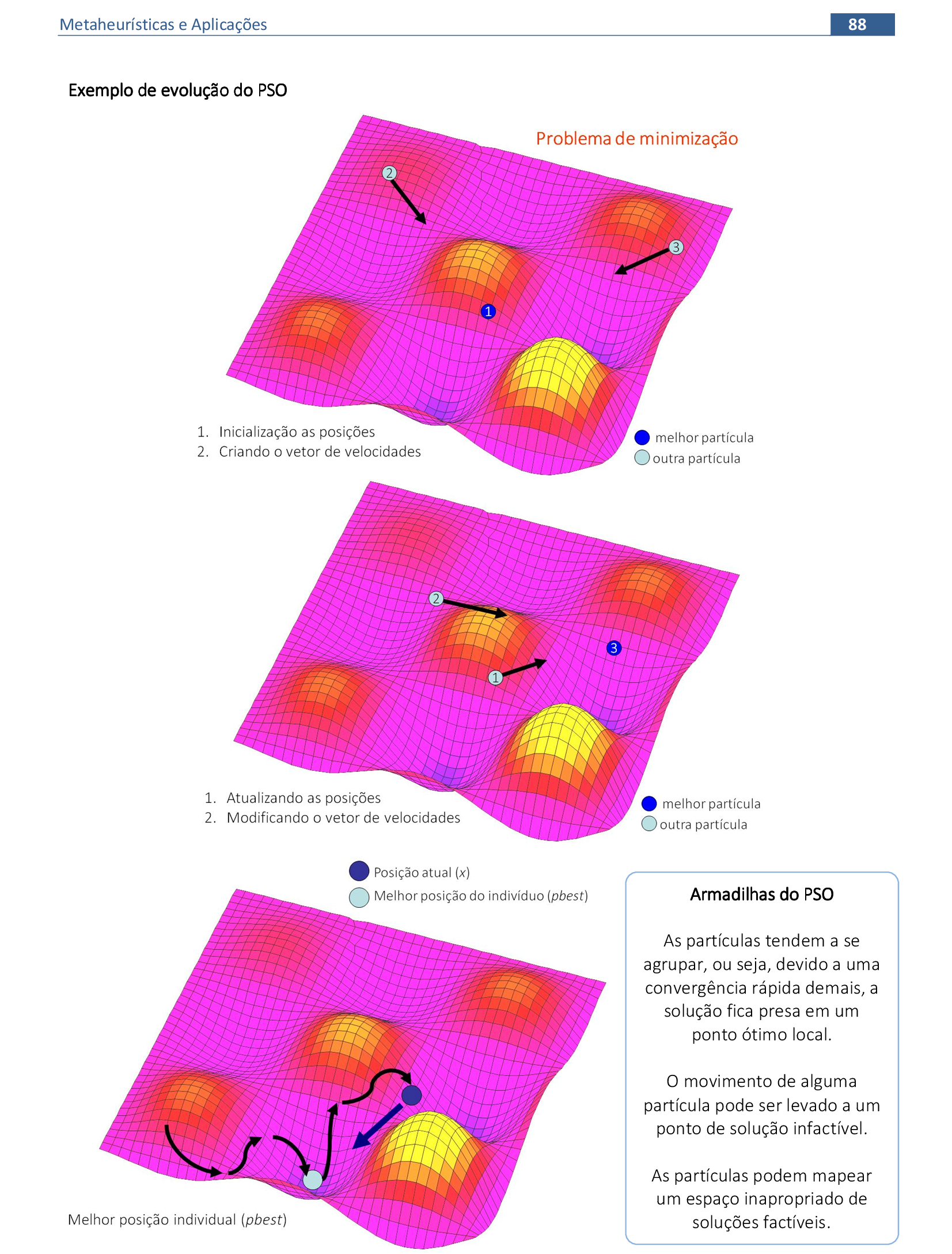
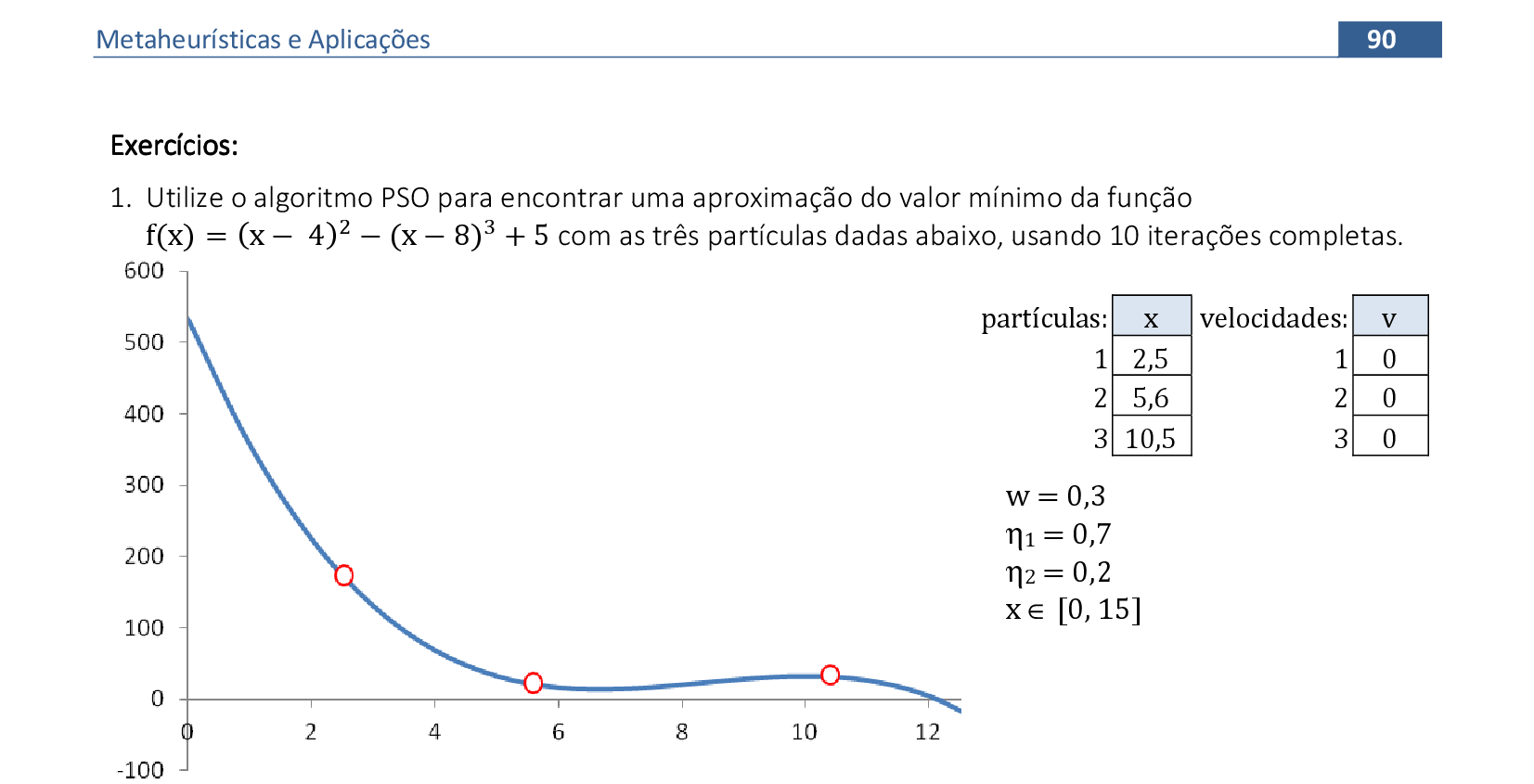
📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Nuvem de Partículas para encontrar o valor mínimo da função f(x). Vamos utilizar 3 partículas que representam soluções do problema.
-
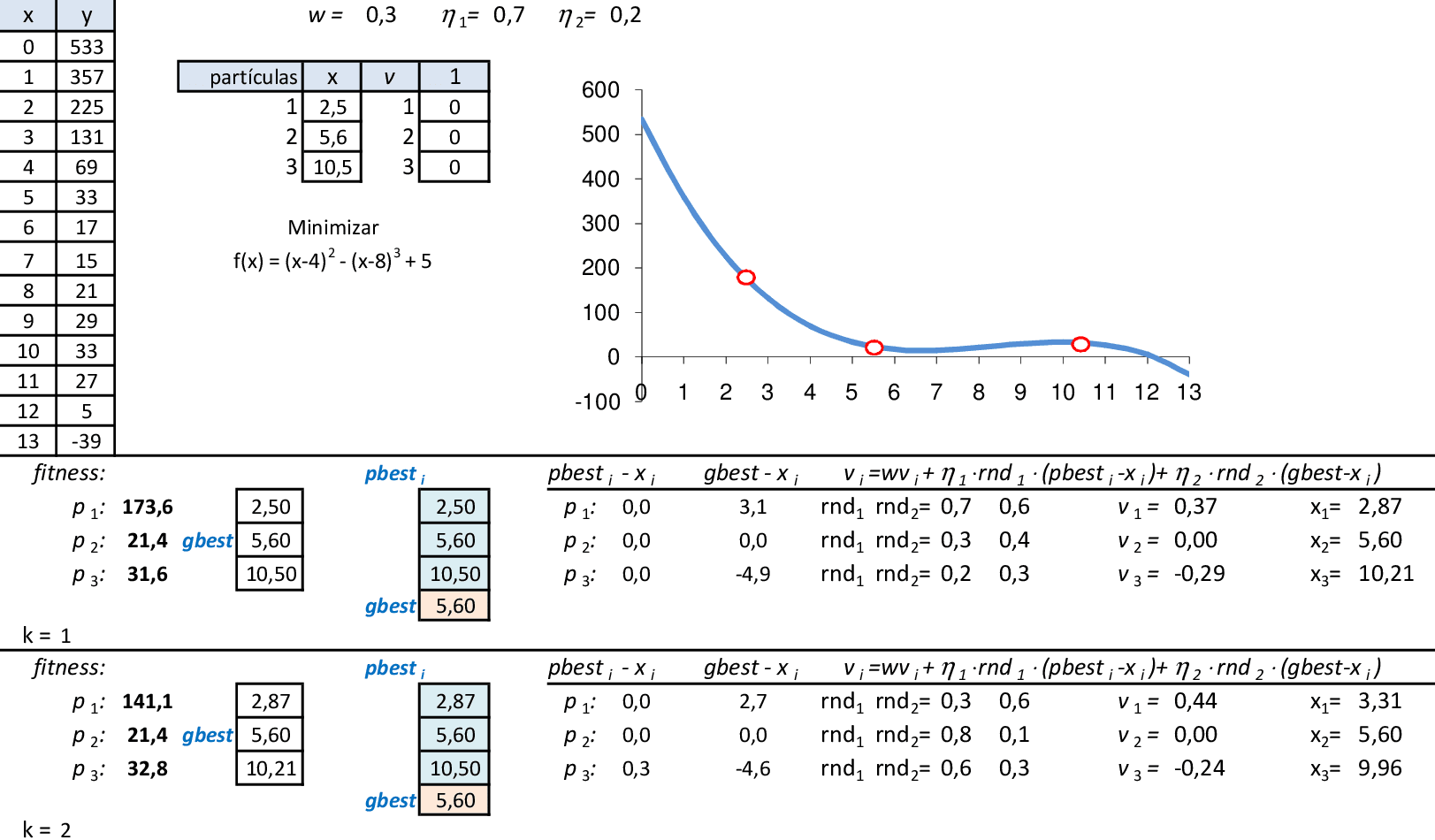
Com os parâmetros indicados, temos as 2 primeiras iterações da técnica. A melhor partícula é p2 nestas iterações, com f(x) = 21,4. As melhores posições de cada partícula pbesti são suas novas posições. -
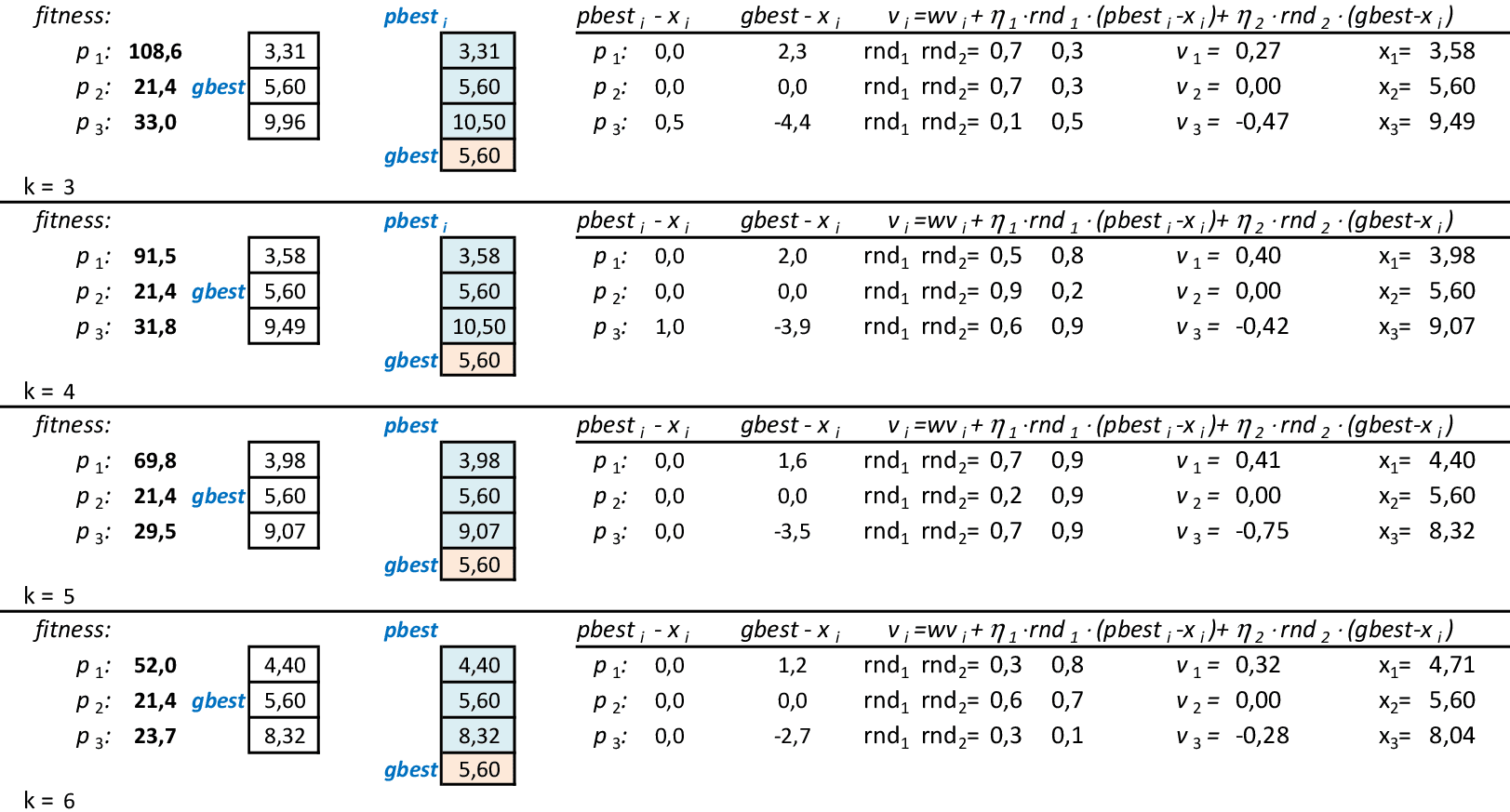
Nas 4 iterações seguintes, temos que a melhor partícula continua sendo p2, com f(x) = 21,4. -

Na 7ª iteração, a melhor partícula é p3, com f(x) = 21,3. Porém, com as atualizações de velocidades, a partícula p2, volta a ser a melhor com f(x) = 15,6 na 8ª iteração. -

Na 11ª iteração, a melhor partícula é p3, com f(x) = 15,4. Porém, com as atualizações de velocidades, a partícula p2, volta a ser a melhor com f(x) = 14,6 na 14ª iteração. -
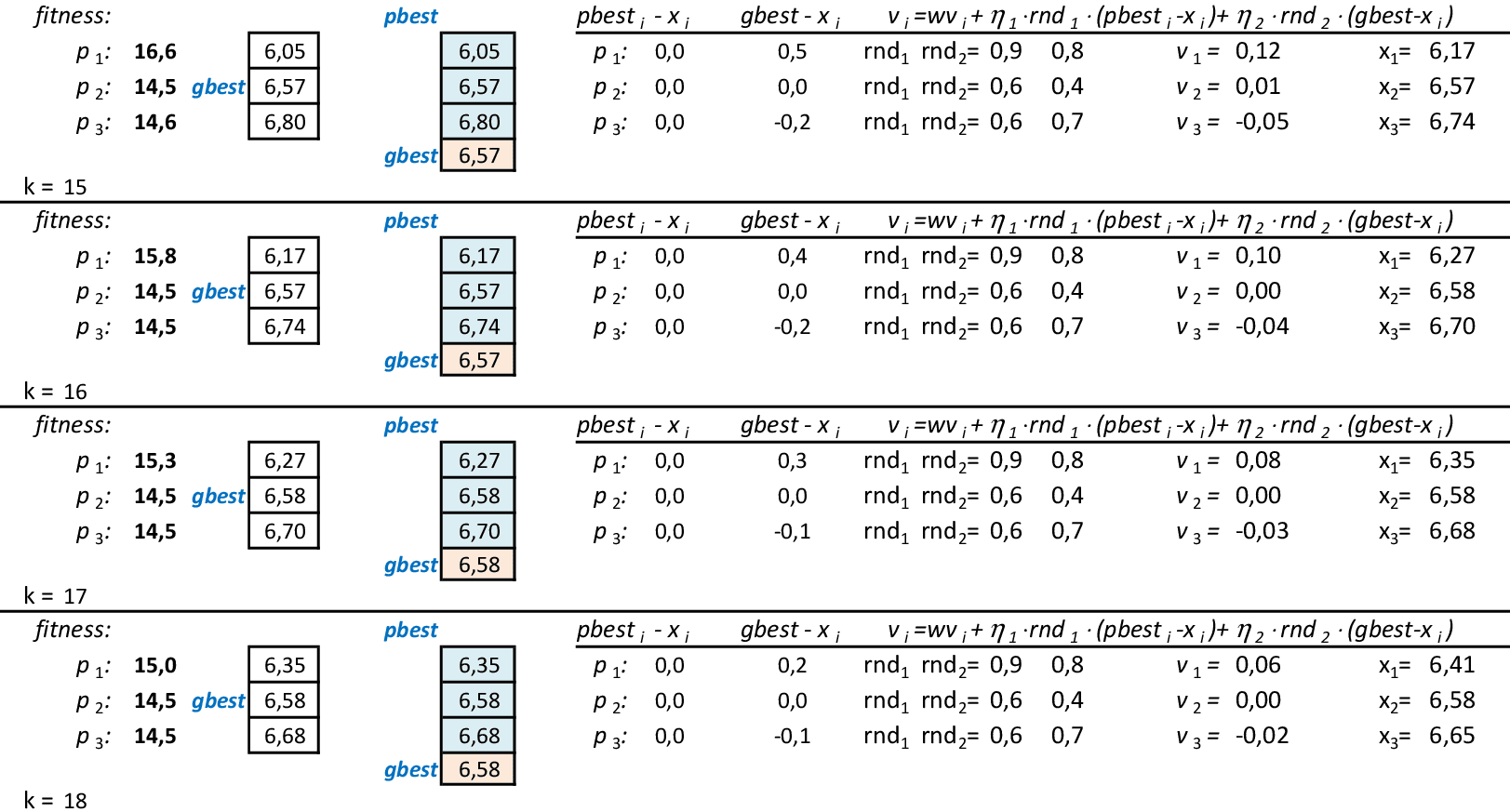
Nas 4 iterações seguintes, temos que a melhor partícula é p2, com f(x) = 14,5. -
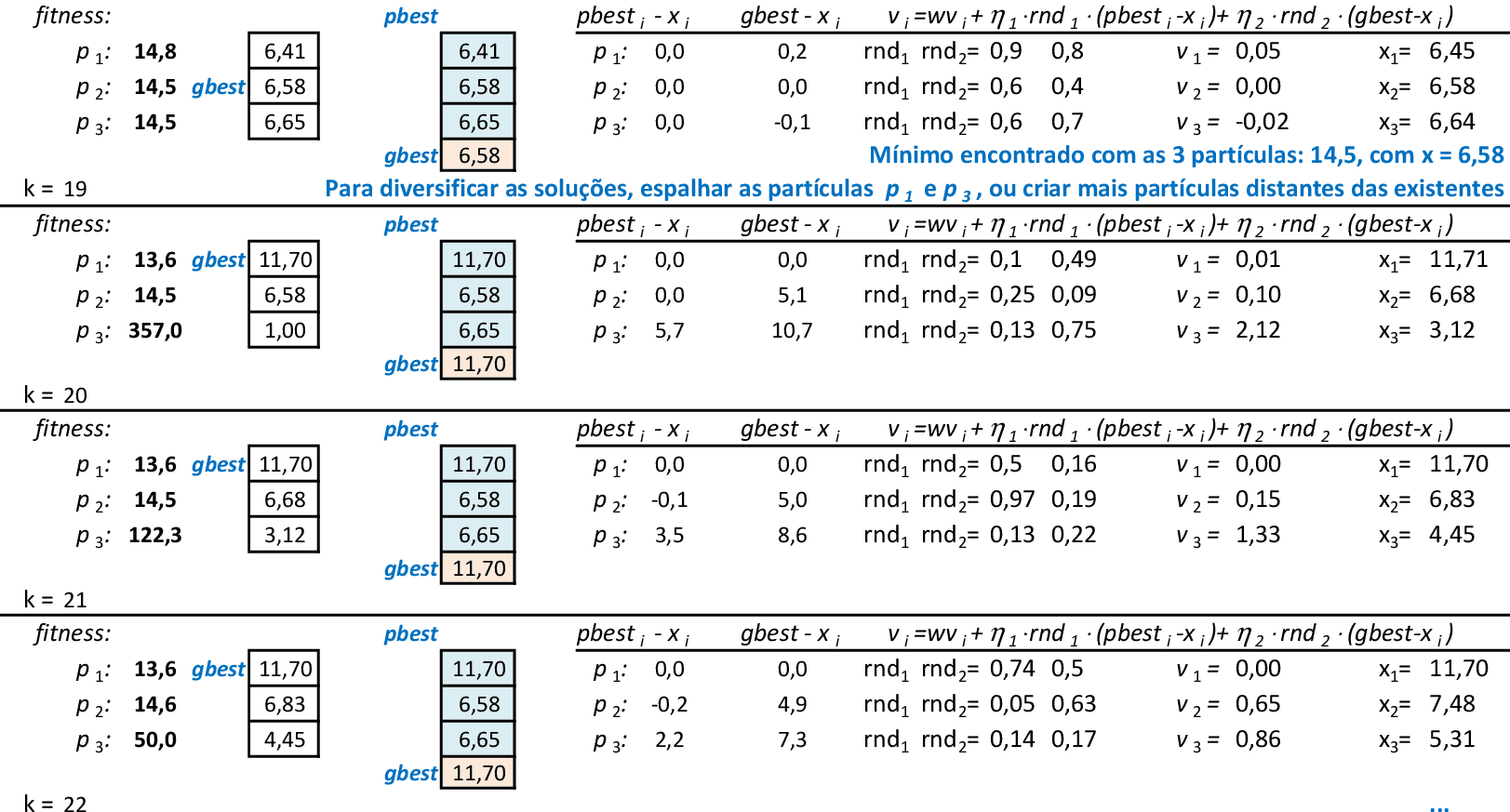
Com as partículas agrupadas, temos uma solução ótima local f(x) = 14,5. Espalhando-se as partículas e mantendo-se a melhor delas (p2), podemos explorar o espaço de busca da técnica. O critério de parada mais usado em PSO é o número máximo de iterações alcançado.
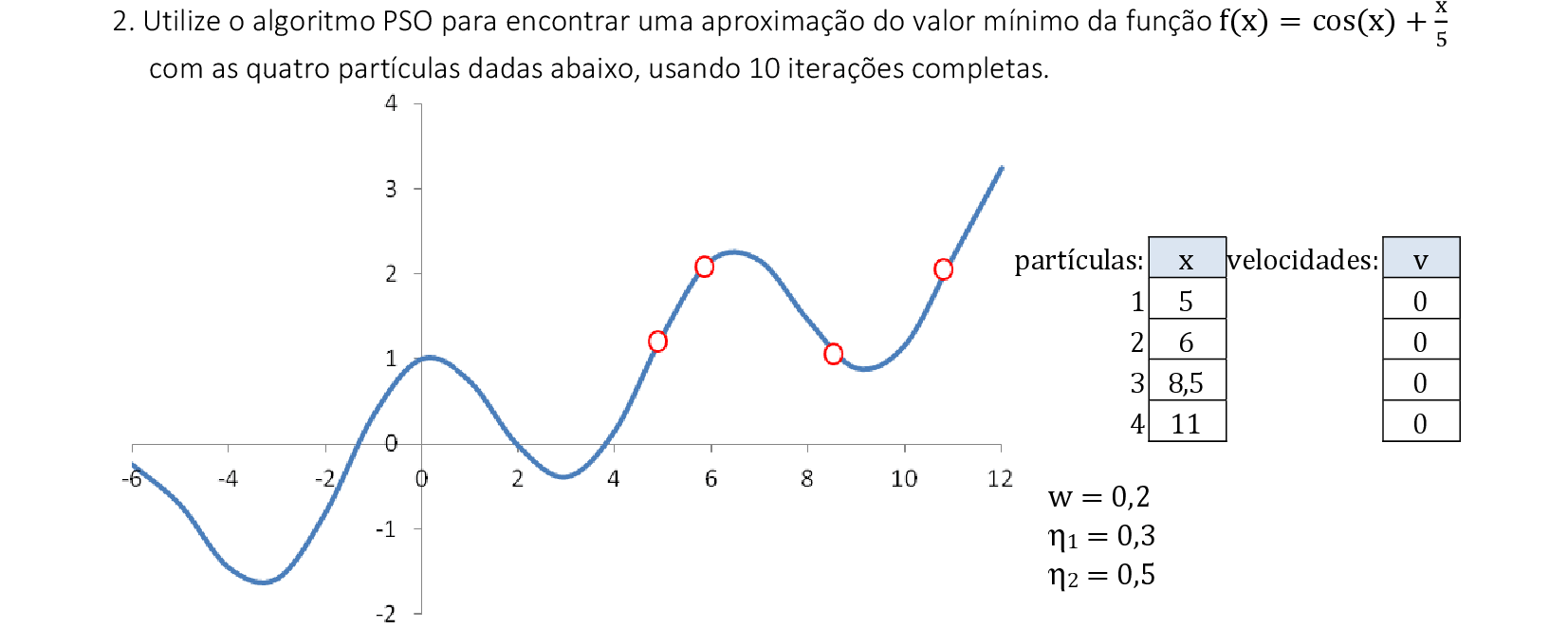

📃 Resolução
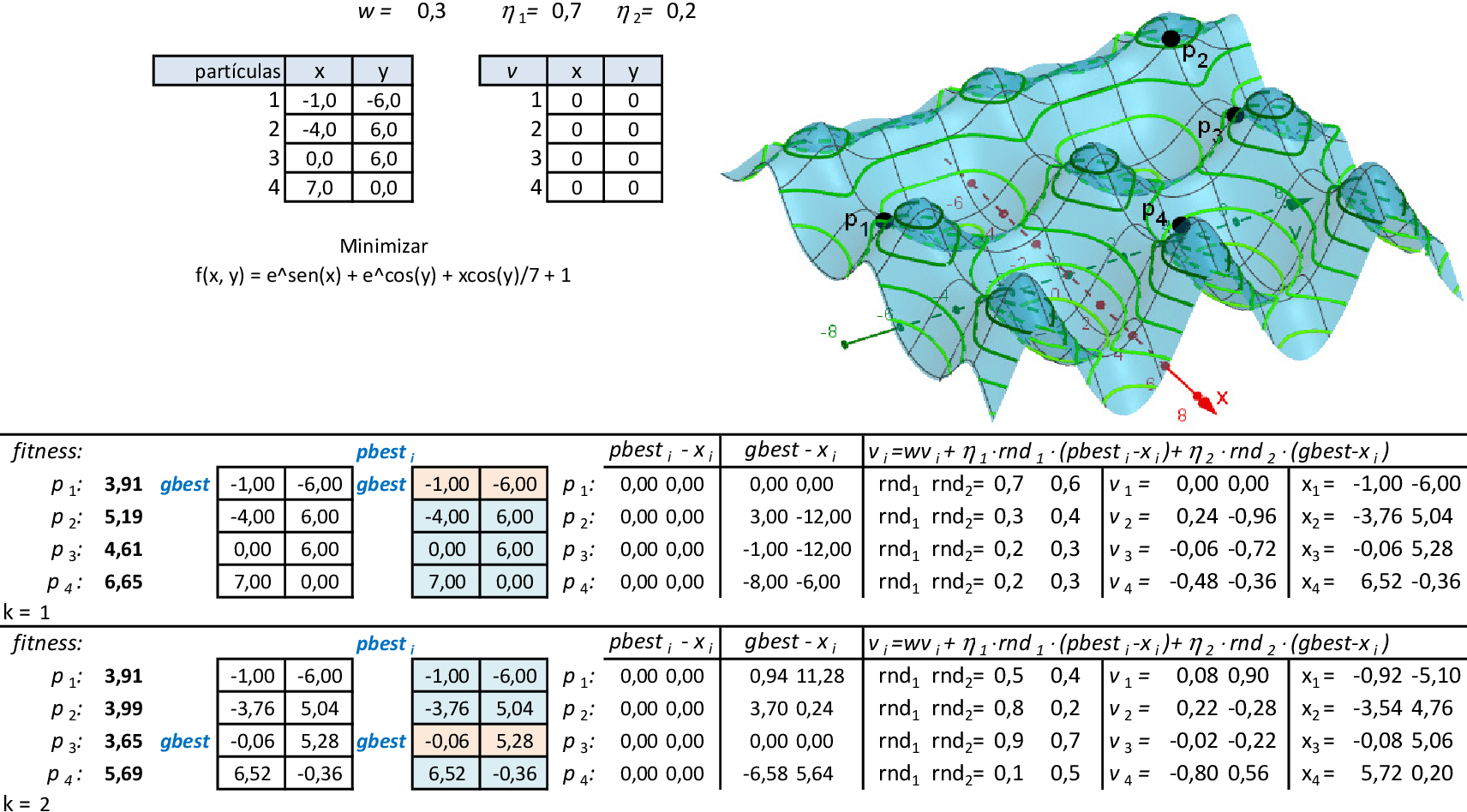
Vamos acompanhar os cálculos deste exercício da aplicação da Nuvem de Partículas para encontrar o valor máximo da função f(x,y). Vamos utilizar 4 partículas que representam soluções do problema.
-

Com os parâmetros indicados, temos as 2 primeiras iterações da técnica. A melhor partícula é p3 nestas iterações, com f(x,y) = 4,72. As melhores posições de cada partícula pbesti são suas novas posições na primeira iteração. -

Podemos observar as posições das partículas nas 3 primeiras iterações por meio das curvas de nível da função f. Na quarta iteração, a partícula p1, torna-se a melhor, com f(x,y) = 5,48. -
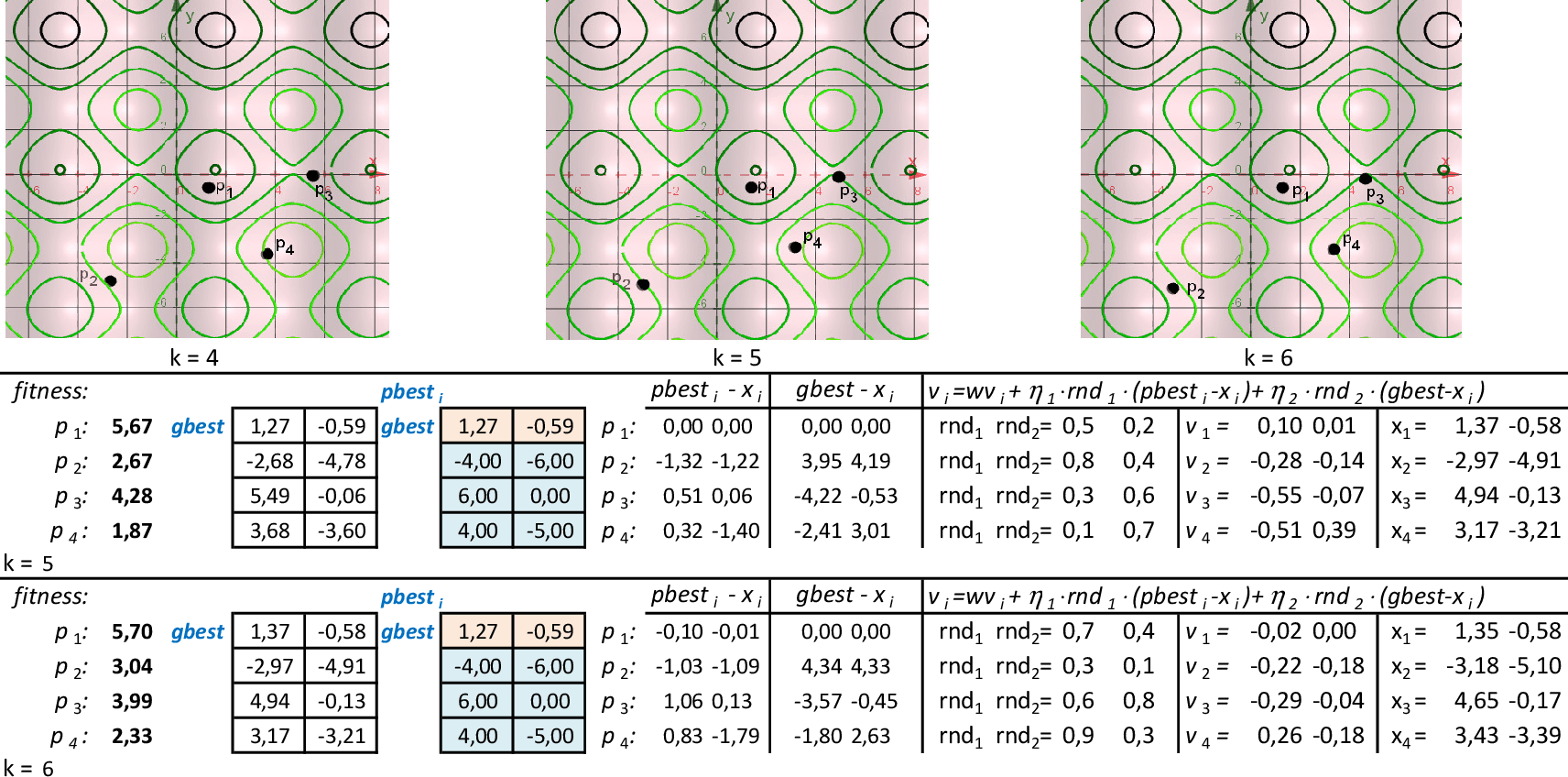
As partículas começam a reagir, combinando as novas posições com as respectivas melhores posições pbesti e a melhor posição da partícula do grupo gbest. -
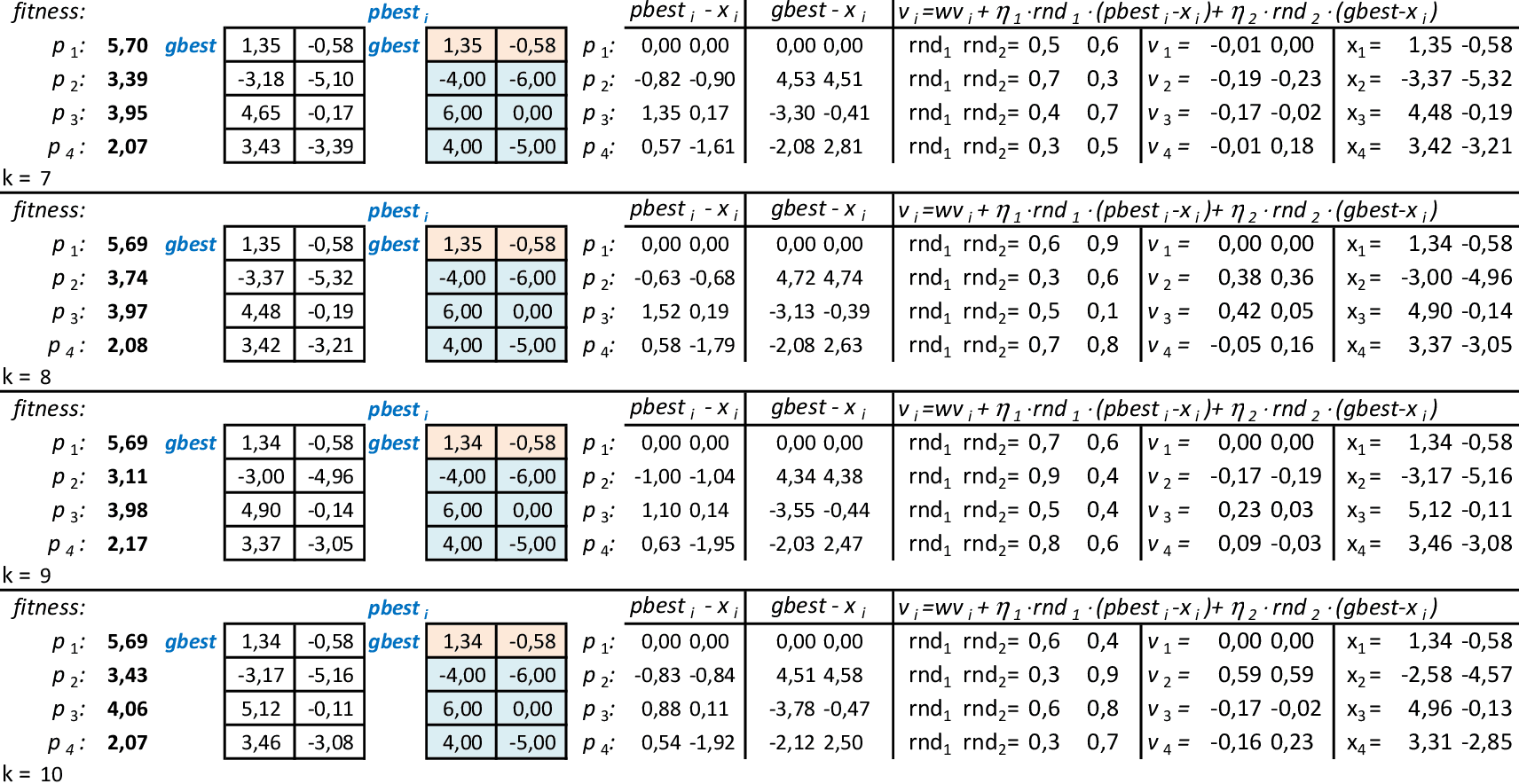
Nas 4 iterações seguintes, temos que melhor partícula continua sendo p1, com f(x,y) = 5,71. -
Nas 4 iterações seguintes, temos que melhor partícula continua sendo p1, com f(x,y) = 5,71. -
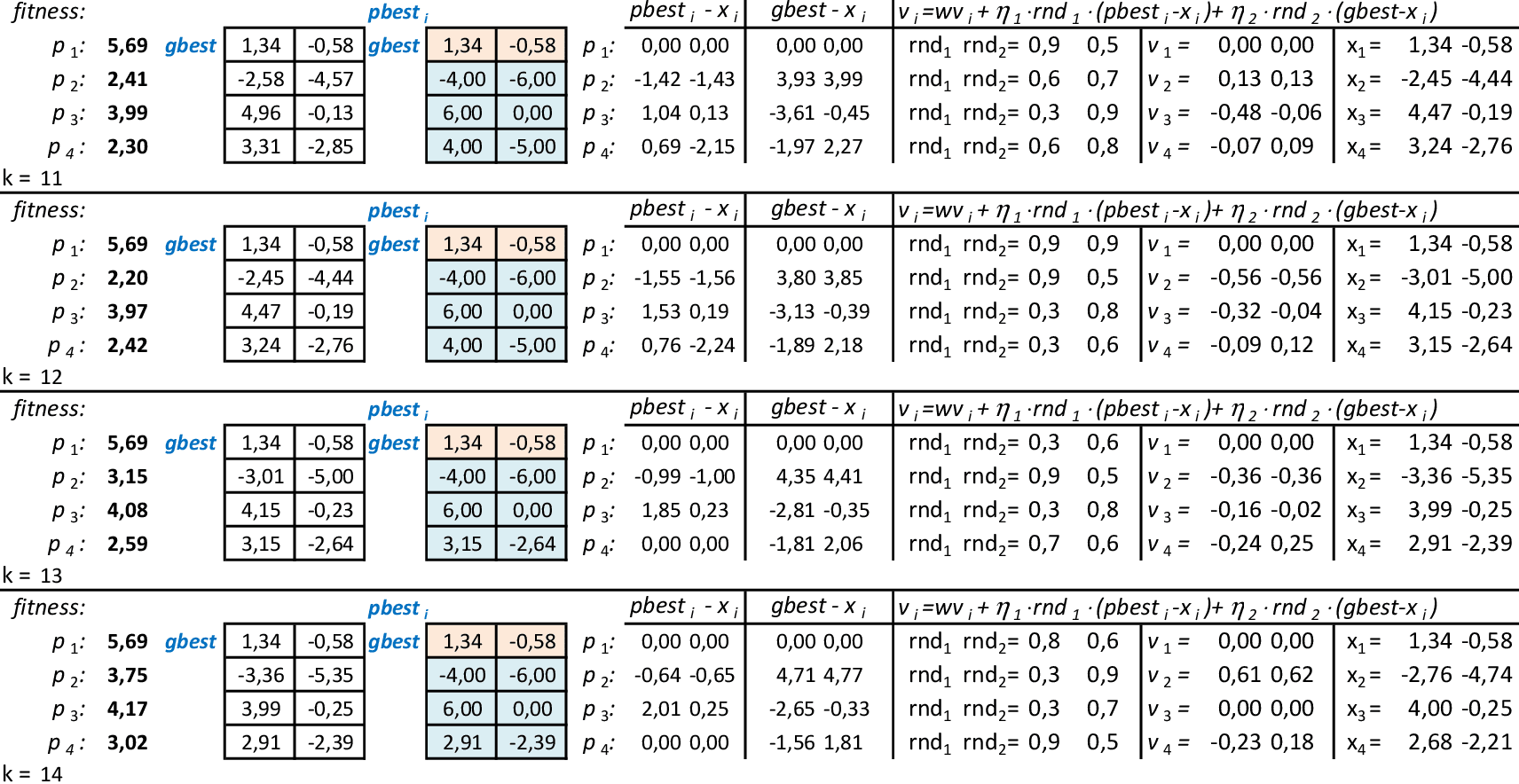
Nas 4 iterações seguintes, temos que melhor partícula continua sendo p1, com f(x,y) = 5,71. -

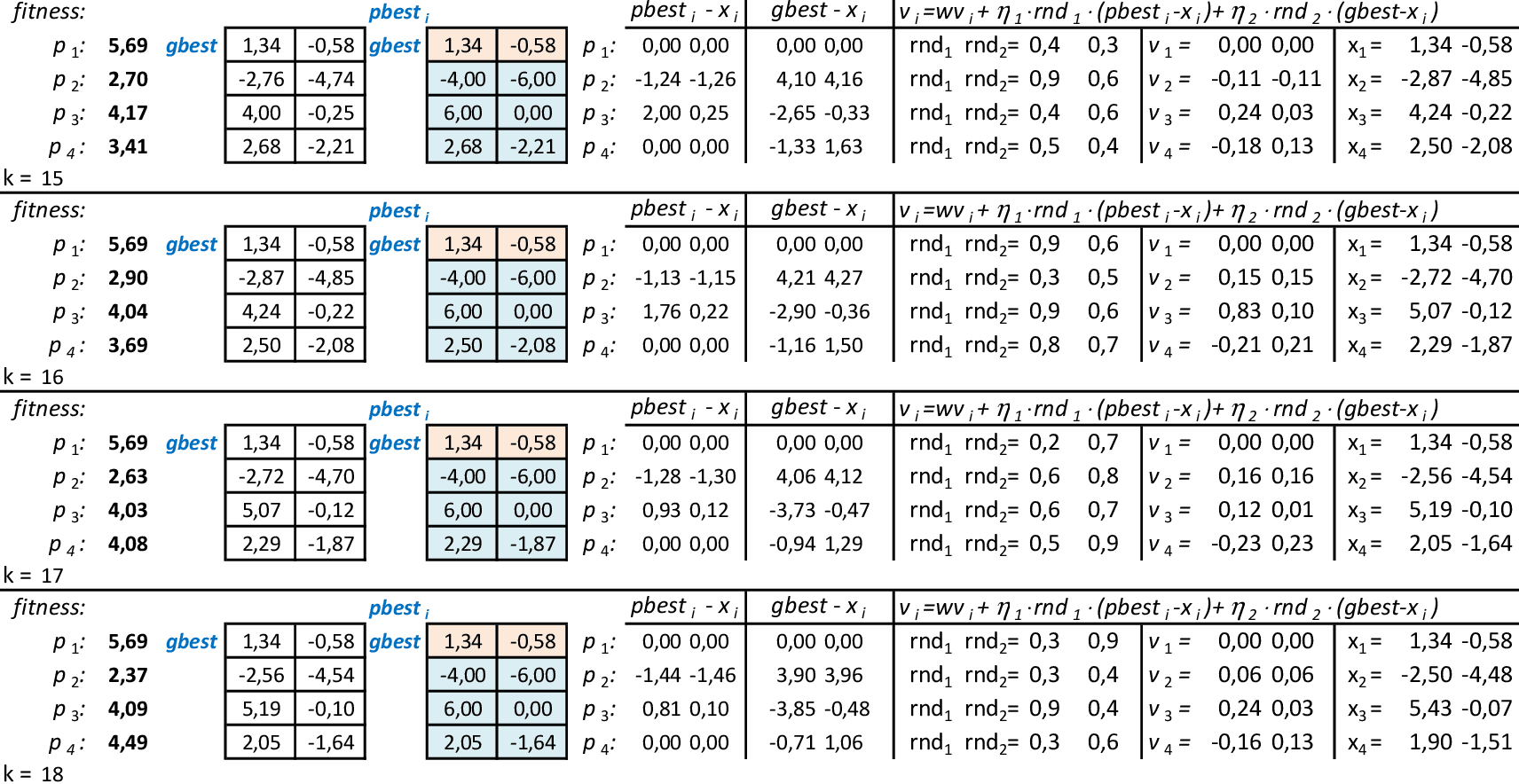
Com as partículas mostrando a tendência de agrupamento, encontramos uma solução ótima local f(x,y) = 5,71. Espalhando-se as partículas e mantendo-se a melhor delas (p1), podemos explorar o espaço de busca da técnica. O critério de parada mais usado em PSO é o número máximo de iterações alcançado. -
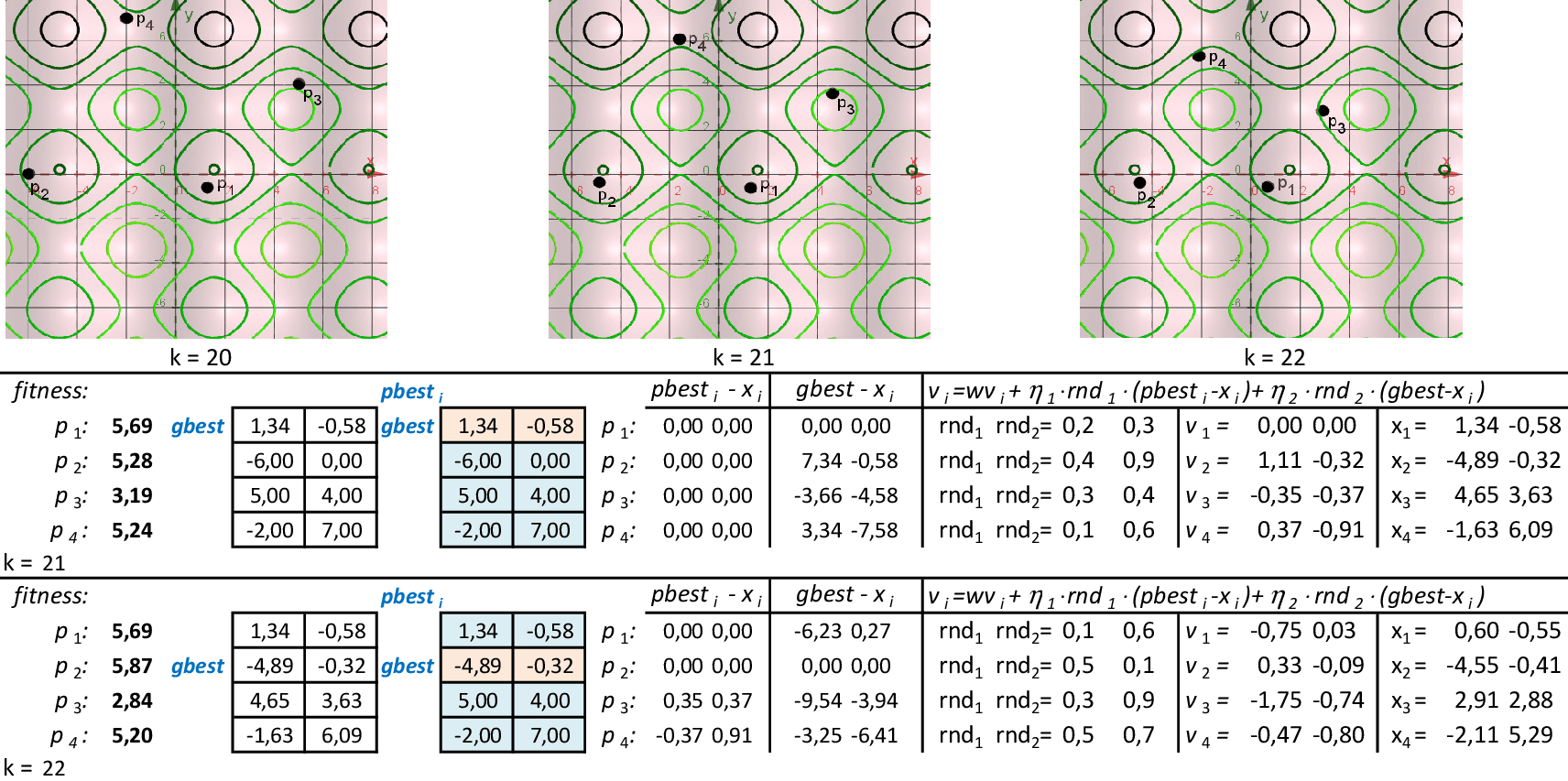
Na 22ª iteração, temos que melhor partícula é p2, com f(x,y) = 5,87. -
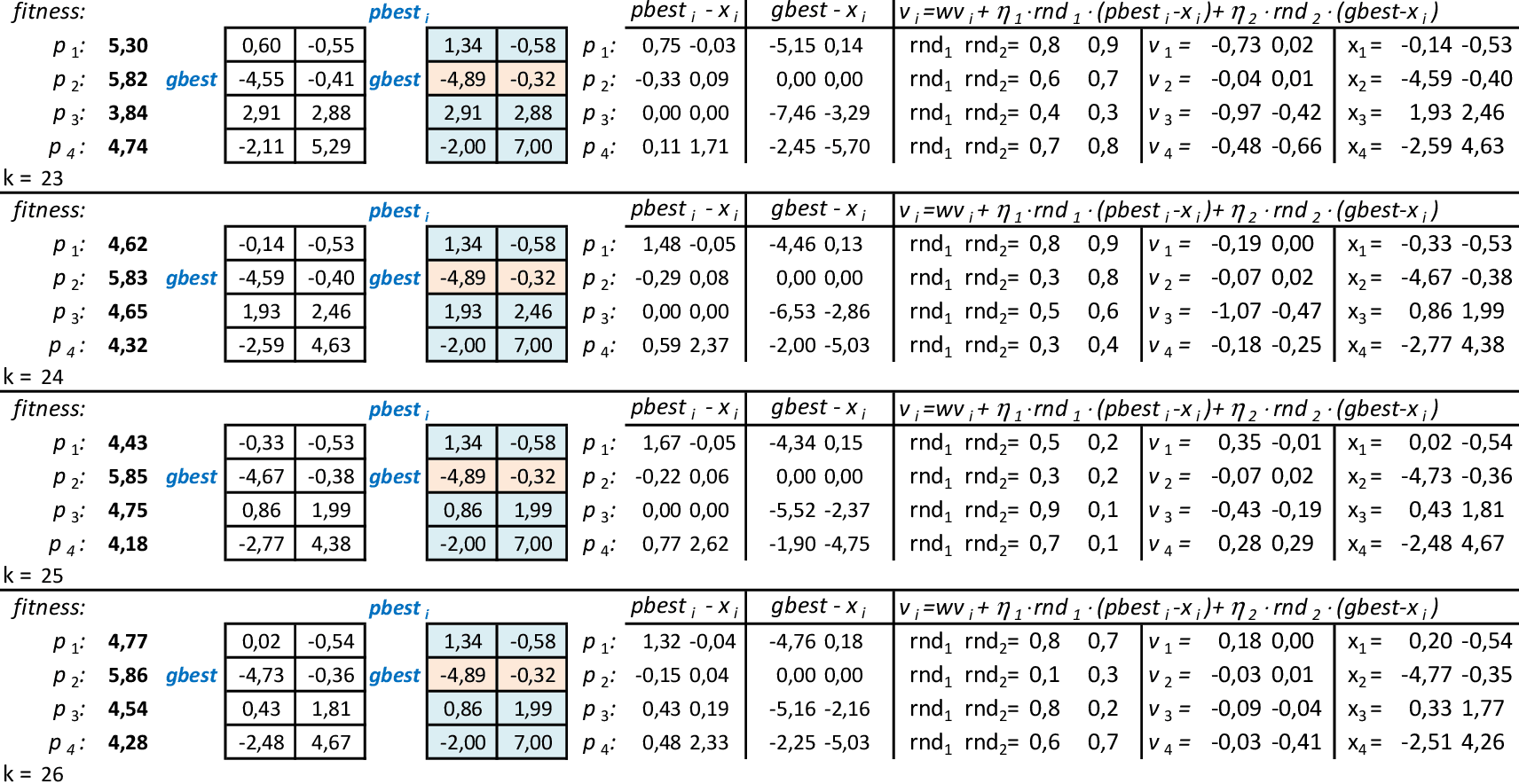
Nas 4 iterações seguintes, temos que melhor partícula continua sendo p2, com f(x,y) = 5,87. -
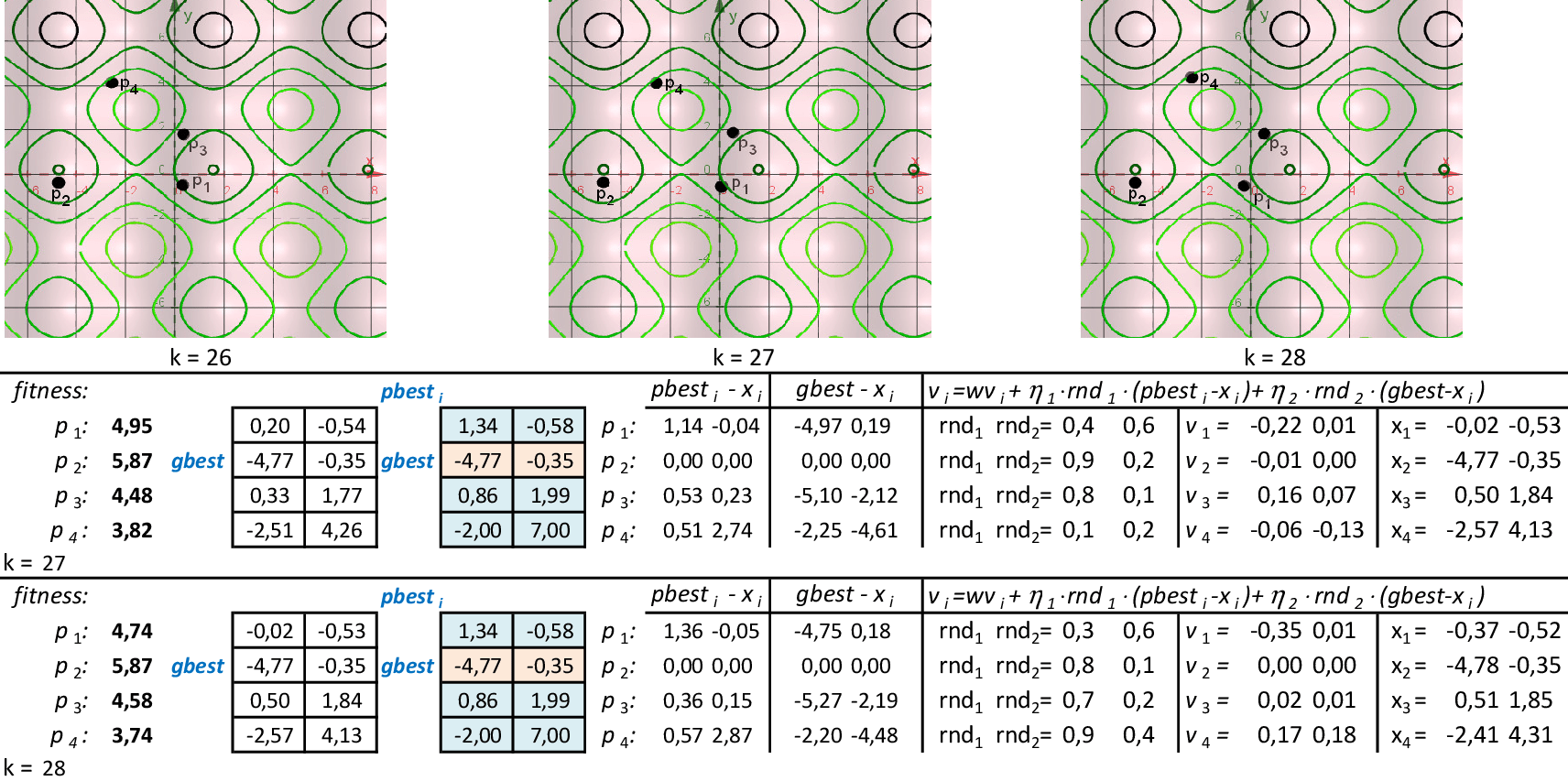
Na 28ª iteração temos a solução ótima local f(x,y) = 5,87. O método continua até atingir um número máximo de iterações.

📃 Resolução
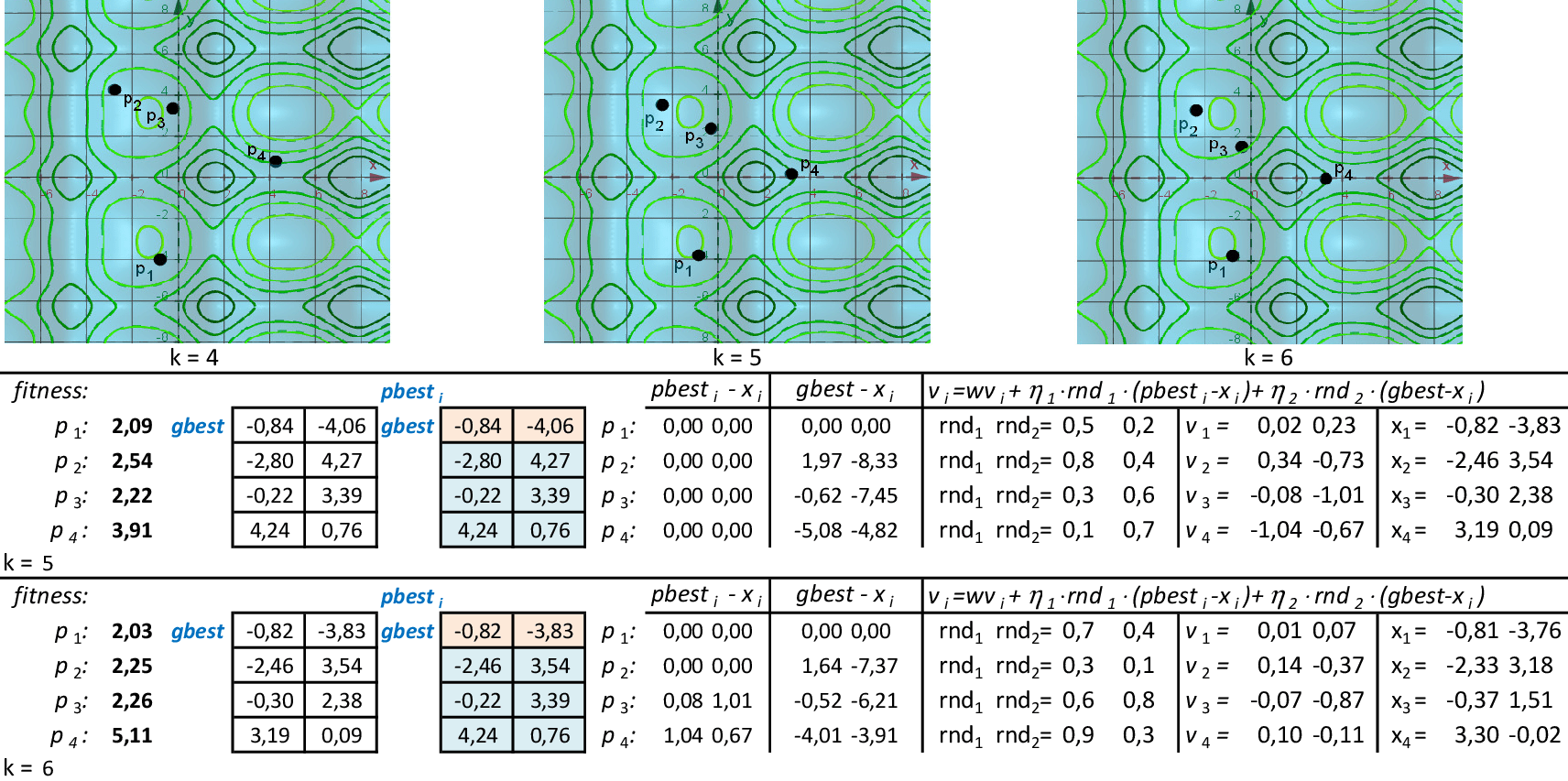
Vamos acompanhar os cálculos deste exercício da aplicação da Nuvem de Partículas para encontrar o valor mínimo da função f(x,y). Vamos utilizar 4 partículas que representam soluções do problema.
-
Com os parâmetros indicados, temos as 2 primeiras iterações da técnica. As melhores partículas são p1 na 1ª iteração e p3 na 2ª iteração. As melhores posições de cada partícula pbesti são suas novas posições na primeira iteração. -

Podemos observar as posições das partículas nas 3 primeiras iterações por meio das curvas de nível da função f. Na quarta iteração, a partícula p3, torna-se a melhor, com f(x,y) = 2,30. -
As partículas começam a reagir, combinando as novas posições com as respectivas melhores posições pbesti e a melhor posição da partícula do grupo gbest. -
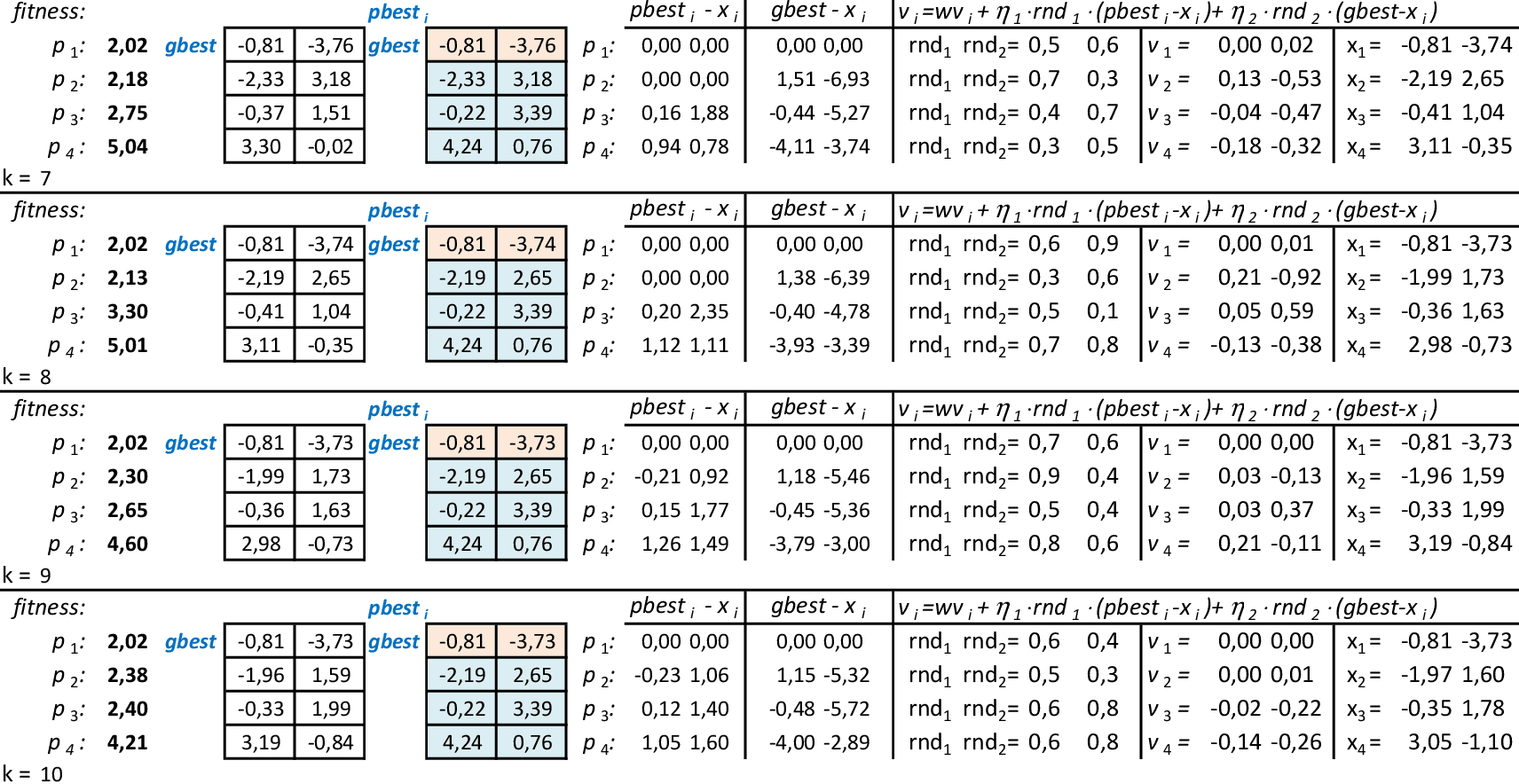
Nas 4 iterações seguintes, temos que a melhor partícula é p1 com f(x,y) = 2,02. -

Nas 4 iterações seguintes, temos que a melhor partícula é p1 com f(x,y) = 2,02. -
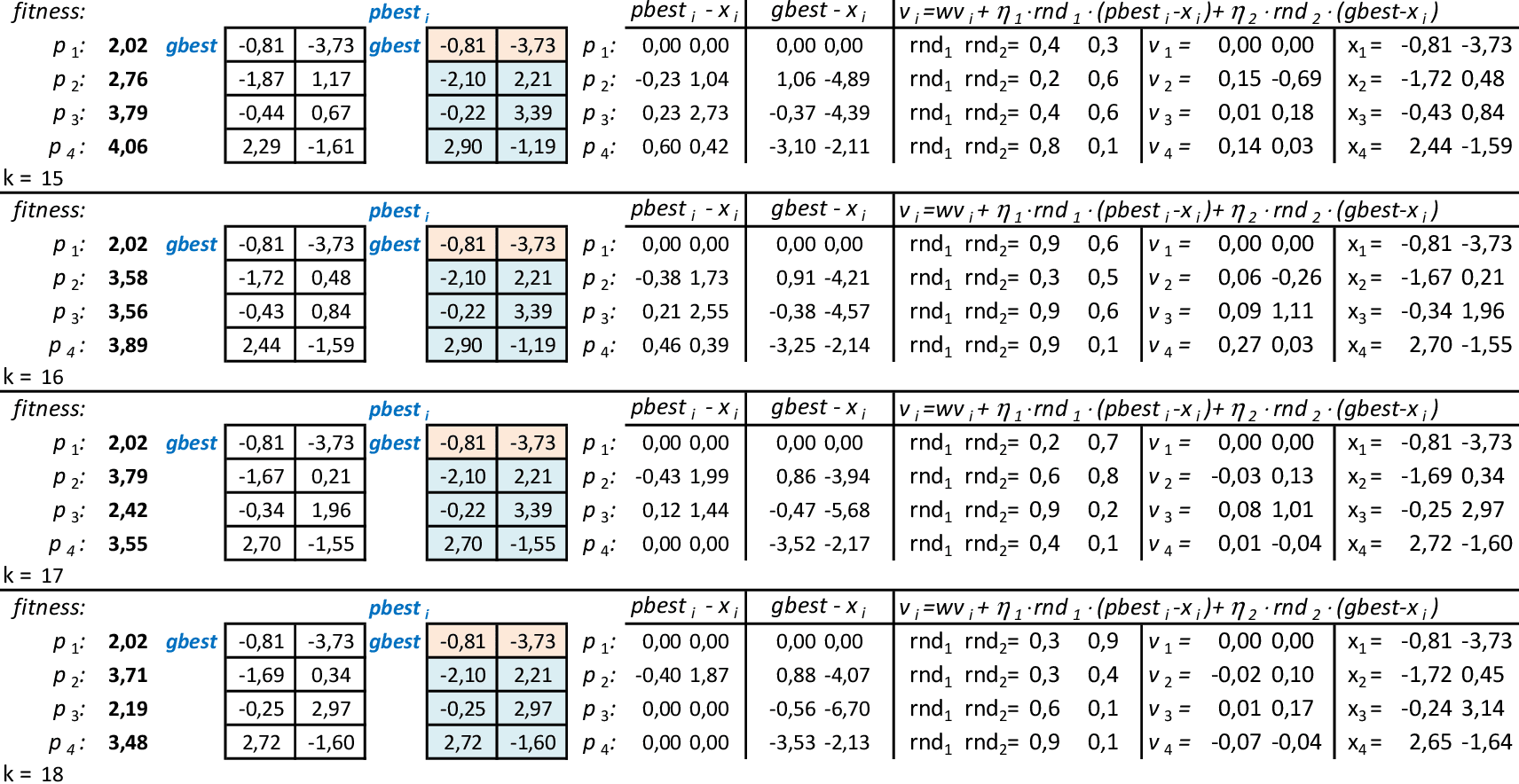
Nas 4 iterações seguintes, temos que a melhor partícula é p1 com f(x,y) = 2,02. -
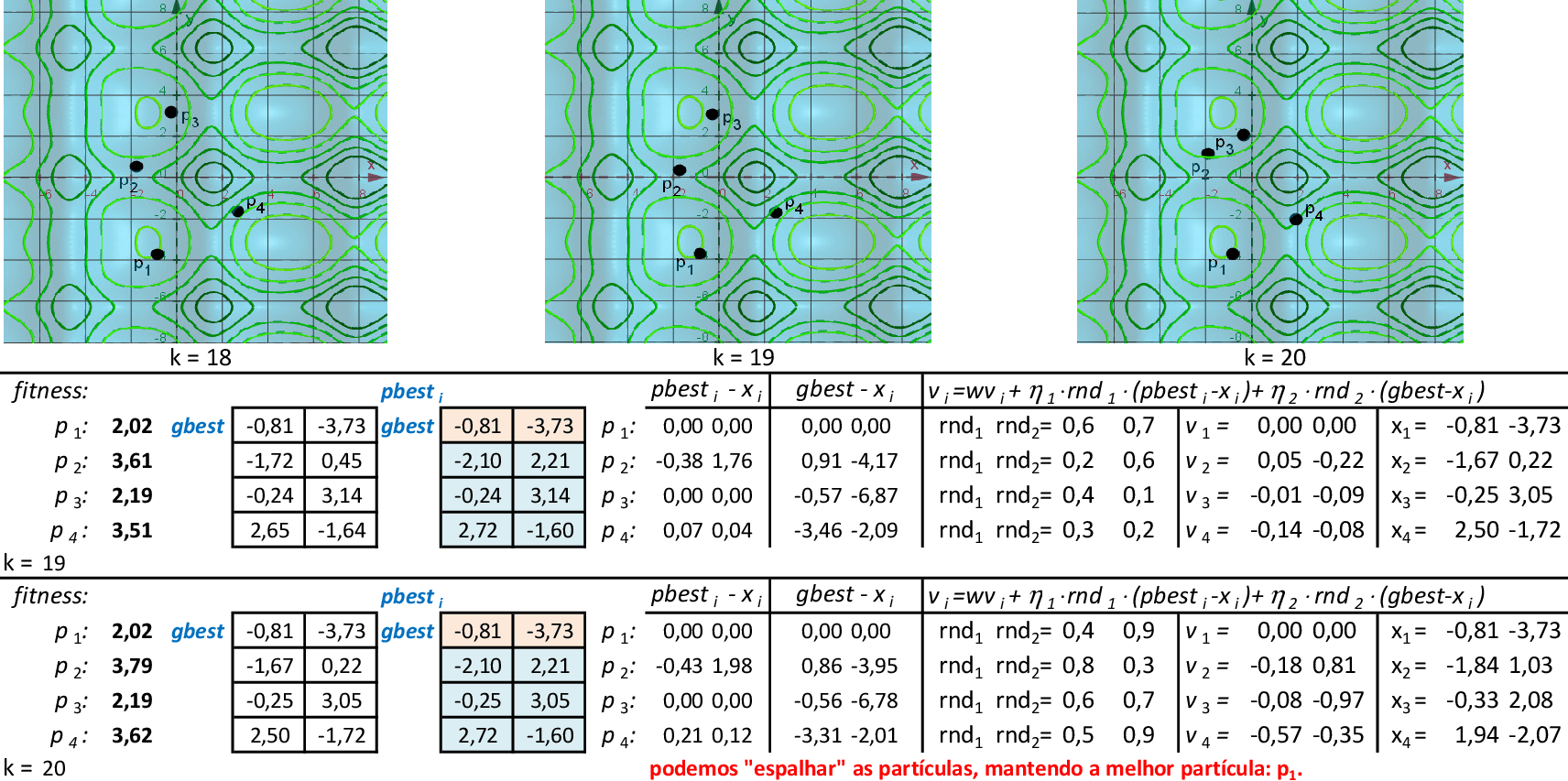
Com as partículas mostrando tendência de agrupamento, encontramos uma solução ótima local f(x,y) = 2,02. Espalhando-se as partículas e mantendo-se a melhor delas (p1), podemos explorar o espaço de busca da técnica. O critério de parada mais usado em PSO é o número máximo de iterações alcançado. -

Na 22ª iteração, temos que melhor partícula é p3, com f(x,y) = 1,21. -

Nas 4 iterações seguintes, temos que a melhor partícula é p3, com f(x,y) = 1,14. -
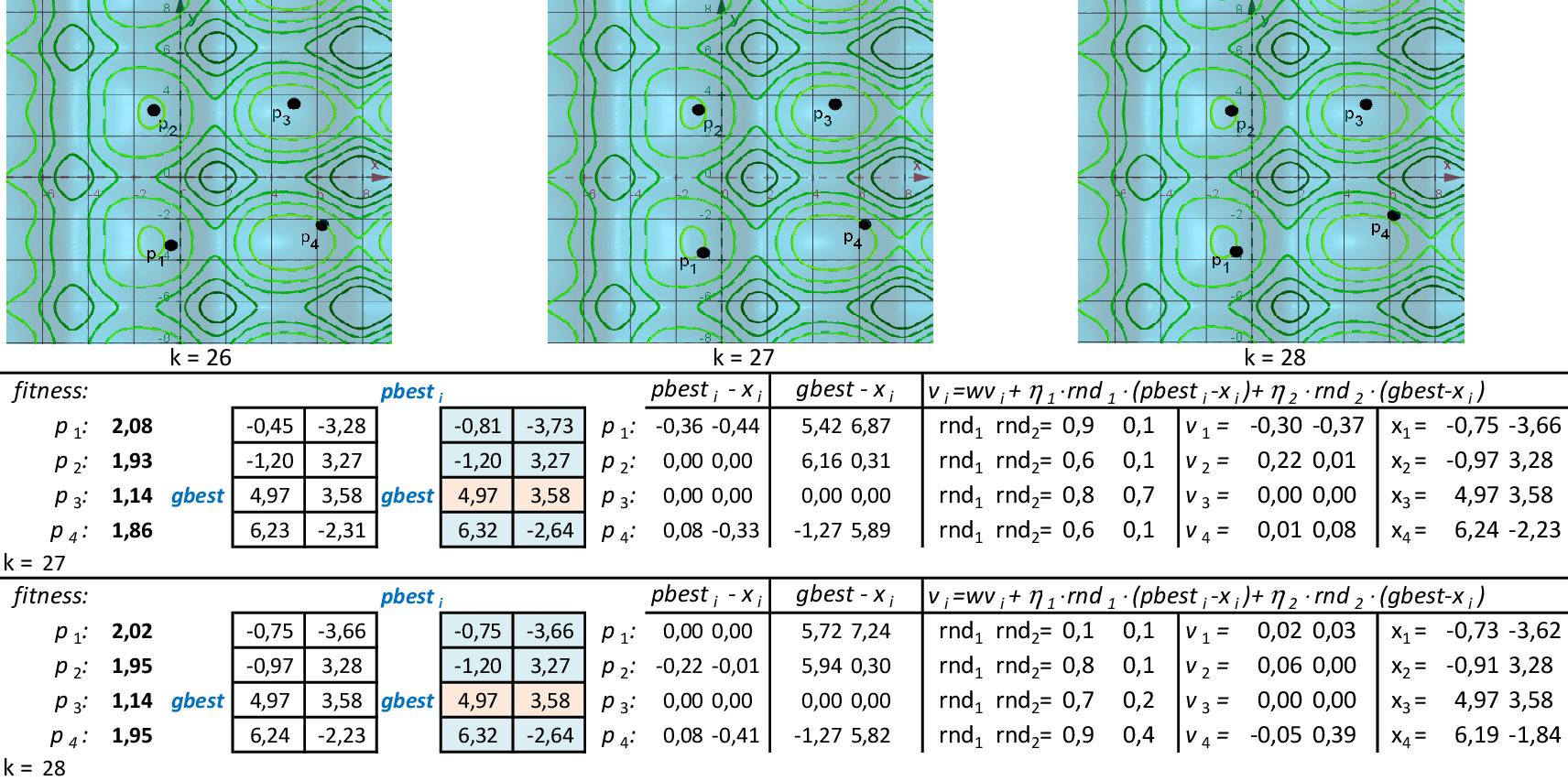
Na 28ª iteração temos a solução ótima local f(x,y) = 1,14. O método continua até atingir um número máximo de iterações.


📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Nuvem de Partículas para encontrar rotas do Problema do Caixeiro Viajante. Vamos utilizar 3 partículas que representam soluções do problema.
-

As velocidades são aplicadas com as trocas de posições dos vértices, tentando "imitar" as rotas pbesti e gbest. -
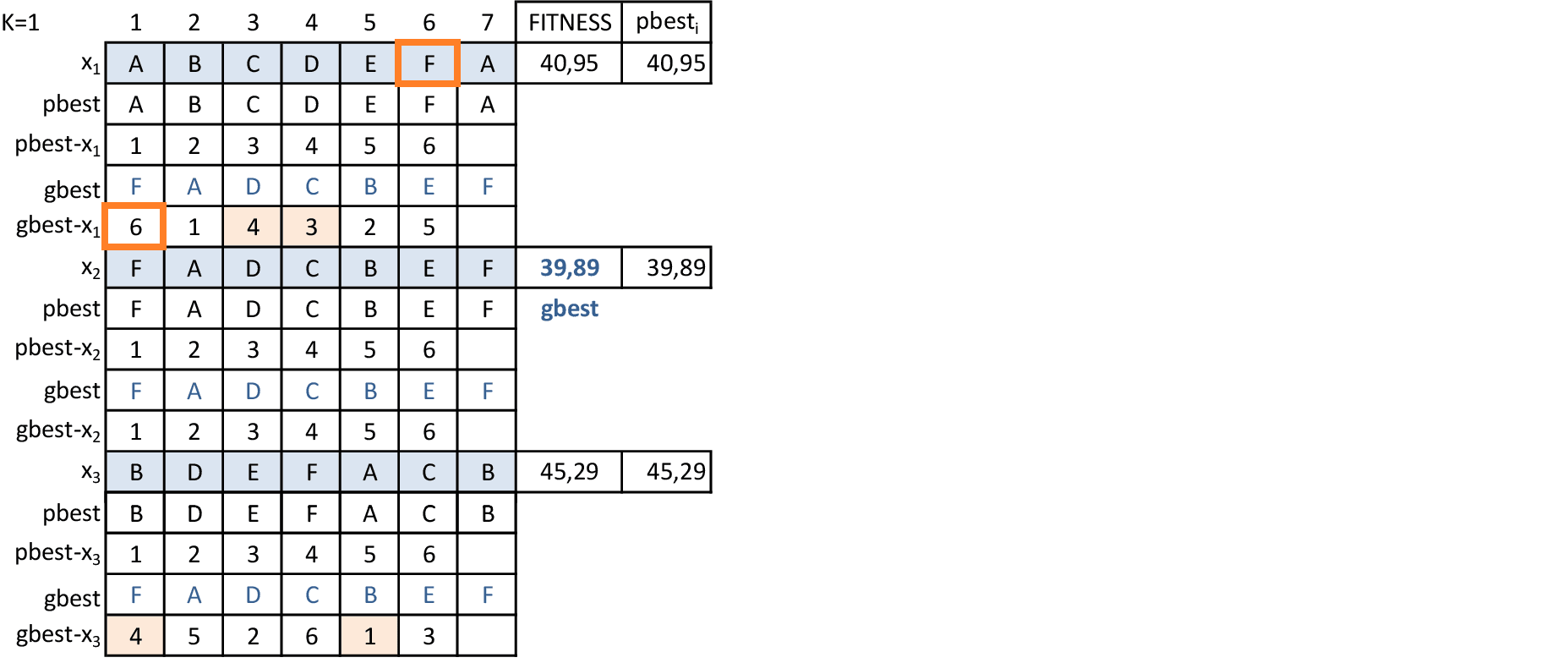
Para fazermos as trocas do PCV com a técnica PSO, podemos utilizar índices para gbest - xi. Na partícula 1, a cidade F está na posição 6; porém, na partícula gbest a cidade F está na posição 1. Logo, a posição 1 de gbest - x1 tem índice 6. -

A cidade B está na posição 2 da partícula 1; porém, na partícula gbest a cidade B está na posição 5. Logo, a posição 5 de gbest - x1 tem índice 2. Quando a partícula é a gbest, temos que os índices de gbest - xi estão na ordem 1, 2, 3, 4, 5, 6. -

Com os parâmetros indicados, temos a 1ª iteração da técnica. A melhor partícula é p2, com solução 39,89. Calculamos as velocidades por meio de trocas de posições dos vértices, deixando as rotas parecidas com a gbest. -

Na 2ª iteração, a melhor partícula é p3, com solução 36,05. Calculamos as velocidades por meio de trocas de posições dos vértices, deixando as rotas parecidas com a gbest. -

Na 3ª iteração, a melhor partícula é p3, com solução 36,05. Calculamos as velocidades por meio de trocas de posições dos vértices, deixando as rotas parecidas com a gbest. -
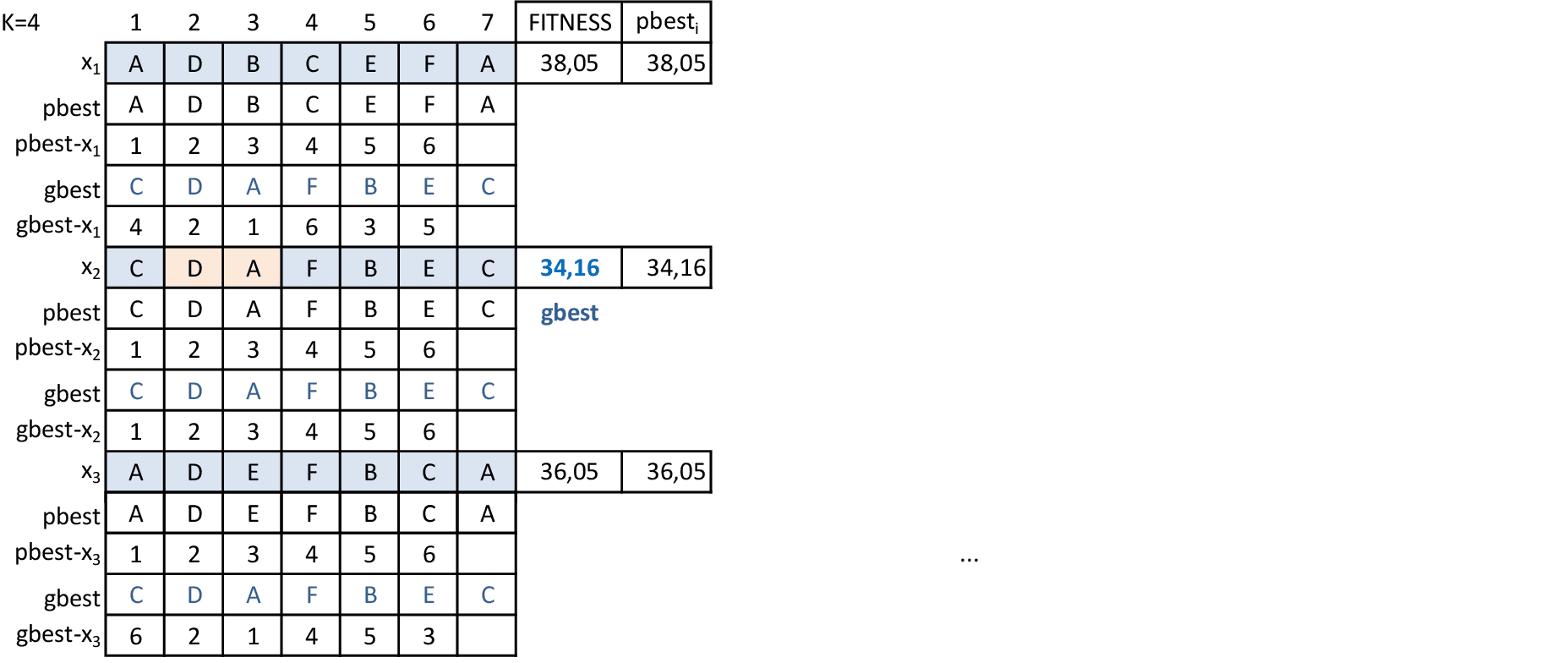
A técnica prossegue até que as rotas fiquem todas iguais à gbest. Neste momento, podemos criar 2 novas partículas, mantendo-se a partícula gbest para não perdermos boas soluções. Esta técnica de "espalhar" as partículas pode ser feita algumas vezes, até alcançarmos um número máximo de iterações.

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Nuvem de Partículas para encontrar uma solução para o problema da Mochila. Vamos utilizar 3 partículas que representam soluções do problema.
-

Começamos calculando os valores da função objetivo de cada partícula. As velocidades são aplicadas com as trocas de valores dos objetos (0 ou 1), tentando "imitar" as soluções pbesti e gbest. -

Com os parâmetros indicados, temos a 1ª iteração da técnica. A melhor partícula é p3, com solução 9. Calculamos as velocidades por meio de trocas de valores dos objetos, deixando as soluções parecidas com a gbest. -

Escolhemos 1 troca de gbest - x1: na posição 3, que a partícula gbest tem valor 1. Escolhemos 1 troca de gbest - x2: na posição 2, que a partícula gbest tem valor 0. -

Na 2ª iteração, a melhor partícula é p1, com solução 9. Calculamos as velocidades por meio de trocas de valores dos objetos, deixando as soluções parecidas com pbest e gbest. -

Escolhemos 1 troca de gbest - x2: na posição 4, que a partícula gbest tem valor 1. Escolhemos 1 troca de gbest - x3: na posição 5, que a partícula gbest tem valor 0. -

Na 3ª iteração, a melhor partícula é p1, com solução 9. Calculamos as velocidades por meio de trocas de valores dos objetos, deixando as soluções parecidas com pbest e gbest. -

Escolhemos 1 troca de gbest - x2: na posição 5, que a partícula gbest tem valor 0. Escolhemos 1 troca de gbest - x3: na posição 4, que a partícula gbest tem valor 1. -
A técnica prossegue até que as soluções fiquem todas iguais à gbest. Depois disso, podemos criar 2 novas partículas, mantendo-se a partícula gbest para não perdermos boas soluções. Esta técnica de "espalhar" as partículas pode ser feita algumas vezes, até alcançarmos um número máximo de iterações.

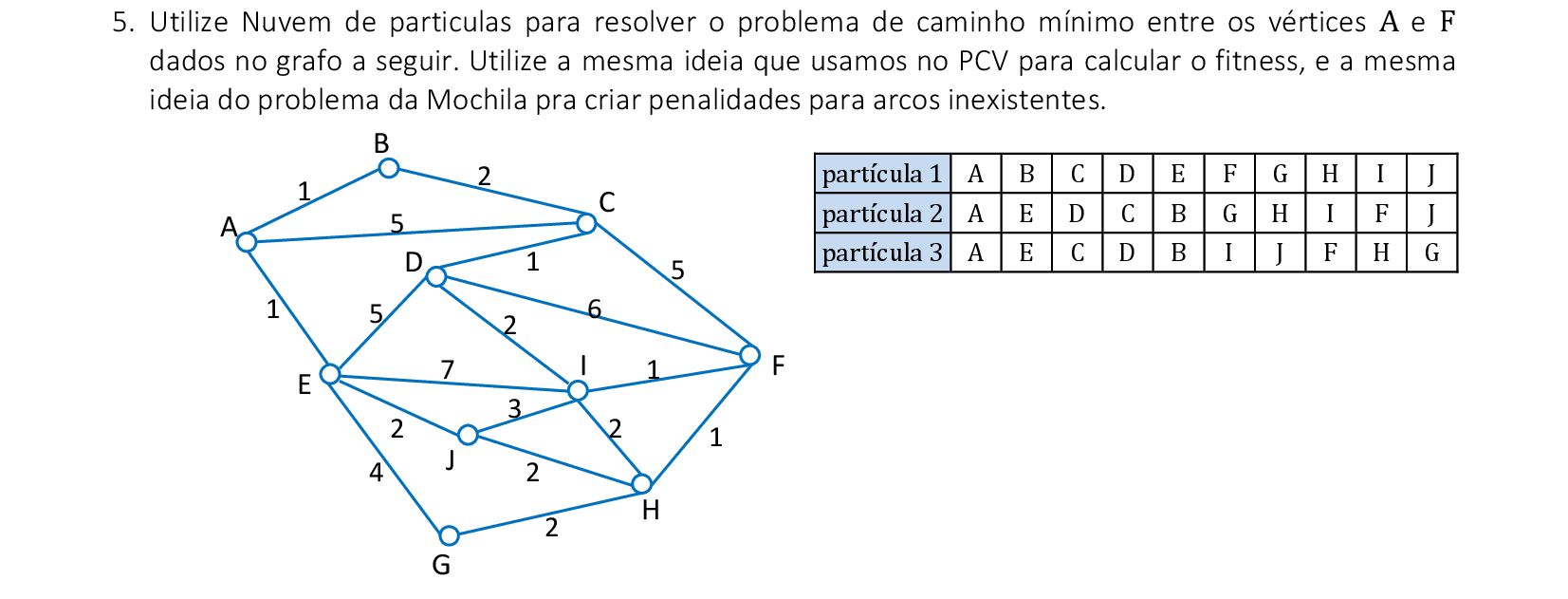
11. Simulated Annealing, ILS e GRASP
Material das páginas 93 até 99.


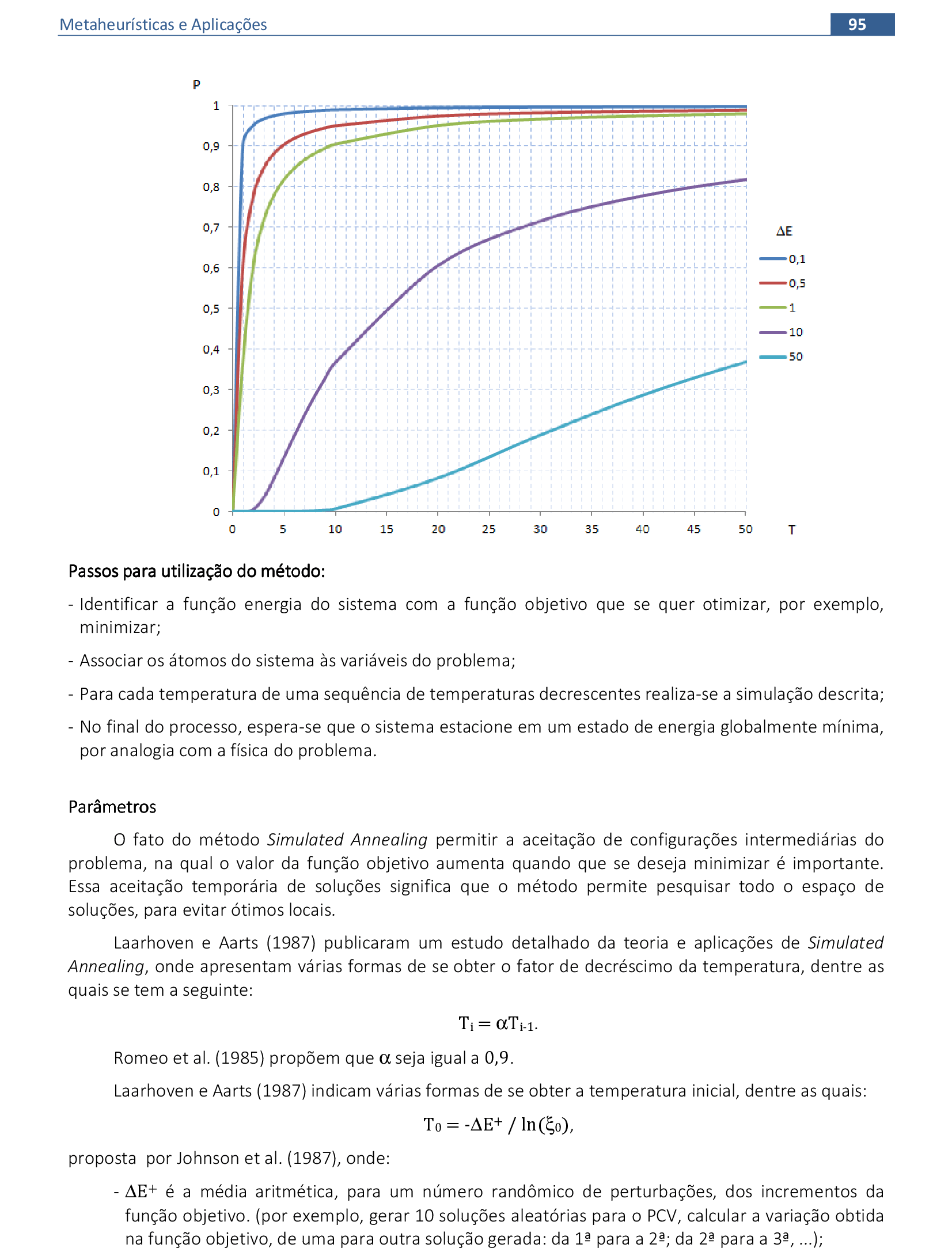

📃 Algoritmo comentado
Inicialização: S0 (solução inicial), M (máximo de iterações), V (máximo de vizinhos),
L (máximo de sucessos), S = S0, T = T0, iteração = 1
Repita
i = 1 (número de soluções vizinhas encontradas), nsucess = 0
Repita
Crie uma solução Si+1, vizinha de Si
Calcule a função objetivo para Si+1
Calcule a probabilidade P de aceitação de nova solução: P = e-ΔE/T
Se ΔE = f(Si+1) - f(Si) ≤ 0 ou P > rnd, então
S = Si+1 (melhor solução)
nsucess = nsucess + 1
fim
i = i + 1 (tentativas)
Até nsucess ≥ L ou i > V
T = αT
iteração = iteração + 1
Até nsucess = 0 ou iteração ≥ M

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação do Simulated Annealing para encontrar rotas para o problema do Caixeiro Viajante. Vamos utilizar a solução inicial S0 indicada.
-

Na 1ª iteração, encontramos a solução vizinha S1 com uma troca de arcos de S0. Como f(S1) ≤ f(S0), então a solução é aceita e podemos atualizar a temperatura para a próxima iteração. -

Na 2ª iteração, encontramos a solução vizinha S2 com uma troca de arcos de S1. Como f(S2) > f(S1), então utilizamos a probabilidade P para verificar a aceitação desta solução. -

Como P < rnd, a solução não é aceita e podemos encontrar mais uma vizinha de S1 (o máximo é V = 2). Como f(S2) ≤ f(S1), então aceitamos a solução e podemos atualizar a temperatura para a próxima iteração. -

Na 3ª iteração, encontramos a solução vizinha S3 com uma troca de arcos de S2. Como f(S3) > f(S2), então utilizamos a probabilidade P para verificar a aceitação desta solução. -

Como P > rnd, a solução é aceita e podemos podemos atualizar a temperatura para a próxima iteração. O processo continua até atingir um número máximo de iterações.

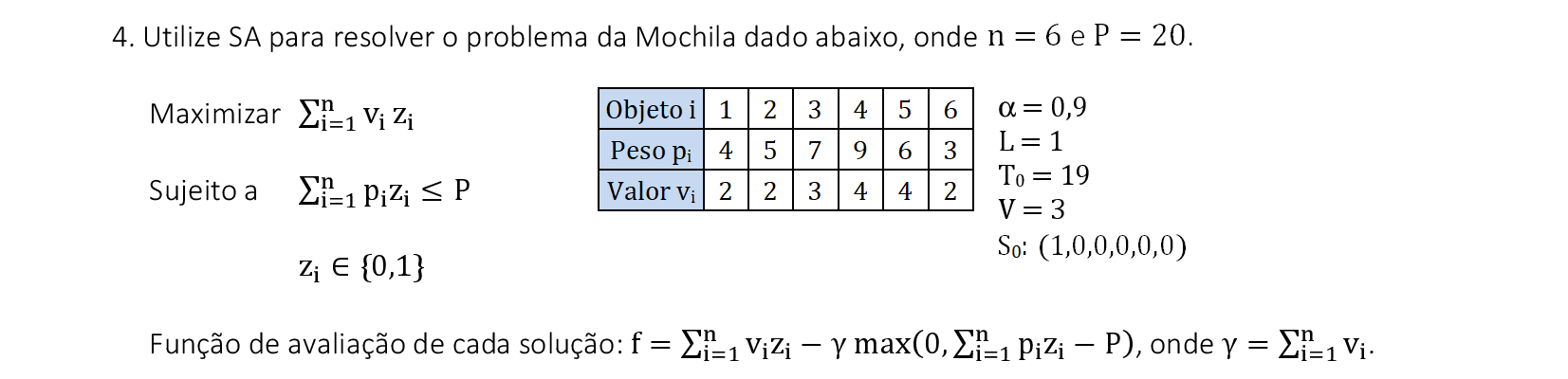
📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação do Simulated Annealing para encontrar soluções para o problema da Mochila. Vamos utilizar a solução inicial S0 indicada.
-

Na 1ª iteração, encontramos a solução vizinha S1 com uma troca de objetos em S0. Como f(S1) ≥ f(S0), então a solução é aceita e podemos atualizar a temperatura para a próxima iteração. -

Na 2ª iteração, encontramos a solução vizinha S2 com uma troca de objetos em S1. Como f(S2) < f(S1), então utilizamos a probabilidade P para verificar a aceitação desta solução. -

Como P < rnd, a solução não é aceita e podemos encontrar mais uma vizinha de S1 (o máximo é V = 2). Como f(S2) ≥ f(S1), então aceitamos a solução e podemos atualizar a temperatura para a próxima iteração. -

Na 3ª iteração, encontramos a solução vizinha S3 com uma troca de objetos em S2. Como f(S3) < f(S2), então utilizamos a probabilidade P para verificar a aceitação desta solução. -

Como P > rnd, a solução é aceita e podemos podemos atualizar a temperatura para a próxima iteração. O processo continua até atingir um número máximo de iterações.

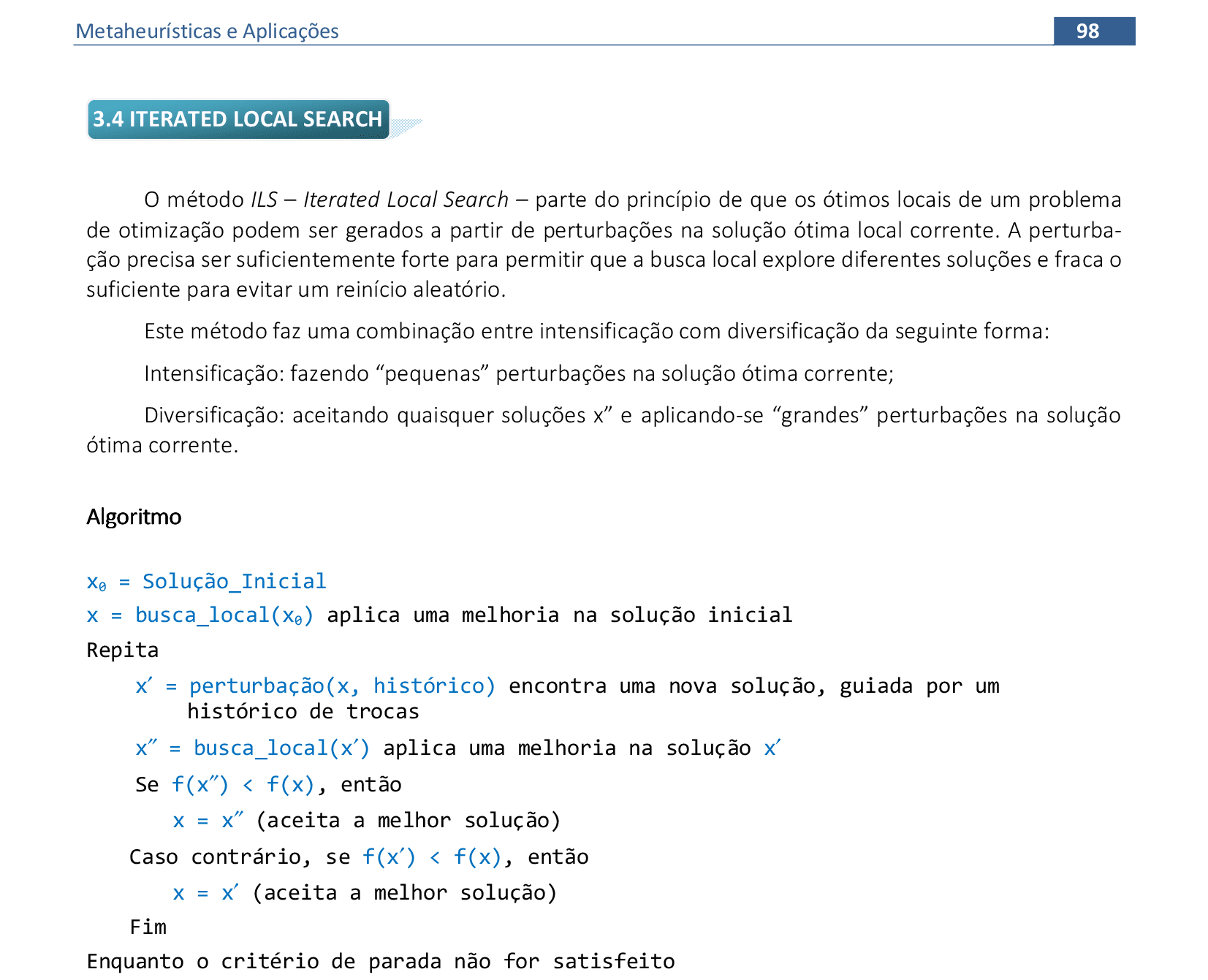
📃 Algoritmo comentado
x0 = Solução_Inicial
x = busca_local(x0) aplica uma melhoria na solução inicial
Repita
x' = perturbação(x, histórico) encontra uma nova solução, guiada por um histórico de trocas
x'' = busca_local(x') aplica uma melhoria na solução x'
Se f(x'') < f(x), então
x = x'' (aceita a melhor solução)
Caso contrário, se f(x') < f(x), então
x = x' (aceita a melhor solução)
Fim
Enquanto o critério de parada não for satisfeito

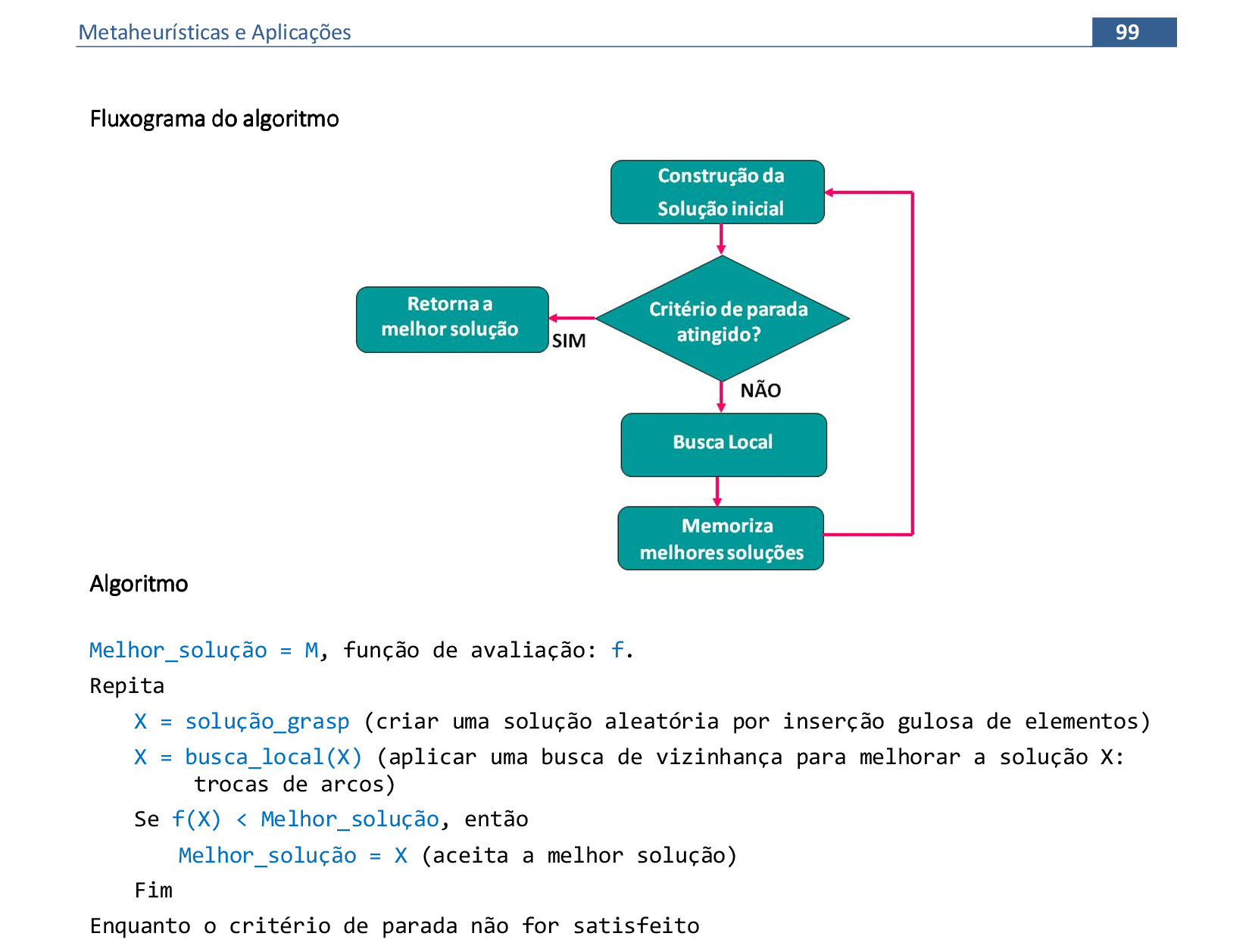
📃 Algoritmo comentado
Melhor_solução = M, função de avaliação: f.
Repita
X = solução_grasp (criar uma solução aleatória por inserção gulosa de elementos)
X = busca_local(X) (aplicar uma busca de vizinhança para melhorar a solução X: trocas de arcos)
Se f(X) < Melhor_solução, então
Melhor_solução = X (aceita a melhor solução)
Fim
Enquanto o critério de parada não for satisfeito
12. Colônia de Formigas e VNS
Material da página 99 até a página 106.





📃 Algoritmo comentado
Coloque cada formiga em uma cidade aleatória
Para t = 1 até o número máximo de iterações
Para k = 1 até m (nº de formigas)
Enquanto a formiga k não construir a viagem Sk
Selecione a próxima cidade pela regra da probabilidade:
pijk = τijαηijβ / ∑l∈Njk τilαηjlβ, quando j ∈ Njk.
Fim
Calcule a distância Lk da viagem Sk
Se Lk < L* então
S* = Sk, L* = Lk
Fim
Fim
Atualize os feromônios: τij = (1-ρ)τij + ∑k=1mΔτijk, onde:
Δτijk = Q / Lk quando a aresta (i, j) pertence Sk, onde Q é uma constante.
Δτijk = 0 em caso contrário.
Fim
O resultado é a rota S*.

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Colônia de Formigas para encontrar soluções para o problema do Caixeiro Viajante. Vamos utilizar os parâmetros indicados de α e β.
-

O valor de ηij é o inverso do custo cij. Desta forma, os menores custos têm maior atratividade para a técnica. A formiga 1 começa a rota pela cidade 1. -

Para decidir se a formiga 1 vai da cidade 1 para a cidade 2, note que calculamos os valores de τ1l e η2l, para todas as cidades l ainda não visitadas. Desta forma, a técnica prevê o que acontece com a decisão de usar a cidade 2 analisando todas as cidades ainda não visitadas. -

Escolhemos a maior probabilidade, e podemos calcular da mesma forma a sequência da rota: da cidade 2 para a cidade 3, e assim sucessivamente. A rota encontrada da formiga 1 tem custo L1 = 9,8. Devemos guardar quais arcos são usados por cada formiga. -

Os cálculos são feitos de forma similar para as demais formigas. A formiga 2 começa a rota pela cidade 2, com custo L2 = 10,8. -

A formiga 3 começa a rota pela cidade 3, com custo L3 = 10,9. -

A formiga 4 começa a rota pela cidade 4, com custo L4 = 10,9. -

A formiga 5 começa a rota pela cidade 5, com custo L5 = 9,8. -

A melhor solução encontrada foi com custo L* = 9,8. As "contribuições" de feromônios são feitas com base nos arcos que cada formiga utilizou. As contribuições de cada formiga k são calculadas por meio do inverso do custo de cada rota: Δijk = Q / Lk. -

Por exemplo, o arco (1, 2) foi usado pelas formigas 1, 4 e 5: logo, o feromônio τ12 terá as contribuições Δ12 de cada formiga. O valor ρ é da taxa de evaporação do feromônio. -

O arco (1, 4) não foi usado pelas formigas, e tem atualização somente da evaporação do feromônio. Os cálculos das demais atualizações de feromônios são feitos da mesma forma. -

Com as novas taxas de feromônios calculadas, podemos começar a 2ª iteração. A formiga 1 começa a rota na cidade 1. -

A formiga 2 começa a rota na cidade 2, e assim sucessivamente. A técnica pode ser executada até que as soluções fiquem todas com mesmo valor da função objetivo.
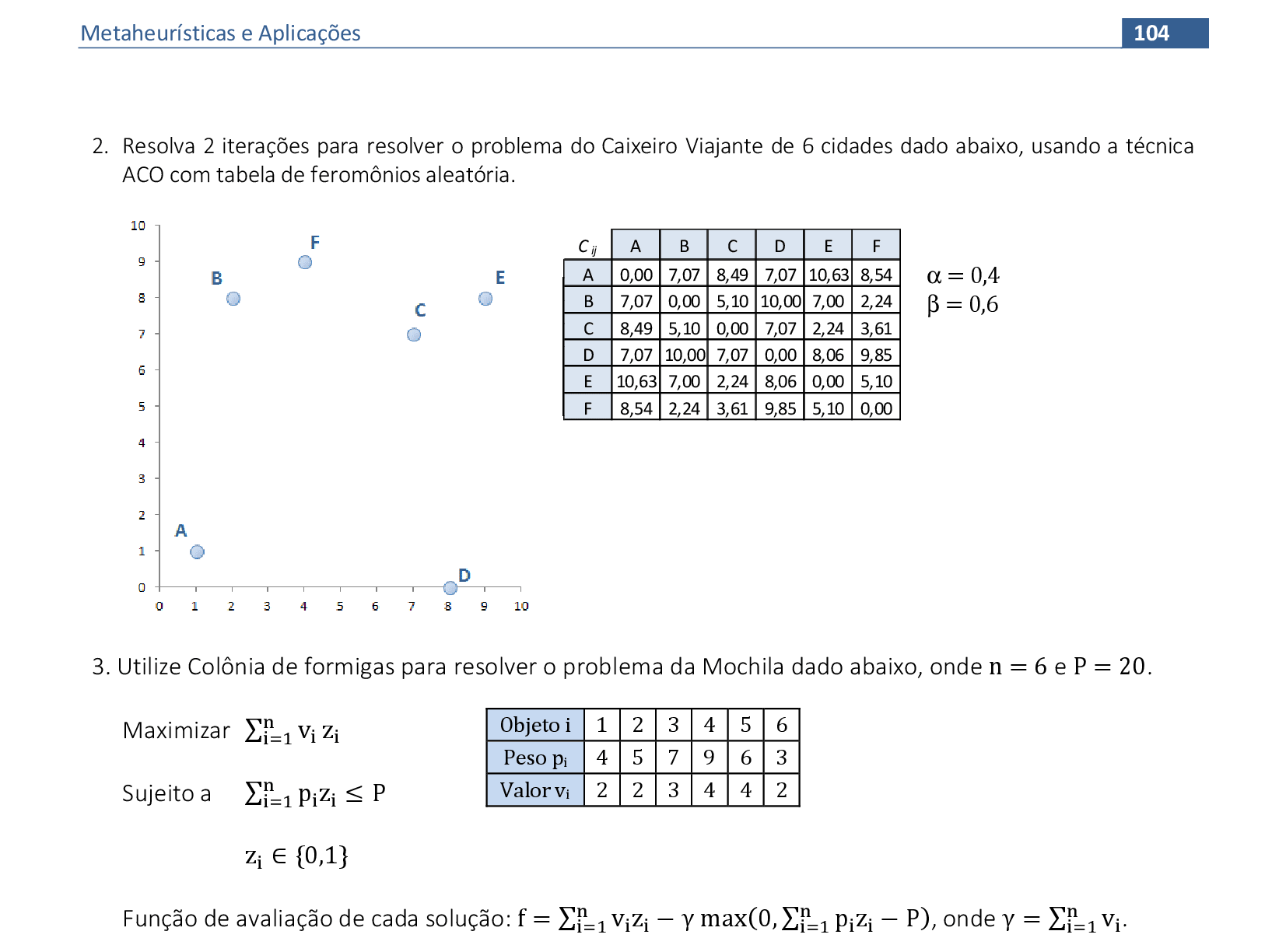

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Colônia de Formigas para encontrar soluções para o problema da Mochila. Vamos utilizar os parâmetros indicados de α e β. A fórmula da probabilidade fica mais simplificada, com apenas o índice i.
-
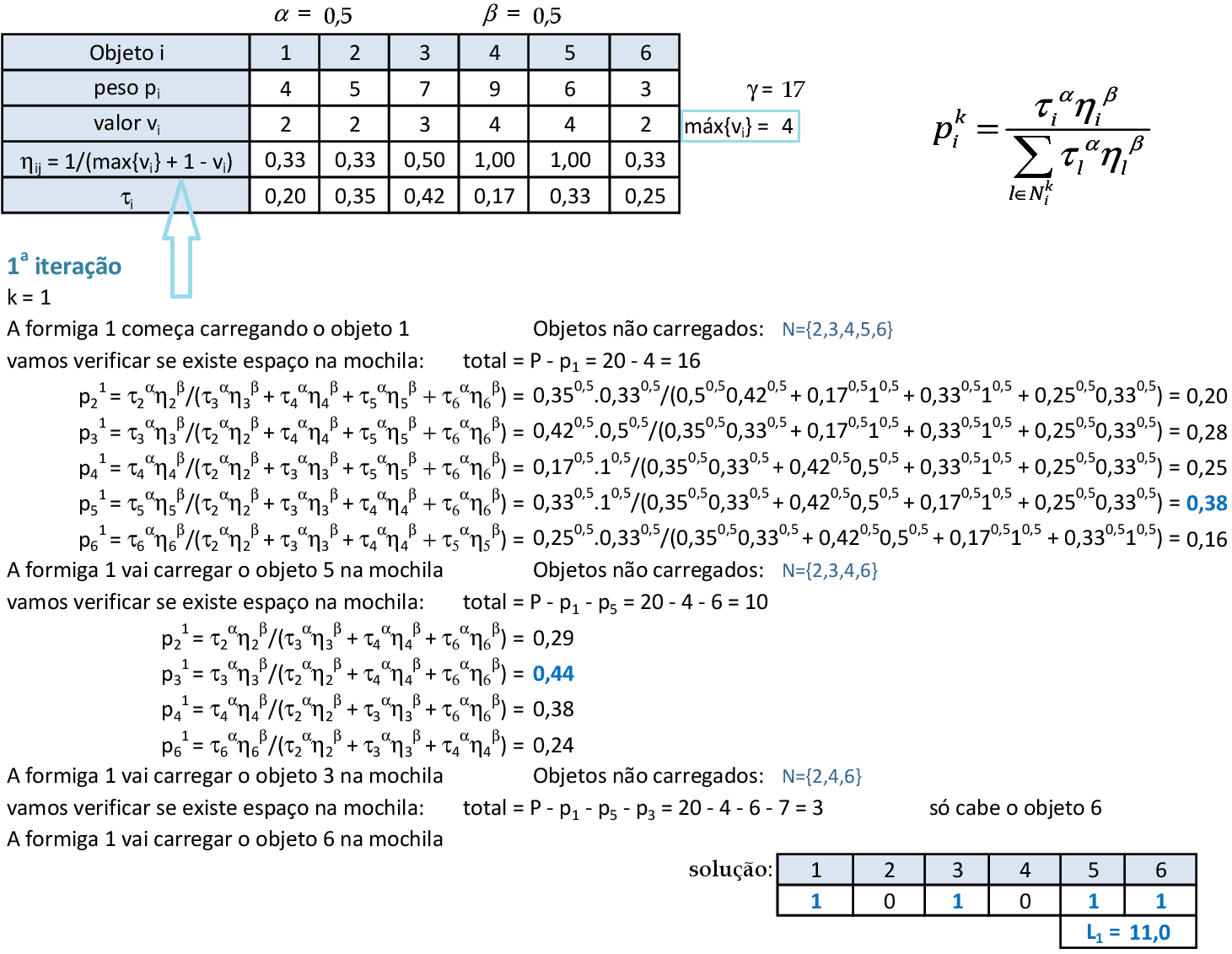
Os valores de η são calculados utilizando o valor máximo vi, pois temos um problema de maximização. A formiga 1 começa carregando o objeto 1, e fazemos os cálculos de forma parecida com os cálculos feitos para o PCV. -
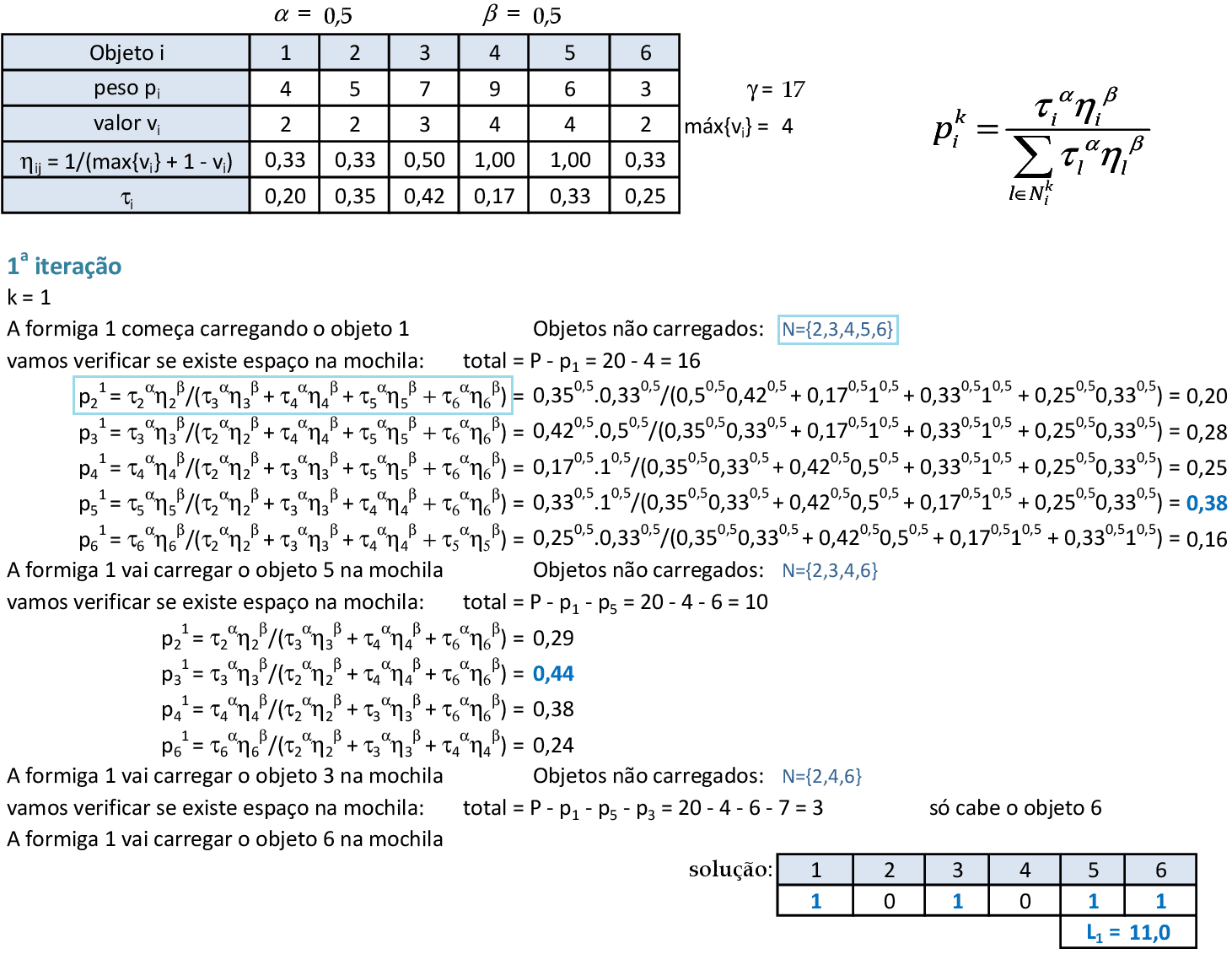
A vizinhança N contém os objetos ainda não carregados pela formiga, e a probabilidade utiliza apenas um índice de feromônio τ e atratividade η. Podemos verificar sempre a capacidade da mochila antes de fazer os cálculos de probabilidades. Nesta situação, a formiga consegue colocar os objetos 2, 3, 5 e 6 na mochila, com custo L1 = 11. -

A formiga 2 começa com o segundo objeto, e consegue carregar os objetos 2, 3 e 5 na mochila, com custo L2 = 9. -

A formiga 3 começa com o terceiro objeto, e consegue carregar os objetos 2, 3 e 5 na mochila, com custo L3 = 9. -

A formiga 4 começa com o quarto objeto, e consegue carregar os objetos 2, 4 e 5 na mochila, com custo L4 = 10. -

A formiga 5 começa com o quinto objeto, e consegue carregar os objetos 2, 3 e 5 na mochila, com custo L5 = 9. -

Para finalizar a iteração, a formiga 6 começa com o sexto objeto, e consegue carregar os objetos 1, 3, 5 e 6 na mochila, com custo L6 = 11. -

A melhor solução encontrada foi com custo L* = 11. As "contribuições" de feromônios são feitas com base nos objetos que cada formiga carregou. Como o problema é de maximização, podemos utilizar o valor de γ para atribuir maiores feromônios às soluções com custos maiores. -

Por exemplo, o objeto 2 foi carregado pelas formigas 2, 3, 4 e 5: logo, o feromônio τ2 terá as contribuições Δ2 de cada formiga. O valor ρ é da taxa de evaporação do feromônio. -

Com as novas taxas de feromônios calculadas, podemos começar a 2ª iteração. A técnica pode ser executada até que as soluções fiquem todas com mesmo valor da função objetivo.




📃 Algoritmo comentado
x0 = Solução_Inicial.
x = busca_local(x0) aplica uma melhoria na solução inicial
Repita
x' = vizinho(x) encontra uma nova solução, vizinha de x através de 1 troca de arcos
x'' = busca_local(x') aplica uma melhoria na solução x'
Se f(x'') < f(x), então
x = x'' (aceita a melhor solução)
Caso contrário, se f(x') < f(x), então
x = x' (aceita a melhor solução)
Fim
Enquanto o critério de parada não for satisfeito
13. Algoritmos Genéticos
Material da página 106 até a página 116.







📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Algoritmos Genéticos para encontrar o valor máximo da função f(x), com uma população de 4 indivíduos. Utilizaremos 1 ponto de cruzamento e mutação apenas se um número aleatório for maior do que 0,5.
-

Em problemas de maximização, usamos o valor da função objetivo como fitness, pois soluções com maiores valores nos fornecem maiores probabilidades pj. Como os indivíduos serão usados em formato binário, encontramos os respectivos valores decimais e calculamos o valor da função f para cada indivíduo. -

Utilizando o método da roleta, encontramos 4 números aleatórios que definem quais serão os indivíduos que participam dos cruzamentos: para o primeiro par de indivíduos (i1 e i3), encontramos um número aleatório entre 0 e 5 (2,51), que indica o ponto de cruzamento está entre o terceiro e o quarto bit. -

Trocamos os materiais genéticos entre o ponto de cruzamento e o final de cada indivíduo, gerando os novos filhos i1 e i2. Para o segundo par de indivíduos (i2 e i1), encontramos um número aleatório entre 0 e 5 (1,23), que indica o ponto de cruzamento está entre o segundo e o terceiro bit. -
Trocamos os materiais genéticos entre o ponto de cruzamento e o final de cada indivíduo, gerando os novos filhos i3 e i4. Agora vamos fazer as mutações nestes novos indivíduos. -

Podemos sortear um número n1 que define quando será feita a mutação. No caso do indivíduo i3, temos n1 > 0,5, e n2 = 2,66 nos fornece o ponto de mutação no terceiro bit do indivíduo. Logo, a terceira posição de i3 torna-se 1. -
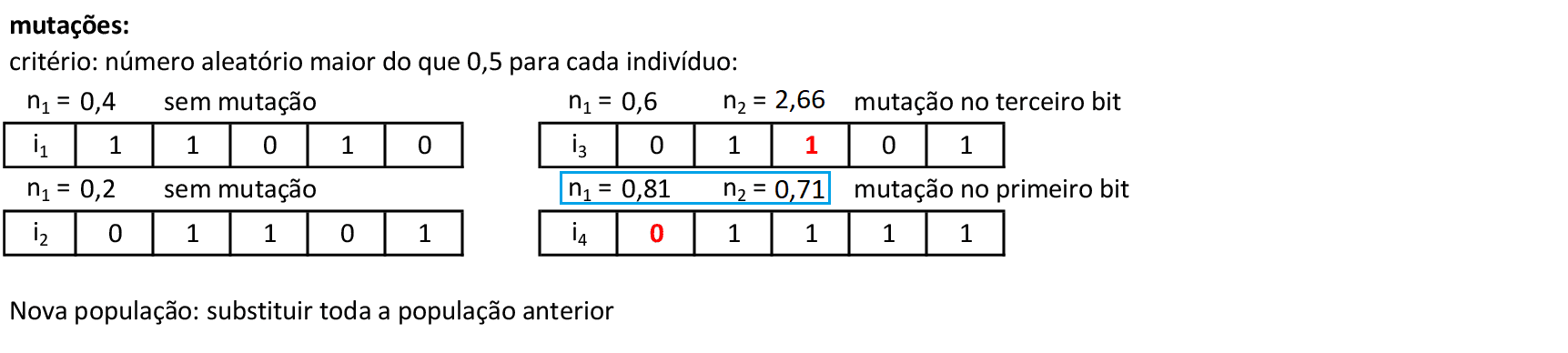
No caso do indivíduo i4, temos n1 > 0,5, e n2 = 0,71 nos fornece o ponto de mutação no primeiro bit do indivíduo. Logo, a primeira posição de i4 torna-se 0. Os outros indivíduos não sofrem mutações pois n1 < 0,5. Substituindo a população, temos uma nova iteração. -

Encontramos os valores dos fitness dos novos indivíduos e as respectivas probabilidades de escolhas para usarmos na roleta: pj. -
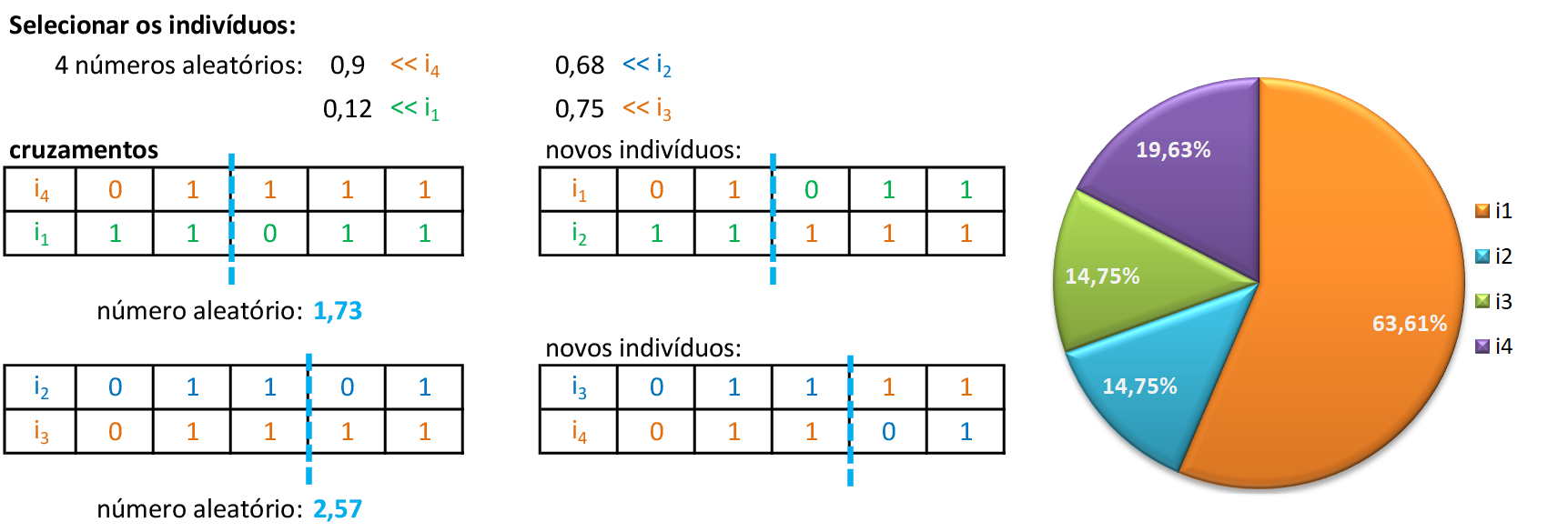
Selecionamos os indivíduos por meio de 4 números aleatórios, e criamos os pontos de cruzamentos. Trocamos os materiais genéticos dos indivíduos escolhidos e podemos avançar para a fase de mutações. -
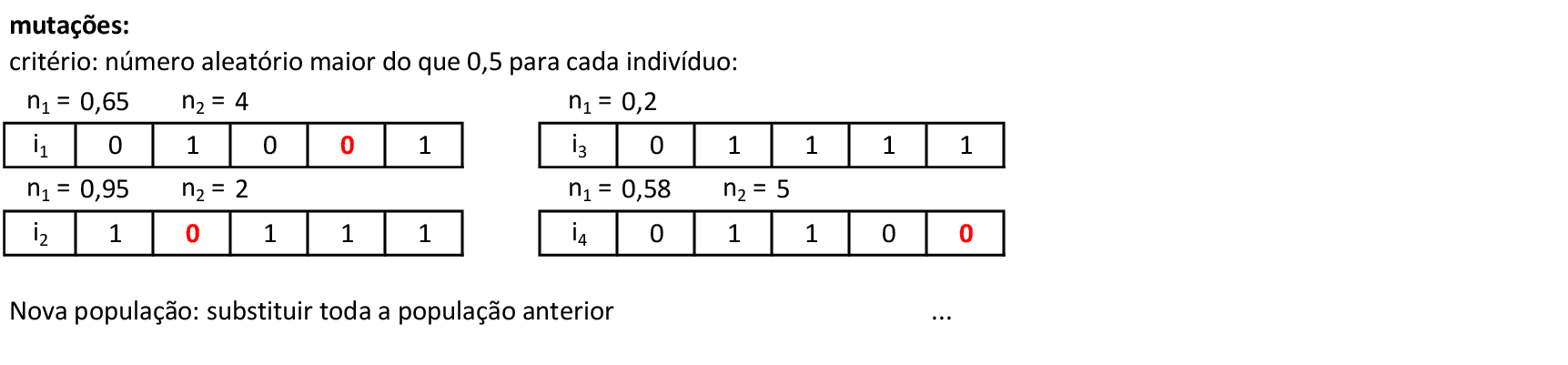
Usando o mesmo critério da primeira iteração, temos as mutações nos indivíduos i1, i2 e i4. Desta forma, criamos a nova população e podemos concluir a iteração. O processo continua até que um critério de parada seja satisfeito (solução máxima encontrada ou número máximo de iterações).


📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Algoritmos Genéticos para encontrar soluções para o problema da Mochila, com uma população de 4 indivíduos. Utilizaremos 2 pontos de cruzamento e mutação apenas se um número aleatório for maior do que 0,5.
-
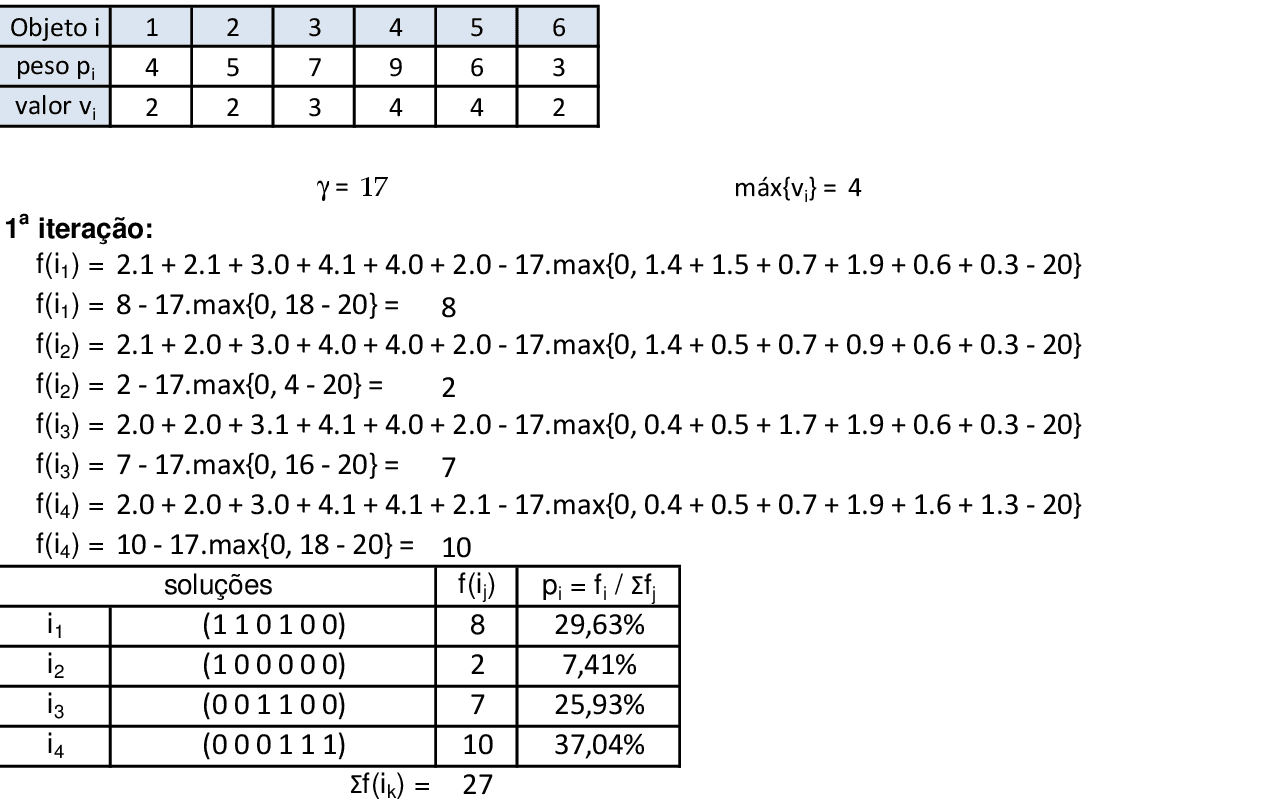
Utilizamos o valor da função objetivo como fitness de cada indivíduo, pois soluções com maiores valores nos fornecem maiores probabilidades pj. -
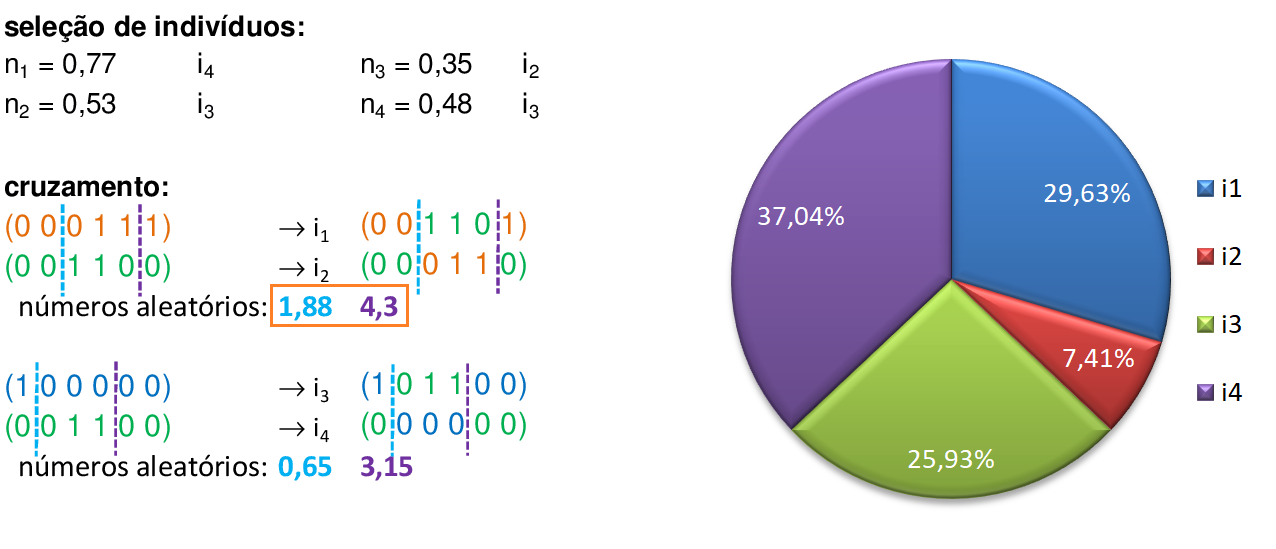
Utilizando o método da roleta, encontramos 4 números aleatórios que definem quais serão os indivíduos que participam dos cruzamentos: para o primeiro par de indivíduos (i4 e i3), encontramos dois números aleatórios entre 0 e 6 (1,88 e 4,3), que indicam os pontos de cruzamento entre o segundo e o terceiro bit (1,88) e entre o quinto e o sexto bit (4,3). -
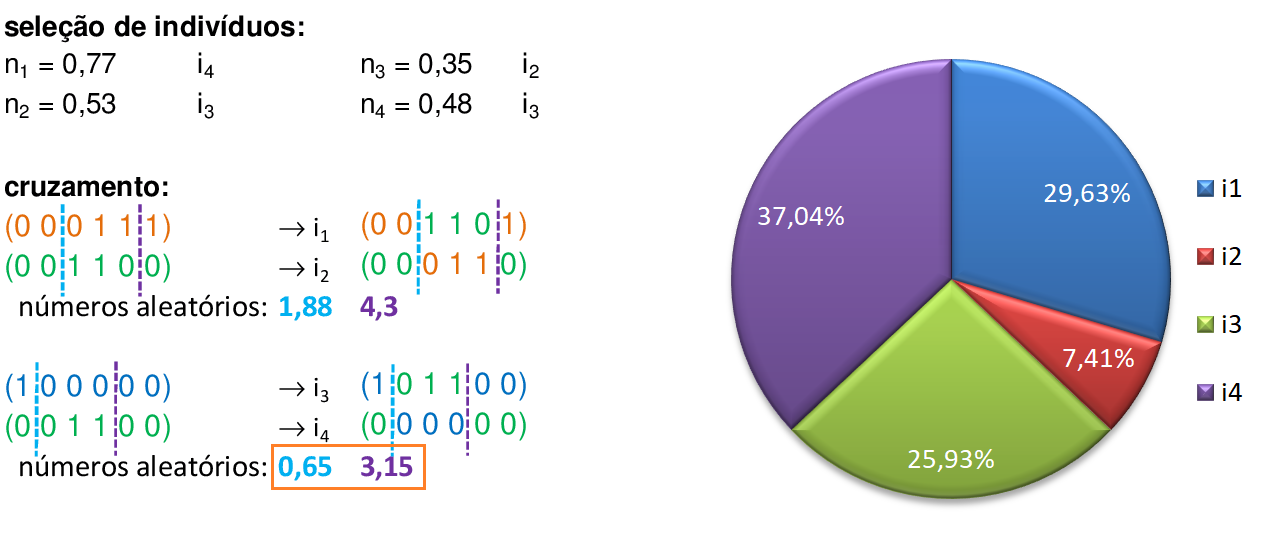
Trocamos os materiais genéticos entre os pontos de cruzamento, gerando os novos filhos i1 e i2. Para o segundo par de indivíduos (i2 e i3), encontramos dois números aleatórios entre 0 e 6 (0,65 e 3,15), que indicam os pontos de cruzamento entre o primeiro e o segundo bit (0,65) e entre o quarto e o quinto bit (3,15). -
Trocamos os materiais genéticos entre os pontos de cruzamento, gerando os novos filhos i3 e i4. Agora vamos fazer as mutações nestes novos indivíduos. -

Podemos sortear um número n1 que define quando será feita a mutação. No caso do indivíduo i1, temos n1 > 0,5, e n2 = 3,77 nos fornece o ponto de mutação no quarto bit do indivíduo. Logo, a quarta posição de i1 torna-se 0. -

No caso do indivíduo i4, temos n1 > 0,5, e n2 = 2,8 nos fornece o ponto de mutação no terceiro bit do indivíduo. Logo, a terceira posição de i4 torna-se 1. Os outros indivíduos não sofrem mutações pois n1 < 0,5. Substituindo a população, temos uma nova iteração. -

Encontramos os valores dos fitness dos novos indivíduos e as respectivas probabilidades de escolhas para usarmos na roleta: pj. -
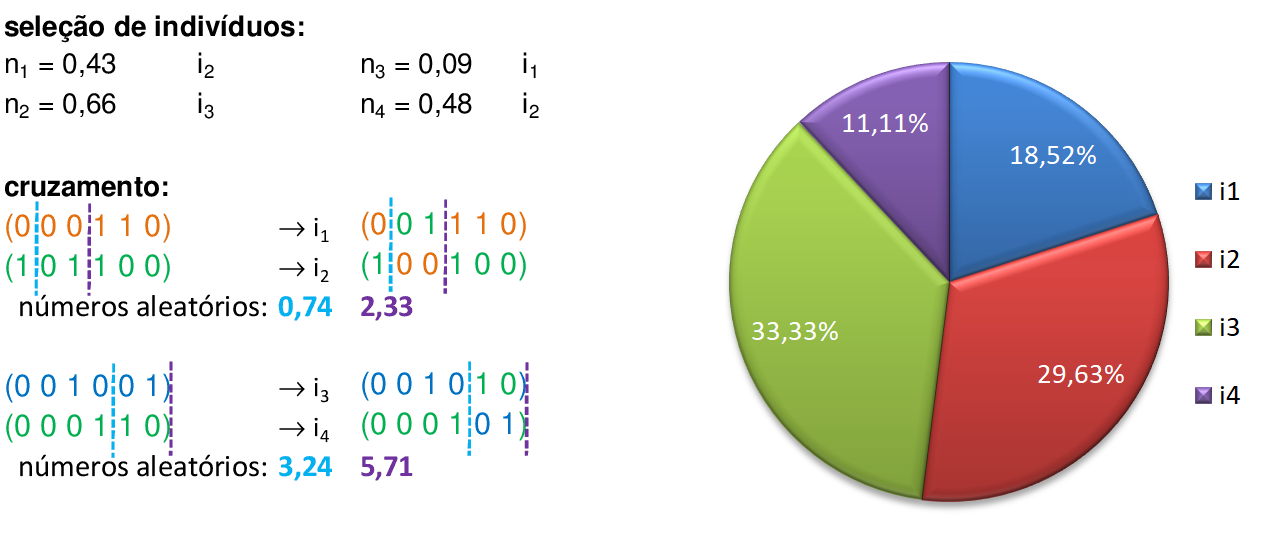
Selecionamos os indivíduos por meio de 4 números aleatórios, e criamos os pontos de cruzamentos. Trocamos os materiais genéticos dos indivíduos escolhidos e podemos avançar para a fase de mutações. -

Usando o mesmo critério da primeira iteração, temos as mutações nos indivíduos i1 e i2. Desta forma, criamos a nova população e podemos concluir a iteração. O processo continua até que um critério de parada seja satisfeito (solução máxima encontrada ou número máximo de iterações).


📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Algoritmos Genéticos para encontrar soluções para o problema do Caixeiro Viajante, com uma população de 4 indivíduos. Utilizaremos 2 pontos de cruzamento e mutação apenas se um número aleatório for maior do que 0,5.
-

Como o problema é de minimização, vamos usar como fitness fj = (max{rotak} + 1) - rotaj. Desta forma, soluções com menores valores nos fornecem maiores probabilidades pj. -
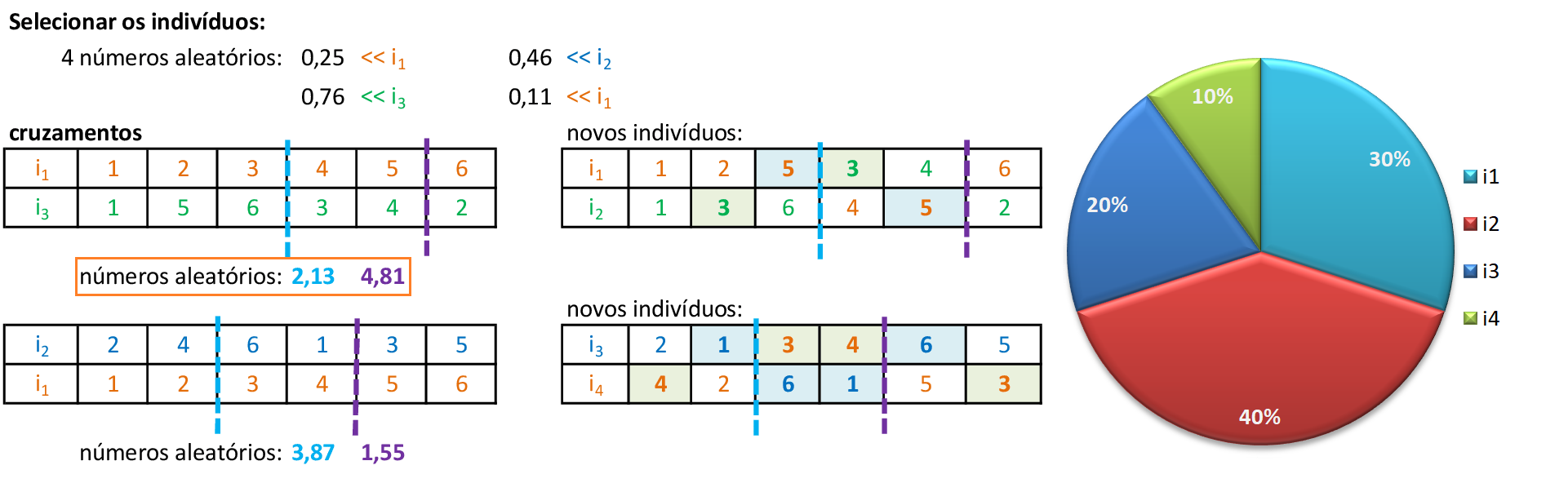
Utilizando o método da roleta, encontramos 4 números aleatórios que definem quais serão os indivíduos que participam dos cruzamentos: para o primeiro par de indivíduos (i1 e i3), encontramos dois números aleatórios entre 0 e 6 (2,13 e 4,81), que indicam os pontos de cruzamento entre o terceiro e o quarto bit (2,13) e entre o quinto e o sexto bit (4,81). -
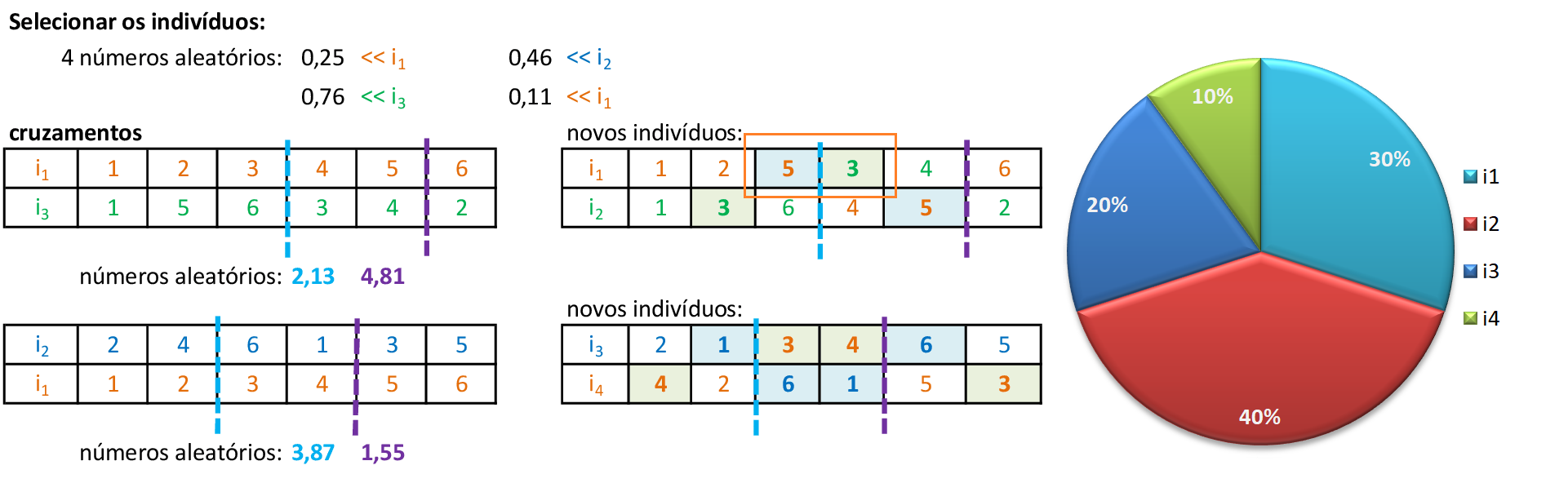
Trocamos os materiais genéticos entre os pontos de cruzamento, gerando os novos filhos i1 e i2. Para evitar soluções infactíveis, devemos trocar as cidades repetidas que entraram nas novas rotas: na terceira posição de i1, trocamos a cidade 3 pela cidade 5, e na segunda posição de i2, trocamos a cidade 5 pela cidade 3. -
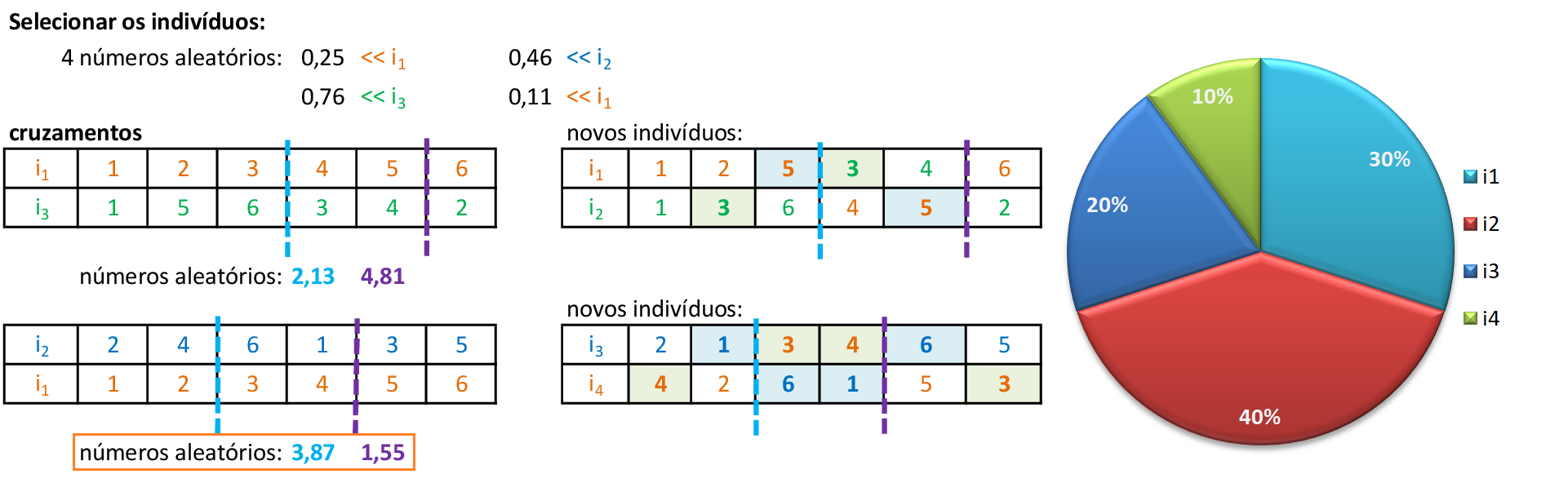
Para o segundo par de indivíduos (i2 e i1), encontramos dois números aleatórios entre 0 e 6 (3,87 e 1,55), que indicam os pontos de cruzamento entre o segundo e o terceiro bit (1,55) e entre o quarto e o quinto bit (3,87). -

Trocamos os materiais genéticos entre os pontos de cruzamento, gerando os novos filhos i3 e i4. Para evitar soluções infactíveis, devemos trocar as cidades repetidas que entraram nas novas rotas: na segunda posição de i3, trocamos a cidade 4 pela cidade 1 e na quinta posição trocamos a cidade 3 pela cidade 6; na primeira posição de i4, trocamos a cidade 1 pela cidade 4 e na sexta posição trocamos a cidade 6 pela cidade 3. -

Podemos sortear um número n1 que define quando será feita a mutação. No caso do indivíduo i4, temos n1 > 0,5, n2 = 3,2 (quarta posição) e n3 = 0,71 (primeira posição). Logo, podemos trocar as cidades da primeira com a quarta posição do indivíduo. Substituímos a população e podemos começar a 2ª iteração. -

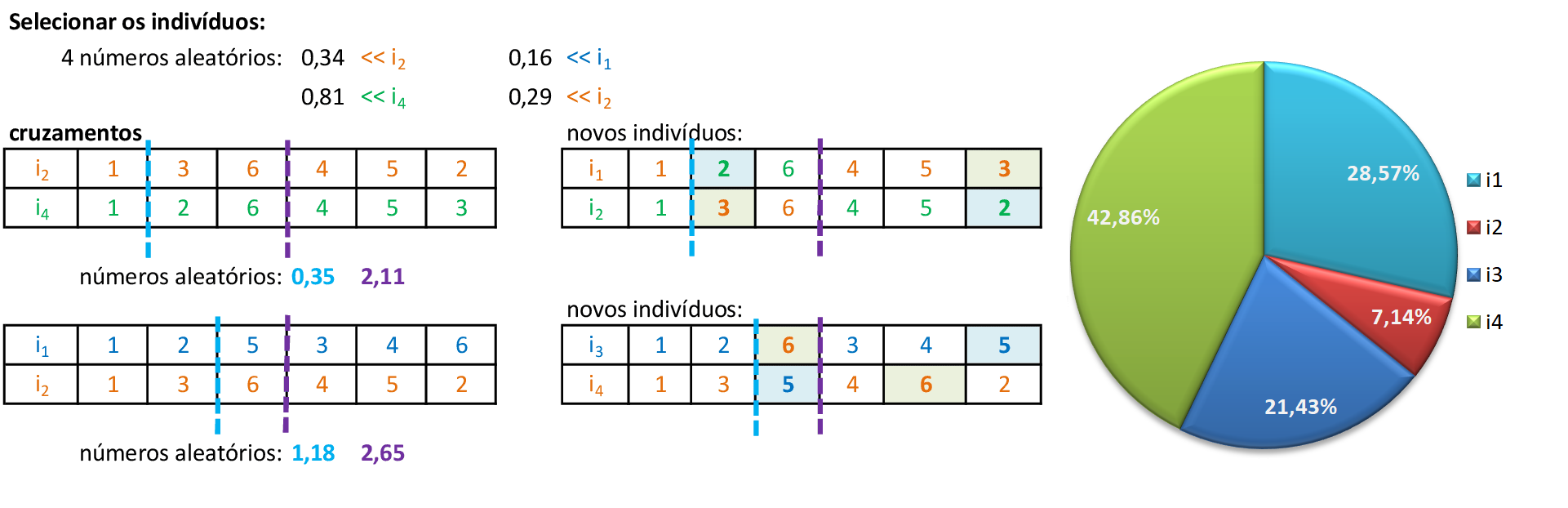
Encontramos os valores dos fitness dos novos indivíduos e as respectivas probabilidades de escolhas para usarmos na roleta: pj. -
Selecionamos os indivíduos por meio de 4 números aleatórios, e criamos os pontos de cruzamentos. Trocamos os materiais genéticos dos indivíduos escolhidos, fazendo as trocas de cidades repetidas, e podemos avançar para a fase de mutações. -

Usando o mesmo critério da primeira iteração, temos as mutações nos indivíduos i1 e i2. Desta forma, criamos a nova população e podemos concluir a iteração. O processo continua até que um critério de parada seja satisfeito (solução máxima encontrada ou número máximo de iterações).

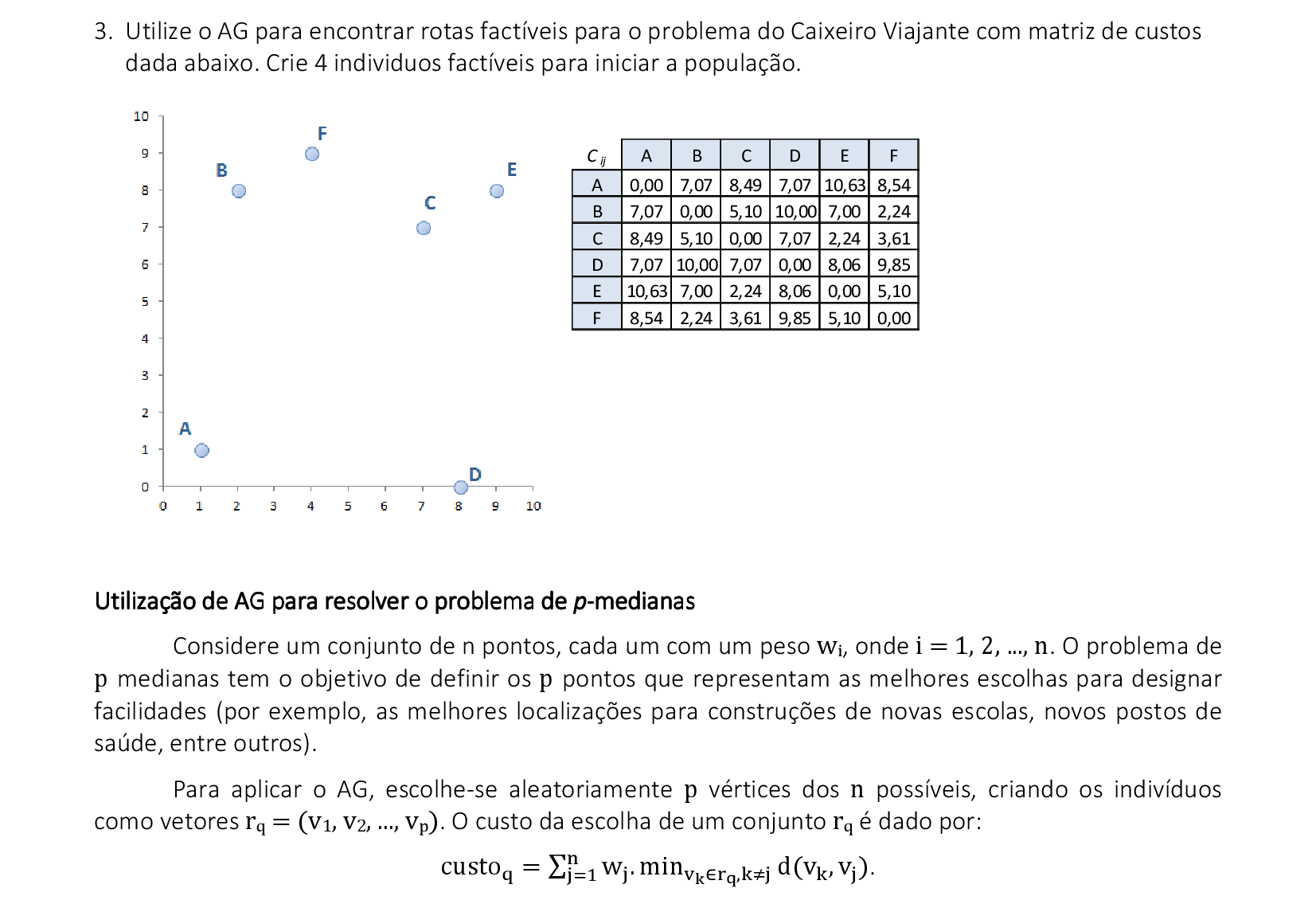

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Algoritmos Genéticos para encontrar soluções para o problema das p-medianas, com uma população de 5 indivíduos. Utilizaremos 1 ponto de cruzamento e mutação apenas se um número aleatório for maior do que 0,5.
-
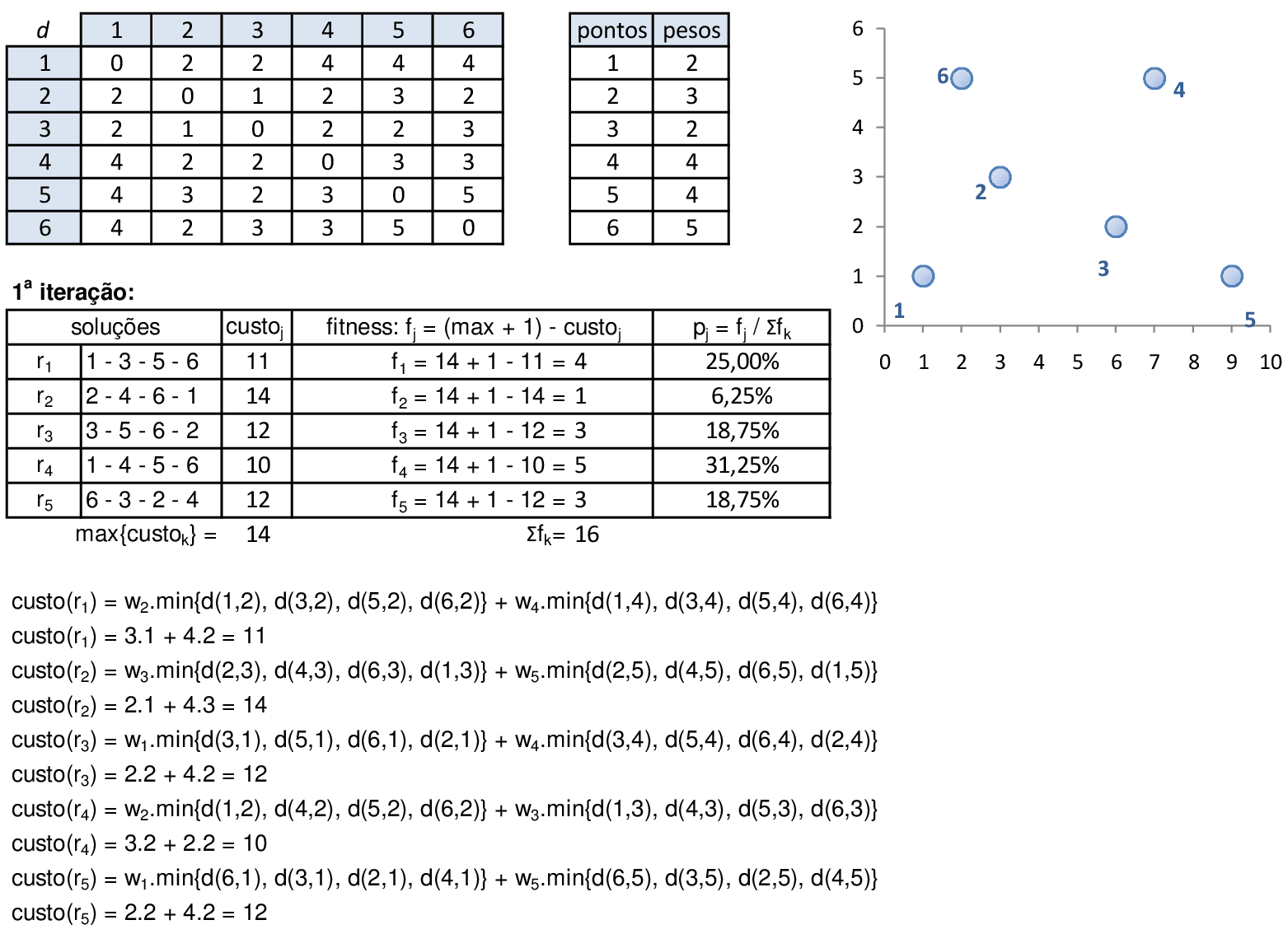
Como o problema é de minimização, vamos usar como fitness fj = (max{custok} + 1) - custoj. Desta forma, soluções com menores valores nos fornecem maiores probabilidades pj. -

Utilizando o método da roleta, encontramos 4 números aleatórios que definem quais serão os indivíduos que participam dos cruzamentos. O primeiro par de indivíduos (r1 e r5) tem as medianas 2 e 4 pertencentes apenas à solução r5, e as medianas 1 e 5 pertencentes apenas à solução r1. -
Podemos gerar um número aleatório entre 0 e 2 que define quais serão as medianas que devem ser trocadas: 0,54 indica que trocaremos as medianas 2 e 1 entre os indivíduos r1 e r5, gerando os filhos r2 e r3. -

O segundo par de indivíduos (r4 e r3) tem as medianas 2 e 3 pertencentes apenas à solução r4, e as medianas 1 e 4 pertencentes apenas à solução r3. -
Podemos gerar um número aleatório entre 0 e 2 que define quais serão as medianas que devem ser trocadas: 1,3 indica que trocaremos as medianas 3 e 4 entre os indivíduos r4 e r3, gerando os filhos r4 e r5. -

Podemos sortear um número n1 que define quando será feita a mutação. No caso do indivíduo r2, temos n1 > 0,5, n2 = 0,21 (primeira posição) e n3 = 3,2 (mediana 4). Logo, o indivíduo r2 tem a primeira mediana trocada por 4. -

No caso do indivíduo r3, temos n1 > 0,5, n2 = 1,3 (segunda posição) e n3 = 1,61 (mediana 2). Logo, o indivíduo r3 tem a segunda mediana trocada por 2. Podemos manter o melhor indivíduo e substituir os outros 4 da população para começar a próxima iteração. -

Encontramos os valores dos fitness dos novos indivíduos e as respectivas probabilidades de escolhas para usarmos na roleta: pj. -
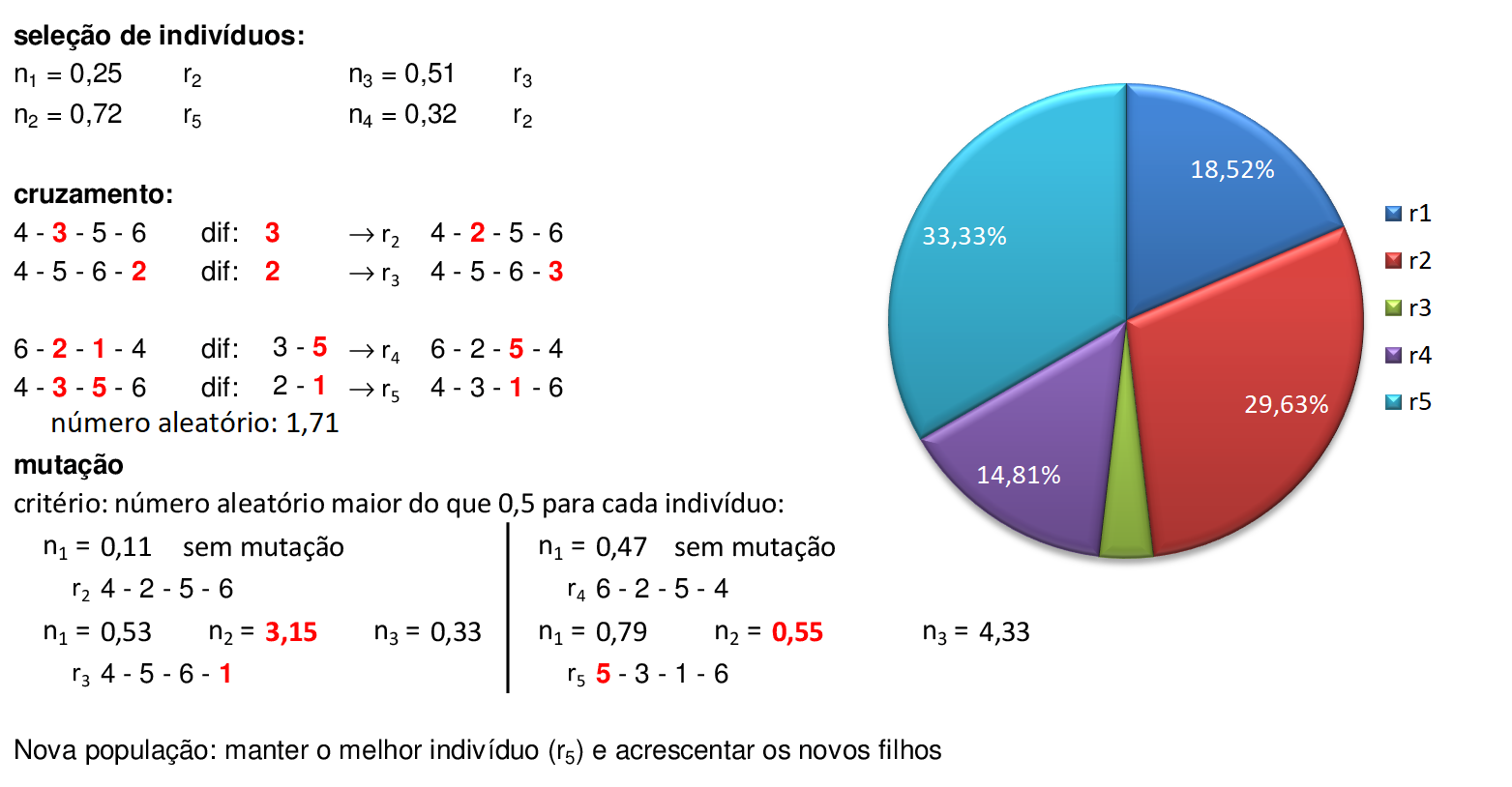
Selecionamos os indivíduos por meio de 4 números aleatórios, e criamos os pontos de cruzamentos. Trocamos os materiais genéticos dos indivíduos escolhidos, fazendo as trocas de medianas e depois as mutações nos novos indivíduos. O processo continua até que um critério de parada seja satisfeito (solução máxima encontrada ou número máximo de iterações).

14. Evolução Diferencial e Busca Local
Material da página 117 até a página 127.


📃 Algoritmo comentado
Crie uma população inicial com n soluções. Defina a função fitness f.
Faça iteração = 0, defina os valores de PCR e F.
Repita
Para cada indivíduo i da população, faça:
Defina os números inteiros aleatórios r1, r2, r3 ∈ [1, n], onde r1 ≠ r2 ≠ r3 ≠ i.
Para cada j ∈ [1, m], faça:
ui,j = xr1,j + F*(xr2,j - xr3,j) (vetor teste)
Defina o número aleatório sj ∈ [0, 1].
Se sj ≤ PCR, então
x'i,j = ui,j
Caso contrário
x'i,j = xi,j
Fim
Fim
Se f(x'i,j) < f(xi,j), então
xi,j = x'i,j
Fim
Fim
iteração = iteração + 1
Enquanto o critério de parada não for satisfeito
Retorne o melhor vetor da população
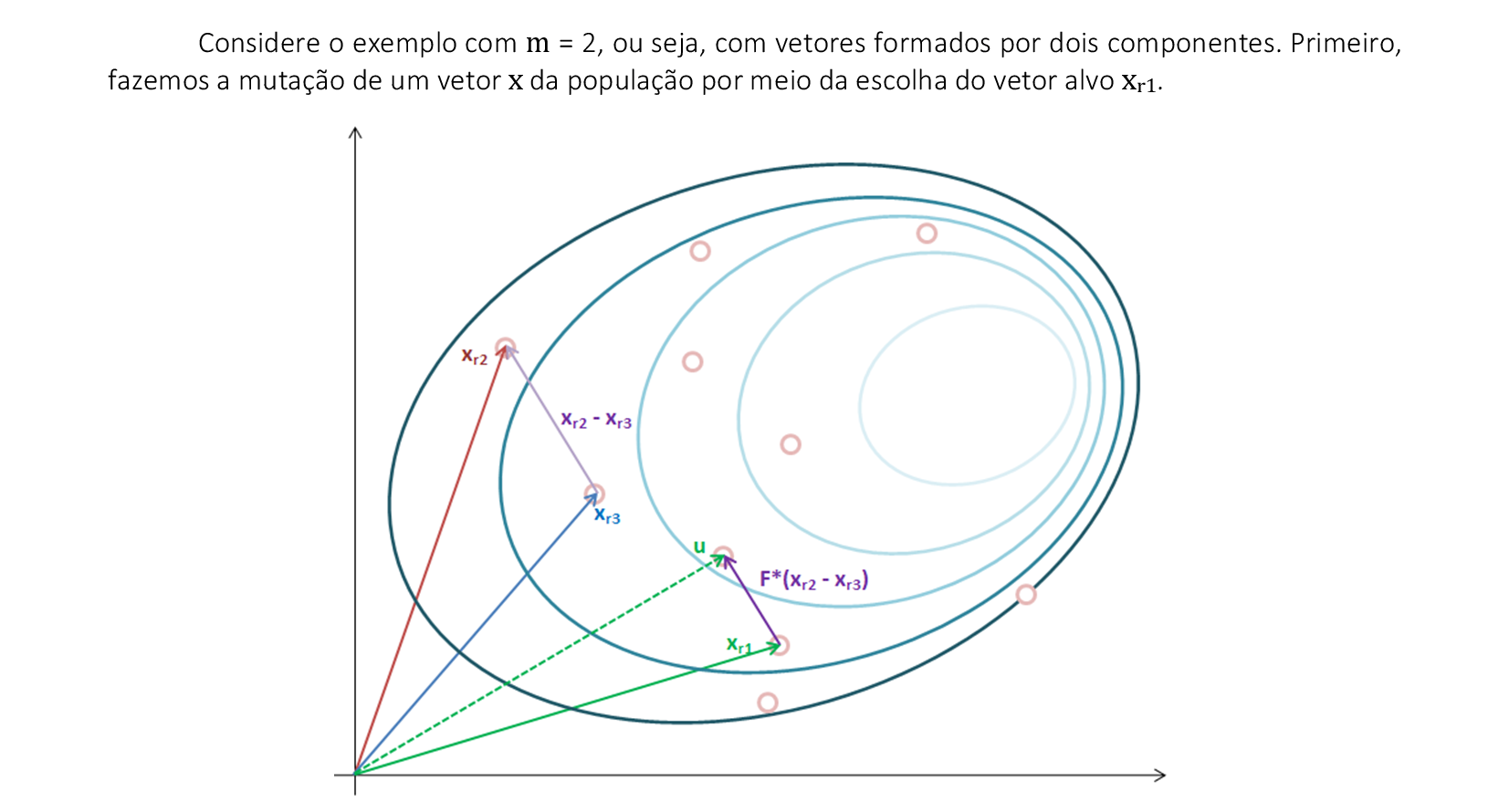


📃 Algoritmo comentado
Crie uma população inicial com n soluções. Defina a função fitness f.
Faça iteração = 0, defina os valores de PCR e F.
Repita
Para cada indivíduo i da população, faça:
Defina os números inteiros aleatórios r1, r2 ∈ [1, n], onde r1 ≠ r2 ≠ i.
Selecione o índice k do melhor indivíduo da população atual (xbest = k).
Para cada j ∈ [1, m], faça:
ui,j = xk,j + F*(xr1,j - xr2,j) (vetor teste)
Defina o número aleatório sj ∈ [0, 1].
Se sj ≤ PCR, então
x'i,j = ui,j
Caso contrário
x'i,j = xi,j
Fim
Fim
Se f(x'i,j) < f(xi,j), então
xi,j = x'i,j
Fim
Fim
iteração = iteração + 1
Enquanto o critério de parada não for satisfeito
Retorne o melhor vetor da população

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Evolução Diferencial para encontrar o valor mínimo da função f(x,y) com uma população de 6 indivíduos. Utilizaremos vetor alvo aleatório, fator de escala F = 0,5 e taxa de crossover PCR = 0,7.
-

Para o indivíduo 1, definimos os índices r1 = 2, r2 = 3 e r3 = 6 para o cálculo do vetor teste u da mutação. -
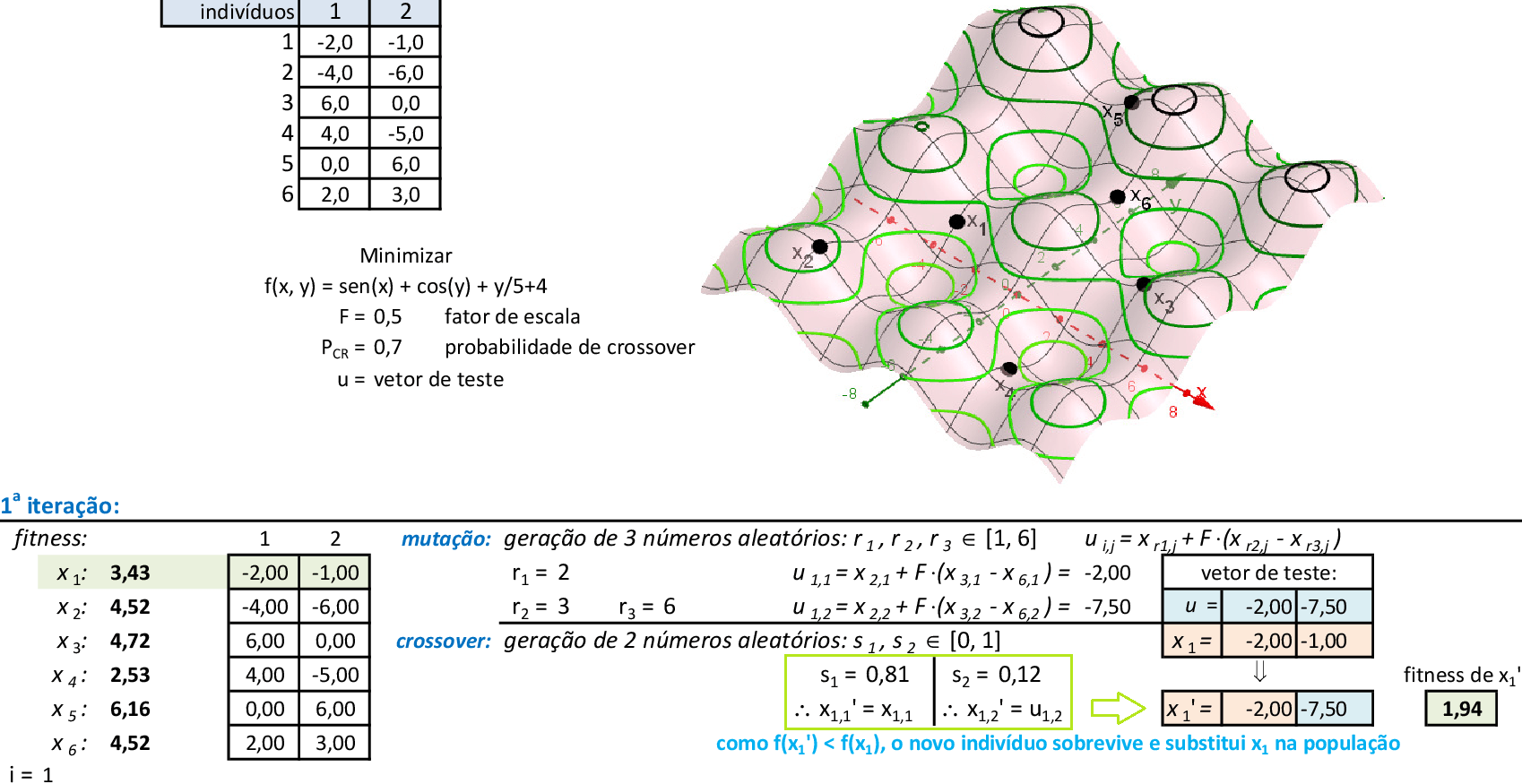
No crossover, os números aleatórios s1 e s2 definem as coordenadas do novo indivíduo x'1, com a primeira coordenada do vetor x1 e a segunda coordenada do vetor teste u. Como o novo indivíduo é melhor do que x1, substituímos x1 por x'1. -

Para o indivíduo 2, definimos os índices r1, r2 e r3 e fazemos a mutação e o crossover da mesma maneira usada para o indivíduo 1. O novo indivíduo sobrevive e substitui o indivíduo 2 na população. -

Para os indivíduos 3 e 4, definimos os índices r1, r2 e r3 e fazemos as mutações e os crossovers da mesma maneira usada para os indivíduos anteriores. Os novos indivíduos sobrevivem e substituem os indivíduos 3 e 4 na população. -
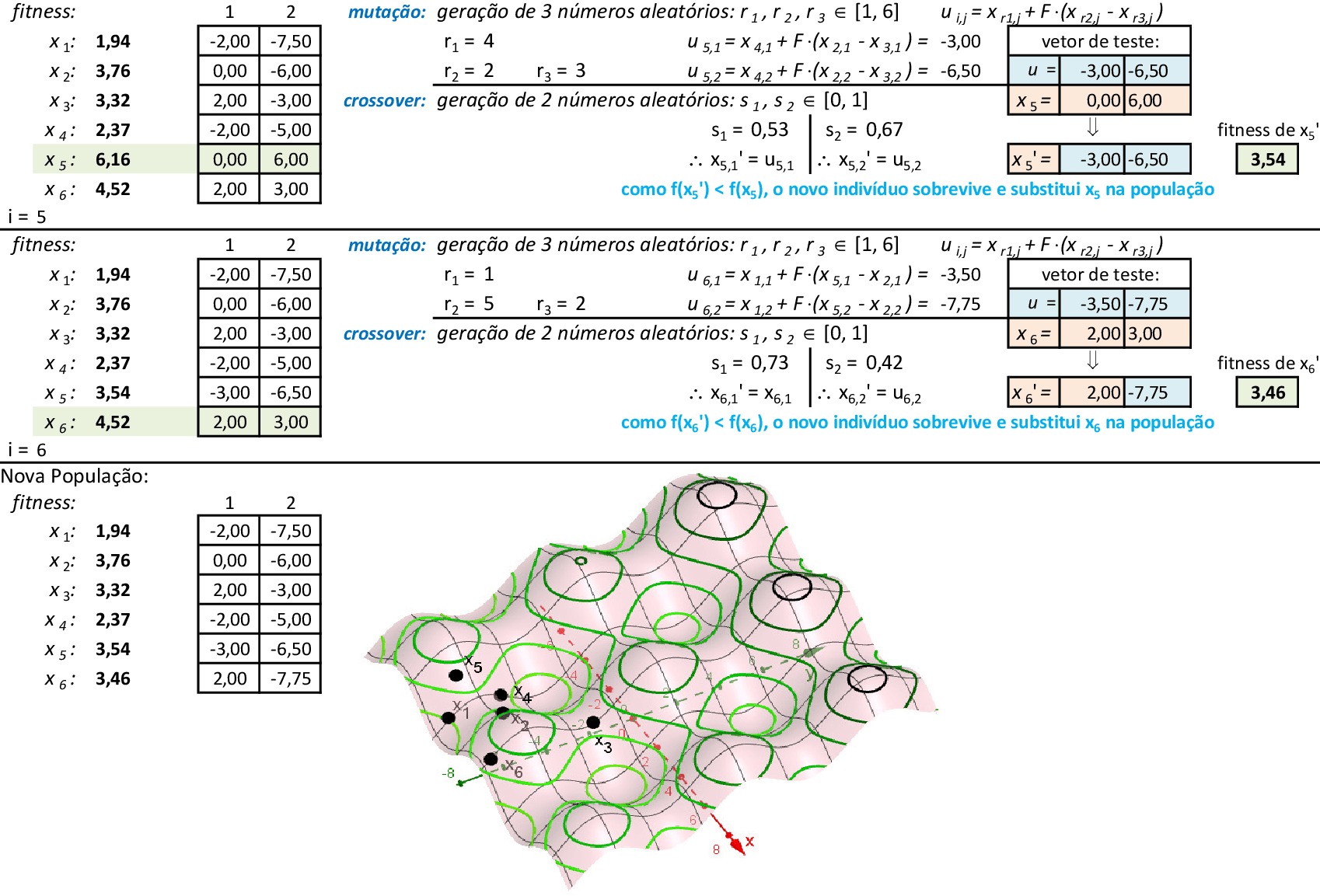
Para os indivíduos 5 e 6, definimos os índices r1, r2 e r3 e fazemos as mutações e os crossovers da mesma maneira usada para os indivíduos anteriores. Os novos indivíduos sobrevivem e substituem os indivíduos 5 e 6 na população. -

No final da 1ª iteração, temos a nova população criada, que será usada para começarmos a próxima iteração. A melhor solução encontrada nesta iteração é do vetor x1 com fitness f(x,y) = 1,94. -

Na 2ª iteração, seguimos os mesmos passos do algoritmo para a mutação e o crossover de cada indivíduo. Note que os novos indivíduos criados a partir dos indivíduos 1 e 3 têm fitness piores do que os indivíduos originais. -

Os novos indivíduos criados a partir dos indivíduos 4 e 6 substituem os indivíduos originais. -
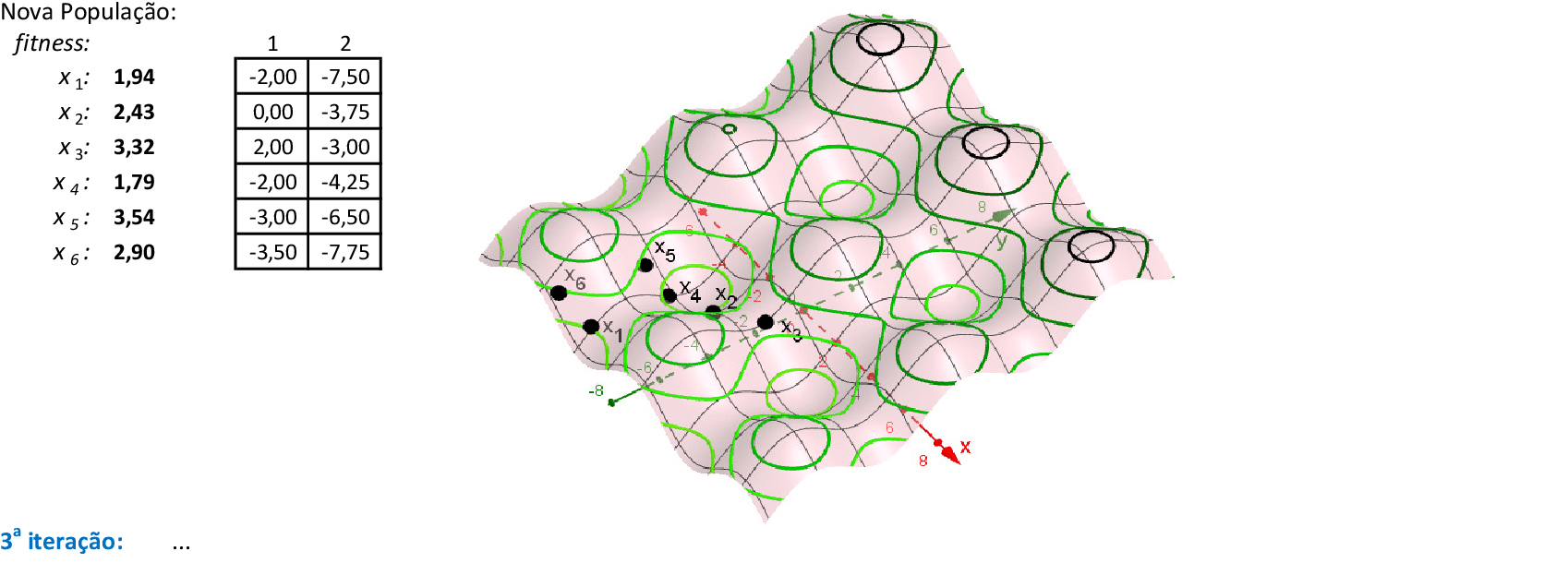
No final da 2ª iteração, temos a nova população criada, que será usada para começarmos a próxima iteração. A melhor solução encontrada nesta iteração é do vetor x4 com fitness f(x,y) = 1,79. As próximas iterações seguem o mesmo raciocínio mostrado nestas 2 primeiras iterações.

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação de Evolução Diferencial para encontrar o valor mínimo da função f(x,y) com uma população de 6 indivíduos. Utilizaremos o melhor vetor alvo da população xbest, o fator de escala F = 0,5 e a taxa de crossover PCR = 0,7.
-

Para o indivíduo 1, definimos os índices r1 = 3 e r2 = 6 para o cálculo do vetor teste u da mutação. O vetor alvo é xbest = 4. -

No crossover, os números aleatórios s1 e s2 definem as coordenadas do novo indivíduo x'1, com a primeira coordenada do vetor x1 e a segunda coordenada do vetor teste u. Como o novo indivíduo é melhor do que x1, substituímos x1 por x'1. -

Para o indivíduo 2, definimos os índices r1 e r2 e fazemos a mutação e o crossover da mesma maneira usada para o indivíduo 1. O novo indivíduo sobrevive e substitui o indivíduo 2 na população. -

Para os indivíduos 3 e 4, definimos os índices r1 e r2 e fazemos as mutações e os crossovers da mesma maneira usada para os indivíduos anteriores. Os novos indivíduos sobrevivem e substituem os indivíduos 3 e 4 na população. -
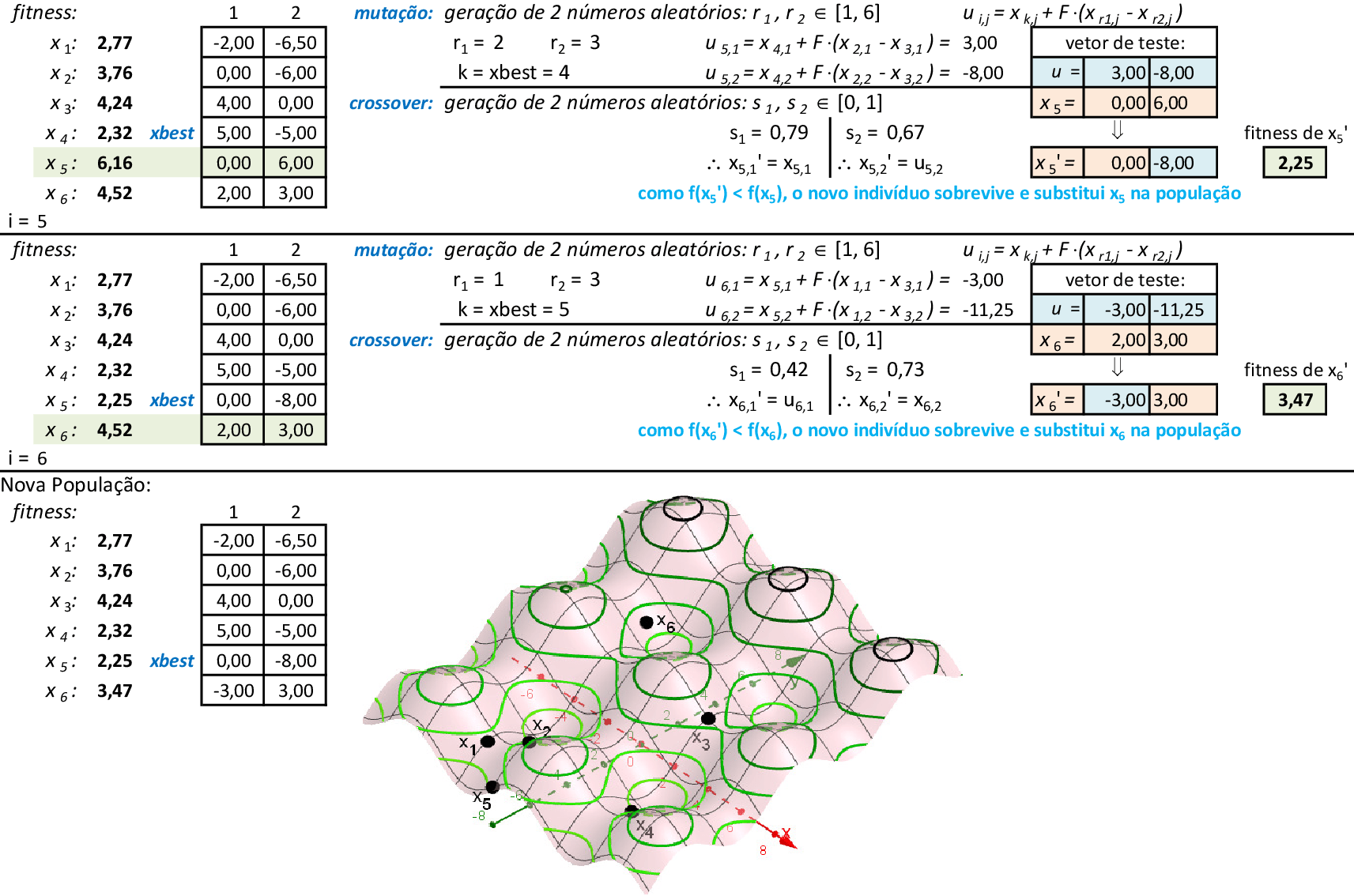
Para os indivíduos 5 e 6, definimos os índices r1 e r2 e fazemos as mutações e os crossovers da mesma maneira usada para os indivíduos anteriores. Os novos indivíduos sobrevivem e substituem os indivíduos 5 e 6 na população. Note que o melhor indivíduo da população agora é o 5. -
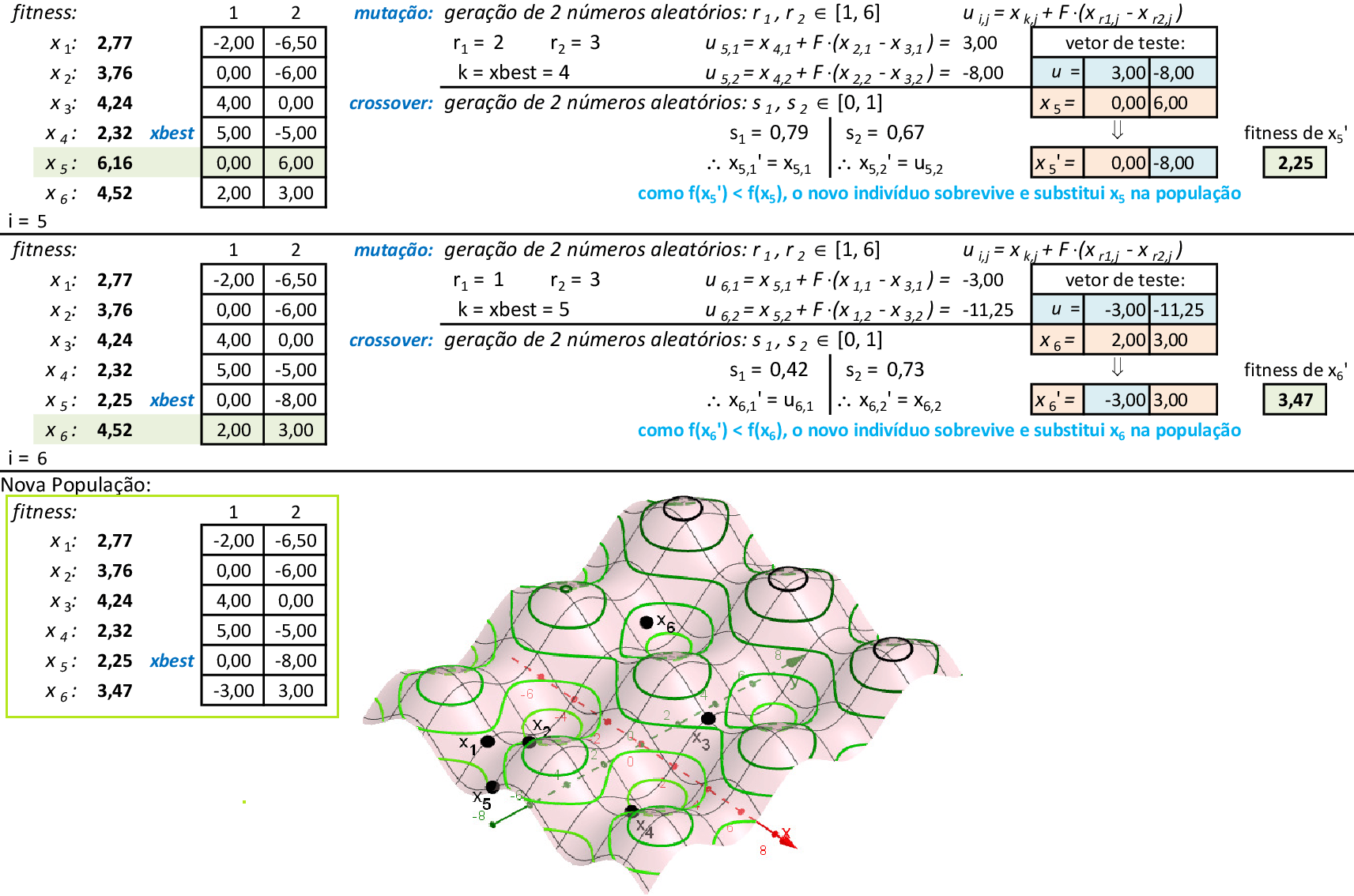
No final da 1ª iteração, temos a nova população criada, que será usada para começarmos a próxima iteração. A melhor solução encontrada nesta iteração é do vetor x5 com fitness f(x,y) = 2,25. -

Na 2ª iteração, seguimos os mesmos passos do algoritmo para a mutação e o crossover de cada indivíduo. Note que os novos indivíduos criados a partir dos indivíduos 1 e 3 têm fitness piores do que os indivíduos originais. -

Os novos indivíduos criados a partir dos indivíduos 4 e 6 substituem os indivíduos originais. O melhor indivíduo da população é o 4. -
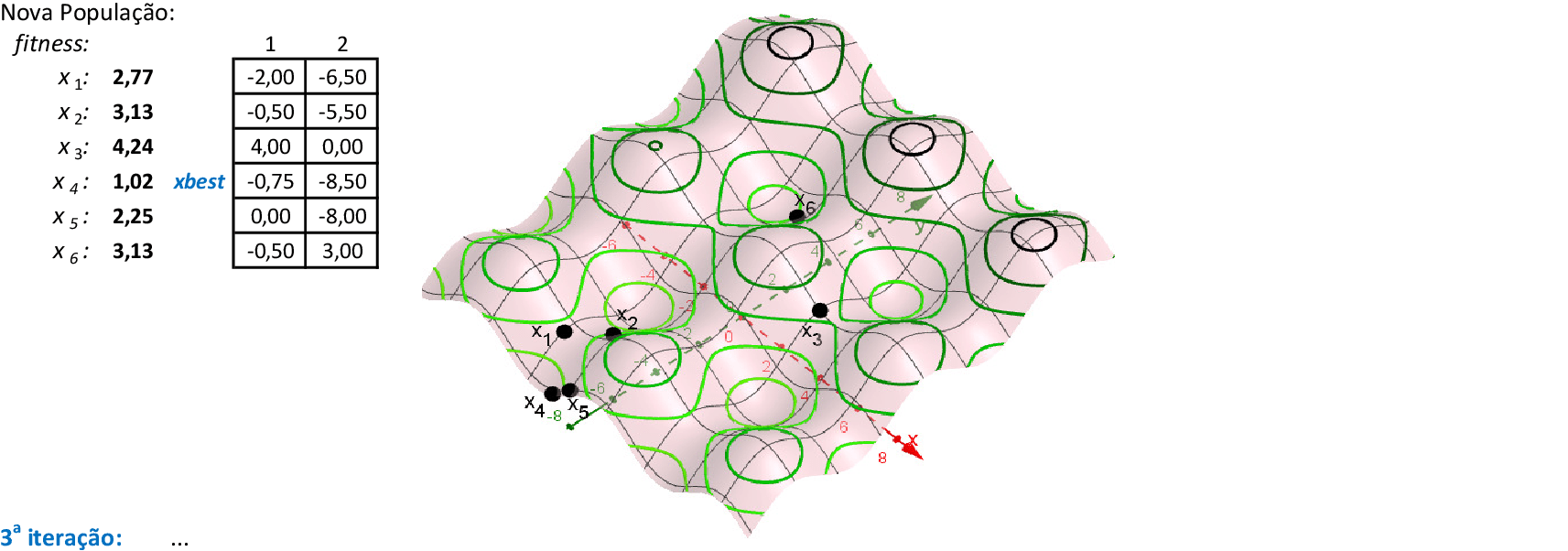
No final da 2ª iteração, temos a nova população criada, que será usada para começarmos a próxima iteração. A melhor solução encontrada nesta iteração é do vetor x4 com fitness f(x,y) = 1,02. As próximas iterações seguem o mesmo raciocínio mostrado nestas 2 primeiras iterações.




📃 Algoritmo comentado
Defina os parâmetros da Rede Neural Recorrente de Wang, o número máximo de soluções
rmax, r = 0 e v(i) = 0 (i = 1, 2, ..., n).
Repita
Repita
Encontre uma solução x para o problema da Designação usando a Rede de Wang
Enquanto Wx(t) − θ > Φ
Faça x’ = x e m = 1.
Repita
Escolha uma linha k da matriz x’ tal que v(k) = 0.
Encontre l tal que x’k,l = maxk,i{x’k,i}, i = 1, 2, ..., n.
x’k,l = x’k,l + ½(∑i=1n xi,l + ∑j=1n xk,j).
x’k,j = 0, para j = 1, 2, ... n, j ≠ l.
x’i,l = 0, para i = 1, 2, ... n, i ≠ k.
Faça v(k) = 1 e m = m + 1.
Enquanto m ≤ n
Faça r = r + 1.
Determine o custo C da solução.
Se C < Cmin, então
Cmin = C e xmin = x’.
Fim
Enquanto r < rmax
Retorne o melhor vetor solução xmin.

📃 Algoritmo comentado
Defina os parâmetros da Rede Neural Recorrente de Wang, o número máximo de soluções
rmax, r = 0 e x''(i) = 0 (i = 1, 2, ..., n + 1).
Repita
Repita
Encontre uma solução x para o problema da Designação usando a Rede de Wang
Enquanto Wx(t) − θ > Φ
Faça x’ = x e m = 1.
Escolha uma linha k da matriz x’, faça x''(1) = k e p = k.
Repita
Encontre l tal que x’k,l = maxk,i{x’k,i}, i = 1, 2, ..., n.
x’k,l = x’k,l + ½(∑i=1n xi,l + ∑j=1n xk,j).
x’k,j = 0, para j = 1, 2, ... n, j ≠ l.
x’i,l = 0, para i = 1, 2, ... n, i ≠ k.
Faça x''(m + 1) = l, m = m + 1 e k = l (para prosseguir a rota).
Enquanto m < n
x’k,p = x’k,p + ½(∑i=1n xi,p + ∑j=1n xk,j).
Faça x''(n + 1) = p (fechamento da rota).
Faça r = r + 1.
Determine o custo C da solução.
Se C < Cmin, então
Cmin = C e xmin = x’.
Fim
Enquanto r < rmax
Retorne o melhor vetor solução xmin.


📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Rede Neural de Wang com o algoritmo Winner Takes All para encontrar uma solução para o problema da Designação Linear com o número de vértices n = 5.
-
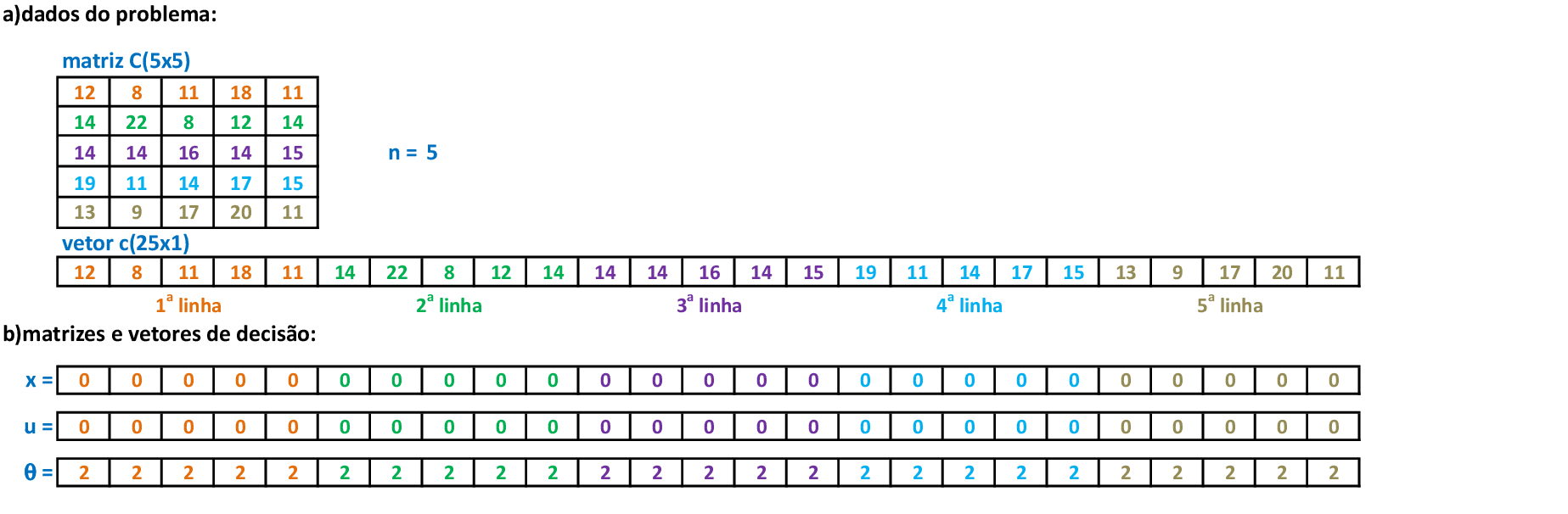
Começamos com a tranformação da matriz de custos C(n x n) em um vetor c(n²) com a sequência de linhas da matriz C. Usando a mesma lógica, definimos os vetores x (valores de decisão), u e θ (bias). -

Nesta RNA a matriz de pesos W é fixa, composta por matrizes identidade e matrizes D = I + 1, onde a matriz 1 contém o número 1 em todas as posições. Os parâmetros da RNA são definidos, de acordo com o algoritmo apresentado anteriormente (considerando D como o desvio padrão da matriz de custos, τ e λ fixos). -

Em cada iteração da RNA, temos o cálculo do erro (Wx − θ)/n² que mede a violação das restrições do problema da Designação. -
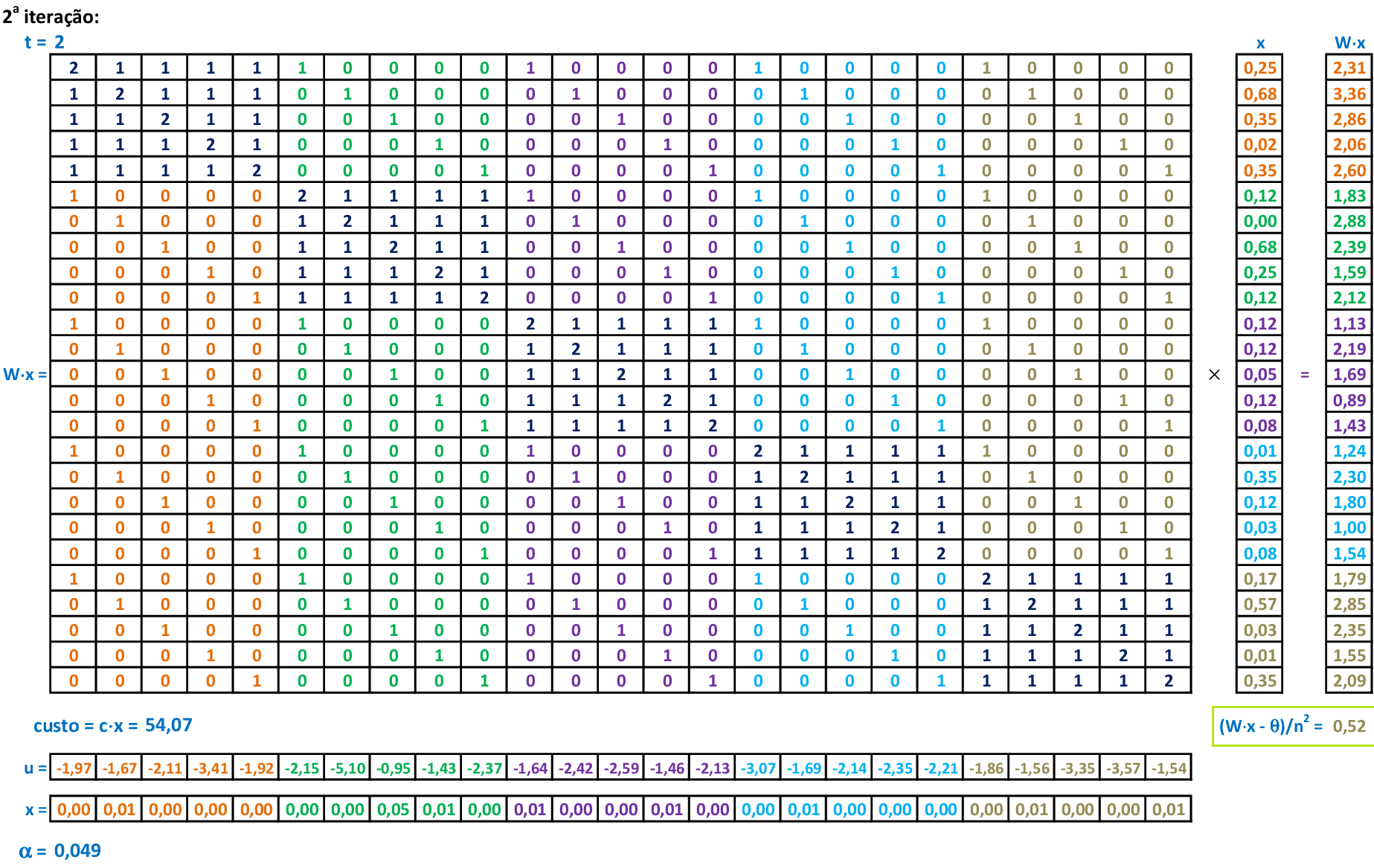
Na 2ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,52. -

Na 3ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 1,94. -

Na 4ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 1,73. -

Na 12ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,15. -

Na 13ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,04 ≤ Φ. Neste momento, podemos utilizar o algoritmo Winner Takes All para definir os valores das variáveis de decisão do problema. -

Podemos colocar os valores das variáveis de decisão na forma matricial. Escolhendo a linha k = 4, temos que o maior elemento desta linha é x4,2 = 0,508. Logo, este neurônio receberá a metade da soma de todos os elementos da linha 4 e da coluna 2 da matriz de decisão x. Os demais elementos tornam-se nulos. -
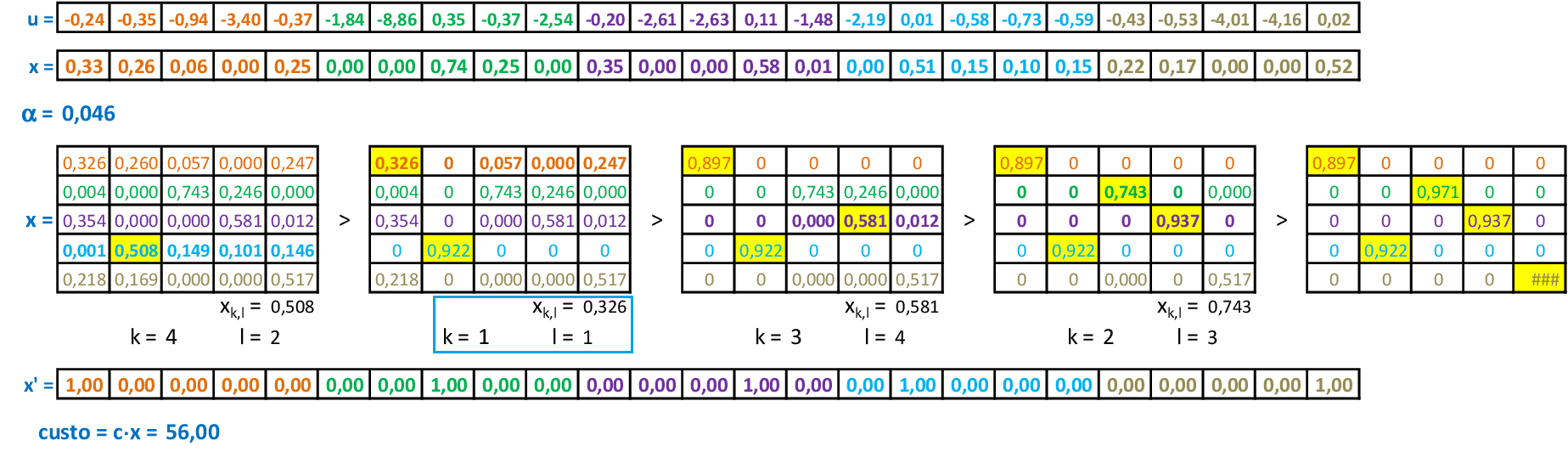
Escolhendo a linha k = 1, temos que o maior elemento desta linha é x1,1 = 0,326. Logo, este neurônio receberá a metade da soma de todos os elementos da linha 1 e da coluna 1 da matriz de decisão x. Os demais elementos tornam-se nulos. -

Escolhendo a linha k = 3, temos que o maior elemento desta linha é x3,4 = 0,581. Logo, este neurônio receberá a metade da soma de todos os elementos da linha 3 e da coluna 4 da matriz de decisão x. Os demais elementos tornam-se nulos. Prosseguindo com o algoritmo, temos a matriz de decisão definida, com custo correspondente de 56 (solução ótima global deste problema). -

Utilizamos o vetor x' para a próxima iteração da RNA. Com os parâmetros da RNA, utilizamos o algoritmo Winner Takes All novamente para encontrar uma nova solução do problema da Designação. -

Com o algoritmo apresentado, temos novamente a solução ótima encontrada. O algoritmo prossegue até encontrar um número máximo de soluções definido.

📃 Resolução
Vamos acompanhar os cálculos deste exercício da aplicação da Rede Neural de Wang com o algoritmo Winner Takes All para encontrar uma solução para o problema do Caixeiro Viajante com o número de vértices n = 5.
-

Começamos com a tranformação da matriz de custos C(n x n) em um vetor c(n²) com a sequência de linhas da matriz C. Usando a mesma lógica, definimos os vetores x (valores de decisão), u e θ (bias). -
Nesta RNA a matriz de pesos W é fixa, composta por matrizes identidade e matrizes D = I + 1, onde a matriz 1 contém o número 1 em todas as posições. Os parâmetros da RNA são definidos, de acordo com o algoritmo apresentado anteriormente (considerando os desvios padrão das linhas da matriz de custos para definir τ e λ). -

Em cada iteração da RNA, temos o cálculo do erro (Wx − θ)/n² que mede a violação das restrições do problema da Designação. -

Na 2ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 3,68. -

Na 3ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 1,81. -

Na 4ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,94. -

Na 8ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,07. -

Na 9ª iteração, temos os vetores atualizados e o erro (Wx − θ)/n² = 0,02 ≤ Φ. Neste momento, podemos utilizar o algoritmo Winner Takes All para definir os valores das variáveis de decisão do problema. -

Podemos colocar os valores das variáveis de decisão na forma matricial. Escolhendo a linha k = 4, temos que o maior elemento desta linha é x4,5 = 0,249. Logo, este neurônio receberá a metade da soma de todos os elementos da linha 4 e da coluna 5 da matriz de decisão x. Os demais elementos tornam-se nulos. A sequência da rota fica x'' = (4 - 5 - ...). -
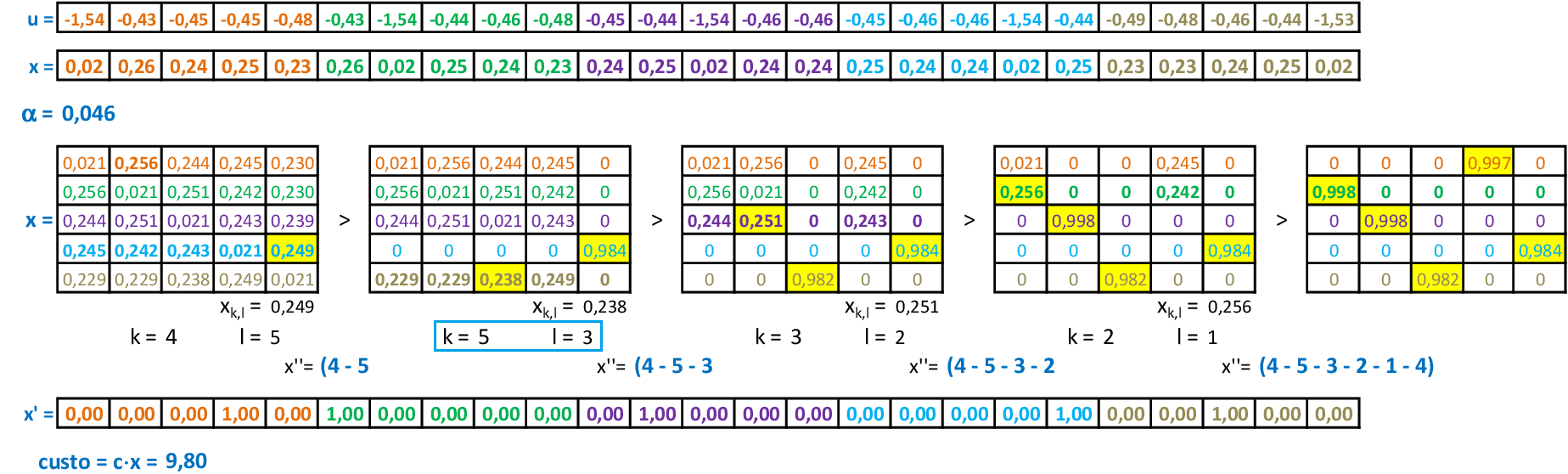
Prosseguindo com a rota, temos k = 5, e o segundo maior elemento desta linha é x5,3 = 0,238 (note que neste caso de empate com a designação anterior do arco 5 - 4, precisamos definir o segundo maior elemento; se escolhermos o arco 5 - 4 teremos um ciclo e a solução do PCV fica infactível). Logo, este neurônio receberá a metade da soma de todos os elementos da linha 5 e da coluna 3 da matriz de decisão x. Os demais elementos tornam-se nulos. A sequência da rota fica x'' = (4 - 5 - 3 -...). -
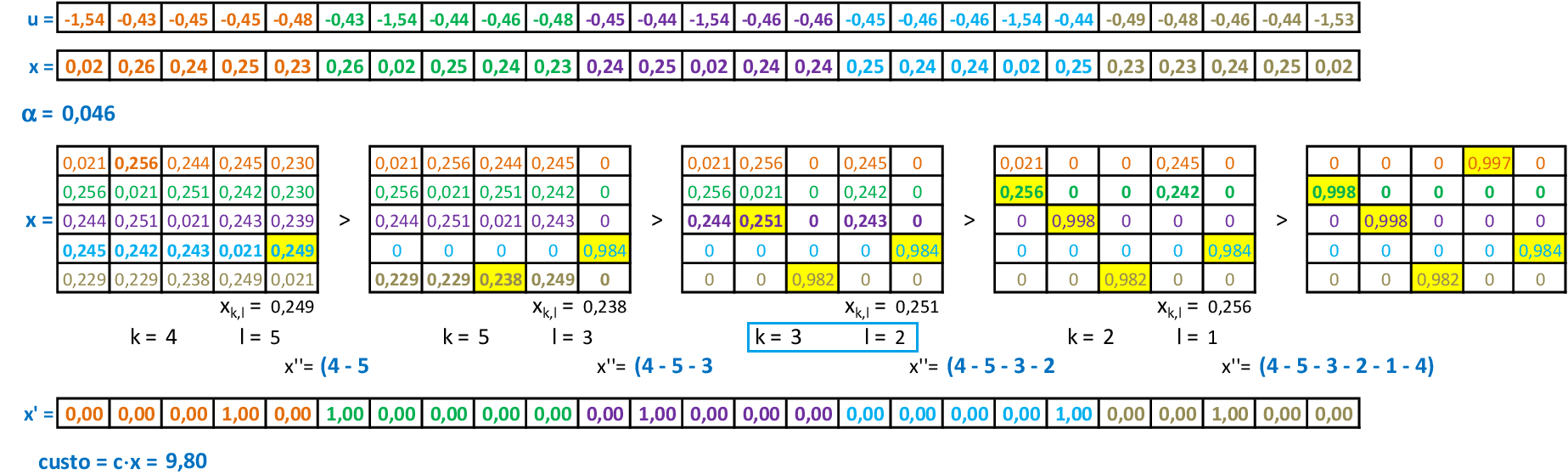
Prosseguindo com a rota, temos k = 3, e o maior elemento desta linha é x3,2 = 0,251. Logo, este neurônio receberá a metade da soma de todos os elementos da linha 3 e da coluna 2 da matriz de decisão x. Os demais elementos tornam-se nulos. A sequência da rota fica x'' = (4 - 5 - 3 - 2 - ...). Prosseguindo com o algoritmo, temos a matriz de decisão definida, com custo correspondente de 9,8 (solução ótima global deste problema). -

Utilizamos o vetor x' para a próxima iteração da RNA. Com os parâmetros da RNA, utilizamos o algoritmo Winner Takes All novamente para encontrar uma nova solução do problema da Designação. -
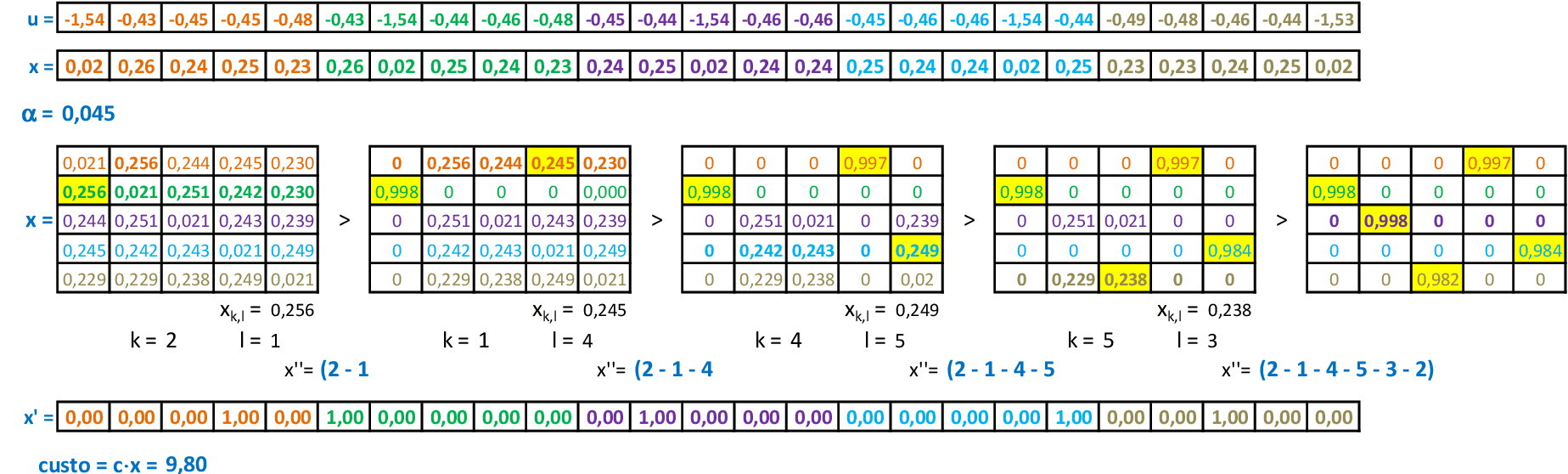
Com o algoritmo apresentado, temos novamente a solução ótima encontrada. O algoritmo prossegue até encontrar um número máximo de soluções definido.
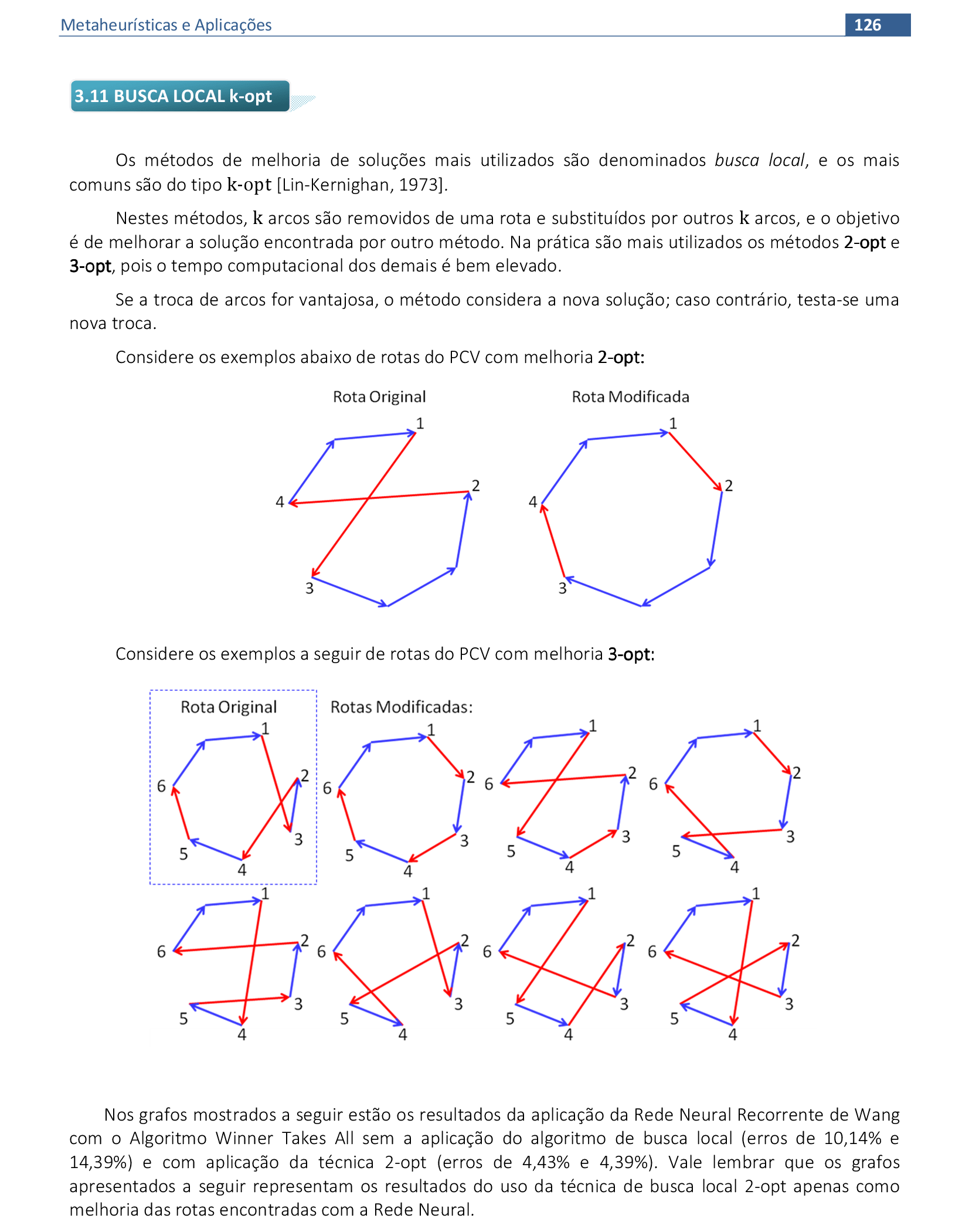

página desenvolvida por:
Paulo Henrique Siqueira
contato: paulohscwb@gmail.com
O desenvolvimento deste material faz parte do Grupo de Estudos em Expressão Gráfica (GEEGRAF) da Universidade Federal do Paraná (UFPR)

Metaheurísticas e Aplicações de Paulo Henrique Siqueira está licenciado com uma Licença Creative Commons Atribuição-NãoComercial-SemDerivações 4.0 Internacional.
Como citar este trabalho:
Siqueira, P.H., "Metaheurísticas e Aplicações". Disponível em: <https://paulohscwb.github.io/metaheuristicas/>, Janeiro de 2021.
![]()
Referências:
- FAUSETT, L. Fundamentals of Neural Networks. Prentice Hall, 1994.
- HAYKIN, S. Neural Networks – A Compreensive Foundation. Macmillan College Publishing, 1994.
- KOHONEN, T. Self-Organizing Maps. Springer, 1995.
- SILVA, I.N.; SPATTI, D.H.; FLAUZINO, R.A. Redes Neurais Artificiais para engenharia e ciências aplicadas. Artliber, 2010.
- TAFNER, M.A.; XEREZ, M.; RODRÍGUEZ FILHO, I.W. Redes Neurais Artificiais: introdução e princípios da neurocomputação. FURB, 1996.
- BOÇOIS, A., OLIVEIRA, A. A., SIQUEIRA, P. H., TELLES, F. Q. Diagnóstico de Doenças Dermatológicas usando a Rede Neural de Kohonen. In: IX Encontro Nacional de Inteligência Artificial (ENIA 2012), 2012, Curitiba. Proceedings Brazilian Conference on Intelligent Systems, v. 1. p. 1-8, 2012.
- SIQUEIRA, P. H., SCHEER, S., STEINER, M. T. A. Application of the Winner Takes All Principle in Wang’s Recurrent Neural Network for the Assignment problem. Lecture Notes in Computer Science, Berlin, v. 3496, n. 1, p. 731-738, 2005.
- SIQUEIRA, P. H., SCHEER, S., STEINER, M. T. A. A new approach to solve the Traveling Salesman Problem. Neurocomputing (Amsterdam), v. 70, p. 1013-1021, 2007.
- SIQUEIRA, P. H., STEINER, M. T. A., SCHEER, S. Recurrent Neural Network with Soft 'Winner Takes All' principle for the TSP. In: ICNC 2010 - International Conference on Neural Computation, 2010, Valencia. Proceedings of the International Conference on Fuzzy Computation and International Conference on Neural Computation, v. 1. p. 265-270, 2010.
- ROSA, C. R. M. ; STEINER, M. T. A. ; STEINER NETO, P. J. Técnicas de Mineração de Dados aplicadas a um Problema de Diagnóstico Médico. Espacios (Caracas), v. 37, p. 1, 2016.
- TEIXEIRA, L. L., TEIXEIRA JUNIOR, L. A., SIQUEIRA, P. H. Previsões de vazões mensais via combinação híbrida ARIMA_NEURAL com encolhimento e decomposição Wavelet. REVISTA DE ENGENHARIA E TECNOLOGIA, v. 7, p. 144-161, 2015.
- DEMUTH, H., BEALE, M. Neural Network Toolbox User's Guide (For Use with MATLAB), The MathWorks, Inc., MA, USA, 1994.
- SOUTO, M. Multi-layer Perceptrons e Backpropagation. DIMAp/UFRN, 2020. Disponível em: <https://slideplayer.com.br/slide/3258057/>
- BENEDIKTSSON, J. A., SWAIN, P. H., ERSOY, O. K. Neural network approaches versus statistical methods in classification of multisource remote sensing data. In: 12th Canadian Symposium on Remote Sensing Geoscience and Remote Sensing Symposium, IEEE, 1989. p. 489-492.
- HEPNER, G., LOGAN, T., RITTER, N., BRYANT, N. Artificial neural network classification using a minimal training set- Comparison to conventional supervised classification. Photogrammetric Engineering and Remote Sensing, v. 56, n. 4, p. 469-473, 1990.
- GORNI, A. A. Redes neurais artificiais - uma abordagem revolucionária em inteligência artificial. São Paulo, Micro Sistemas, 1993.
- KRÖSE, B., KRÖSE, B., SMAGT, P. An introduction to neural networks, 1993.
- BOSER, B. E., GUYON, I. M., VAPNIK, V. N. A training algorithm for optimal margin classifiers. In: Proceedings of the fifth annual workshop on Computational learning theory, p. 144-152, 1992.
- GAHEGAN, M., WEST, G. The classification of complex geographic datasets: An operational comparison of artificial neural network and decision tree classifiers. In: Third International Conference on GeoComputation, p. 17-19, 1998.
- CORTES, C., VAPNIK, V. Support-vector networks. Machine learning, v. 20, n.3, p. 273-297, 1995.
- POWELL, M. J. D. Radial basis functions for multivariate interpolation: a review. In: J.C. Mason, M.G. Cox (Eds.), Algorithms for Approximation, Clarendon Press, Oxford, 1987
- VIEIRA, F. C., DÓRIA NETO, A. D., COSTA, J. A. F. An Efficient Approach to the Travelling Salesman Problem Using Self-Organizing Maps. International Journal of Neural Systems, London, UK, v. 13, n.2, p. 59-66, 2003
- Le COADOU, BENABDESLEM, K. Optimizing local modeling for times series prediction. International Journal of Computational Intelligence Research, v. 2, n. 1, p. 81-85, 2006.
- DORIGO, M.; GARAMBARDELLA, L.M., Ant Colonies for the Traveling Salesman Problem. Biosystems, v. 43, n. 2, p. 73-81, 1997.
- ENGELBRECHT, A. P., Computational Intelligence, John Wiley & Sons, 2007.
- EBERHART, R. C., SHI, Y., Comparison between genetic algorithms and particle swarm optimization, Evolutionary Programming VII: Lecture Notes in Computer Science, vol 1447, p. 611-616, 1998
- LIN, S., KERNIGHAN, B. W. An effective heuristic algorithm for the traveling-salesman problem, Operations research, v. 21, n. 2, p. 498-516, 1973.
- HU, X. PSO Tutorial. Disponível em: http://www.swarmintelligence.org/tutorials.php
- GLOVER, F. Multilevel tabu search and embedded search neighborhoods for the traveling salesman problem. Graduate School of Business, University of Colorado, 1991.
- LOPES, H. S. Algoritmos genéticos em projetos de engenharia: aplicações e perspectivas futuras. Anais do IV Simpósio Brasileiro de Automação Inteligente, p. 64-74, 1999.
- MICHALEWICZ, Z., SCHOENAUER, M. Evolutionary algorithms for constrained parameter optimization problems. Evolutionary computation, v. 4, n. 1, p. 1-32, 1999.
- VAN LAARHOVEN, P. J., AARTS, E. H. Simulated annealing. In Simulated annealing: Theory and applications p. 7-15. Springer, Dordrecht, 1987.
- MITRA, D., ROMEO, F., SANGIOVANNI-VINCENTELLI, A. Convergence and finite-time behavior of simulated annealing. Advances in applied probability, v. 18, n. 3, p. 747-771, 1986.
- KIRKPATRICK, S., GELATT, C. D., VECCHI, M. P. Optimization by simulated annealing. science, v. 220, n. 4598, p. 671-680, 1983.
- ARAGON, C. R., JOHNSON, D. S., McGEOCH, L. A., SCHEVON, C. Optimization by simulated annealing: an experimental evaluation. In: Workshop on Statistical Physics in Engineering and Biology. Yorktown Heights, 1984.
- BOZORG-HADDAD, O., SOLGI, M., LOÁICIGA, H. A. Meta-heuristic and evolutionary algorithms for engineering optimization. Hoboken, John Wiley & Sons, 2017.
- STORN, R., PRICE, K. Differential Evolution - a Simple and Efficient Heuristic for Global Optimization over Continuous Spaces, Journal of Global Optimization, v. 11, p. 341–359, 1997.
- TALBI, E. G. Metaheuristics: from design to implementation (Vol. 74). John Wiley & Sons, 2009.
- WANG, J. Analog Neural Network for Solving the Assignment Problem. Electronic Letters, v. 28, n. 11, p. 1047-1050, 1992.